
2021年Graph ML热门趋势和主要进展总结

来源:DeepHub IMBA 本文约4700字,建议阅读9分钟
本文为你介绍 Graph ML 这一年的进展进行结构化,并重点介绍 🔥 趋势和主要进步。
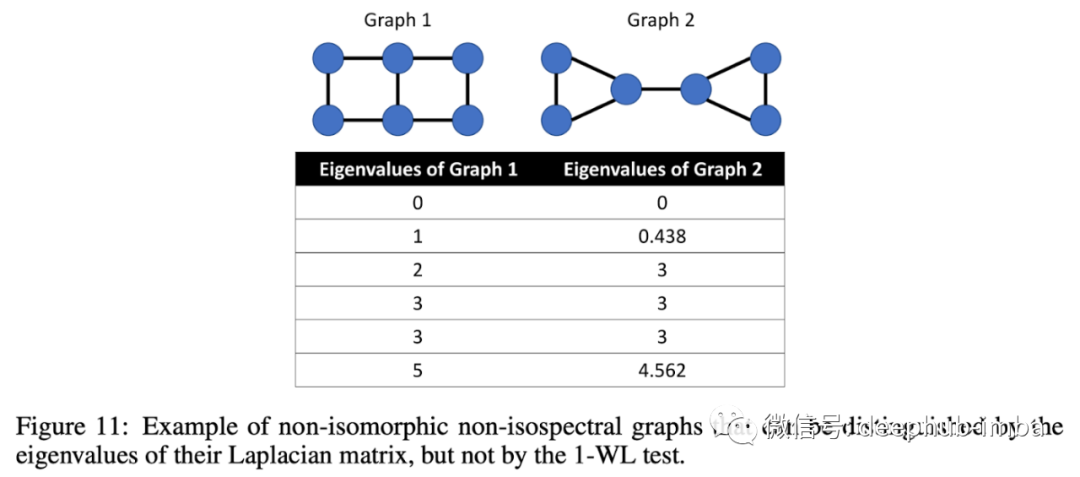
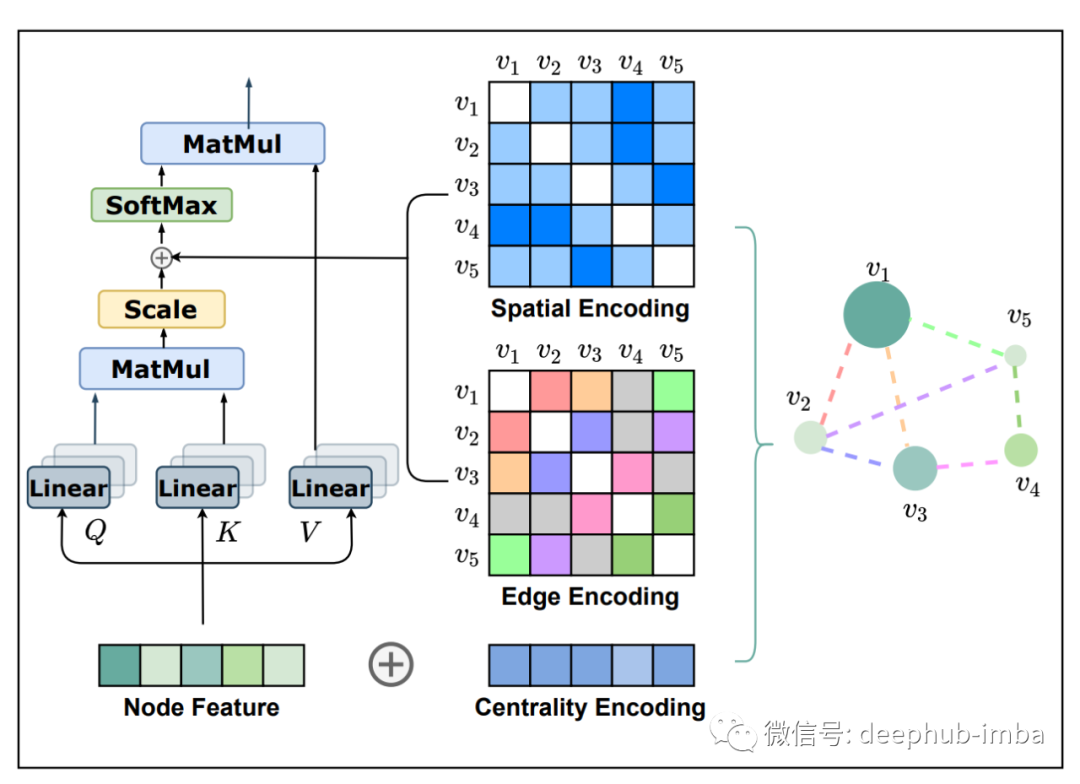
Graph Transformers + Positional Features
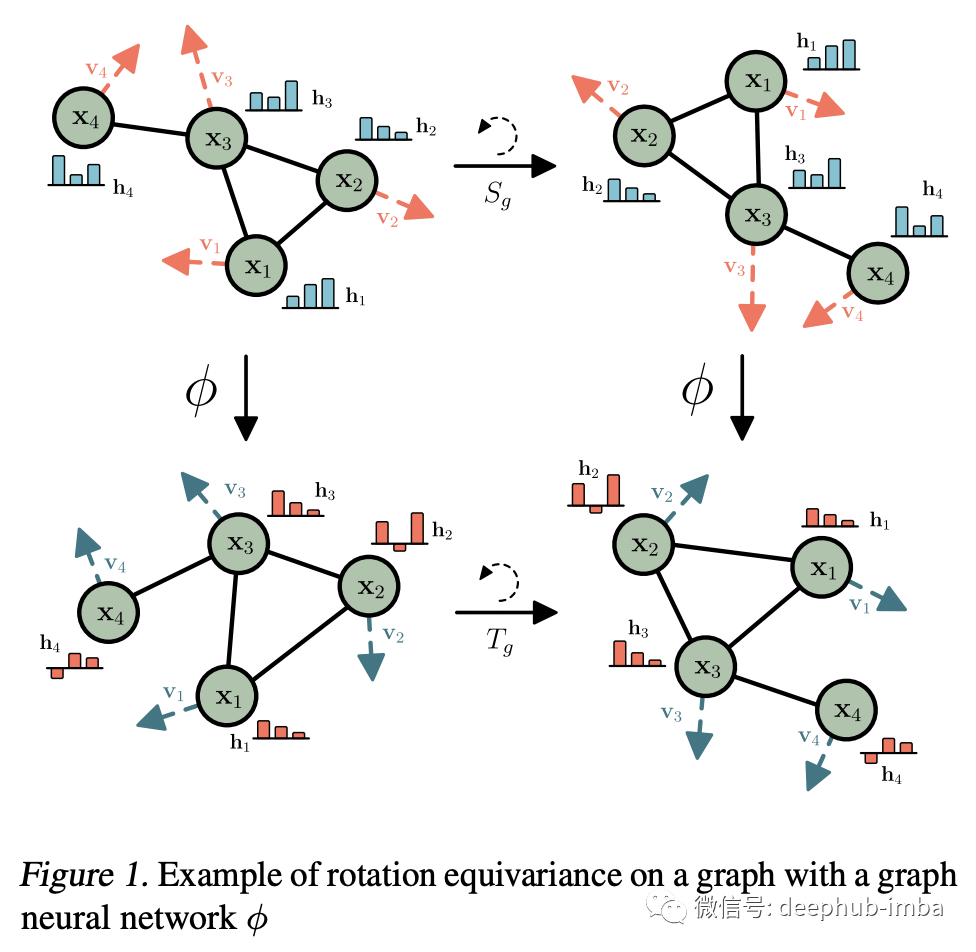
Equivariant GNNs
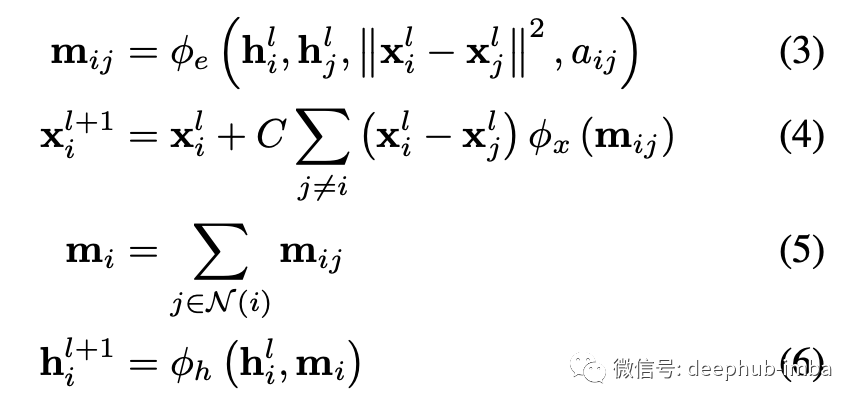
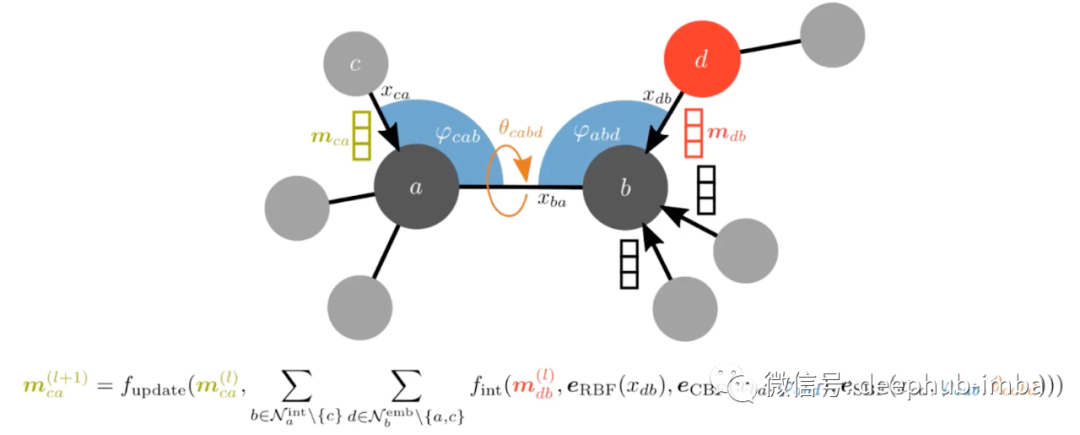
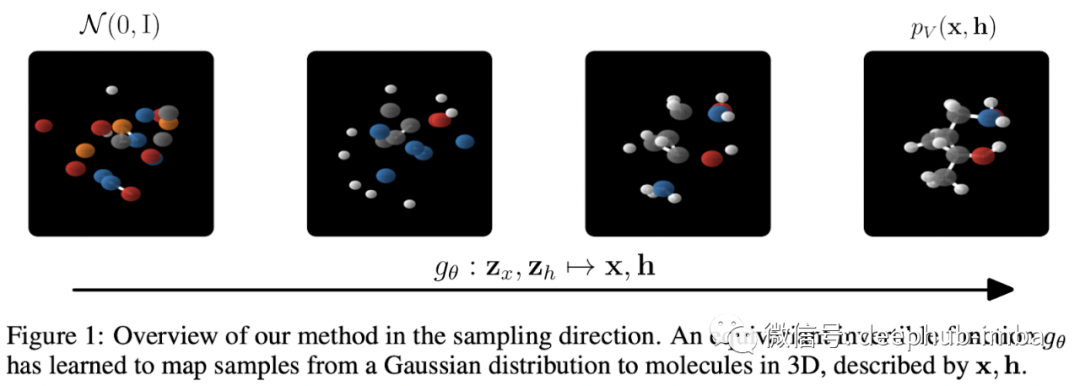
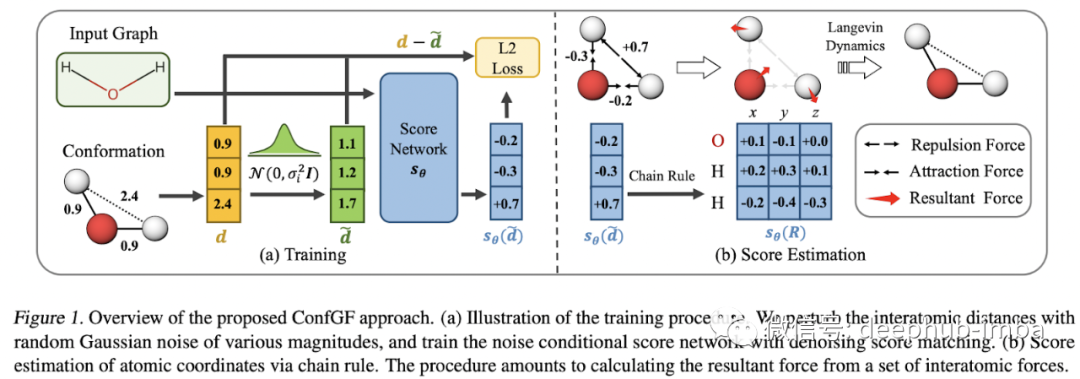
Generative Models for Molecules
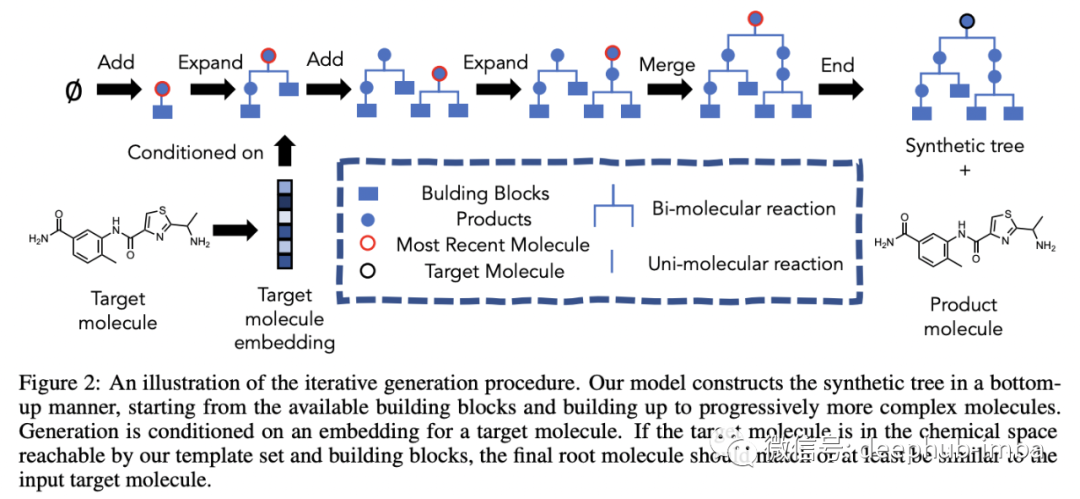
GNNs + Combinatorial Optimization & Algorithms
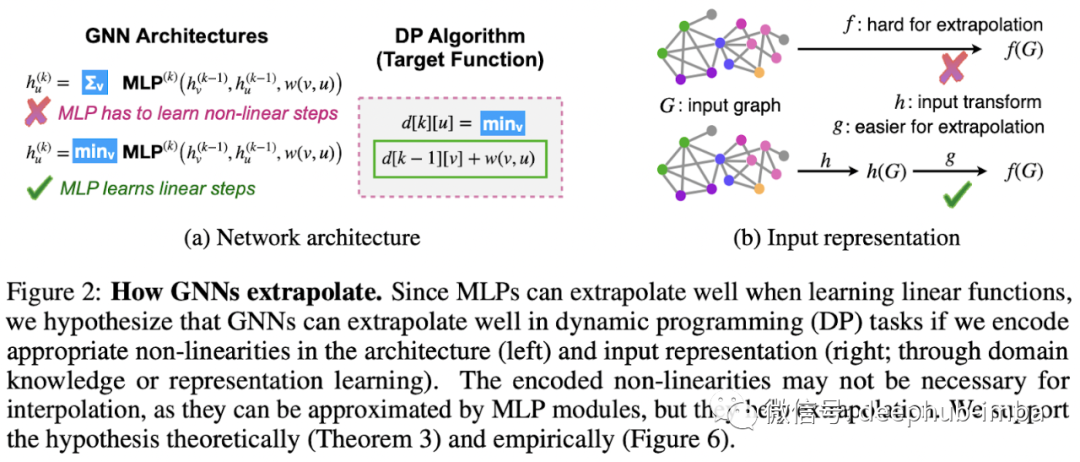
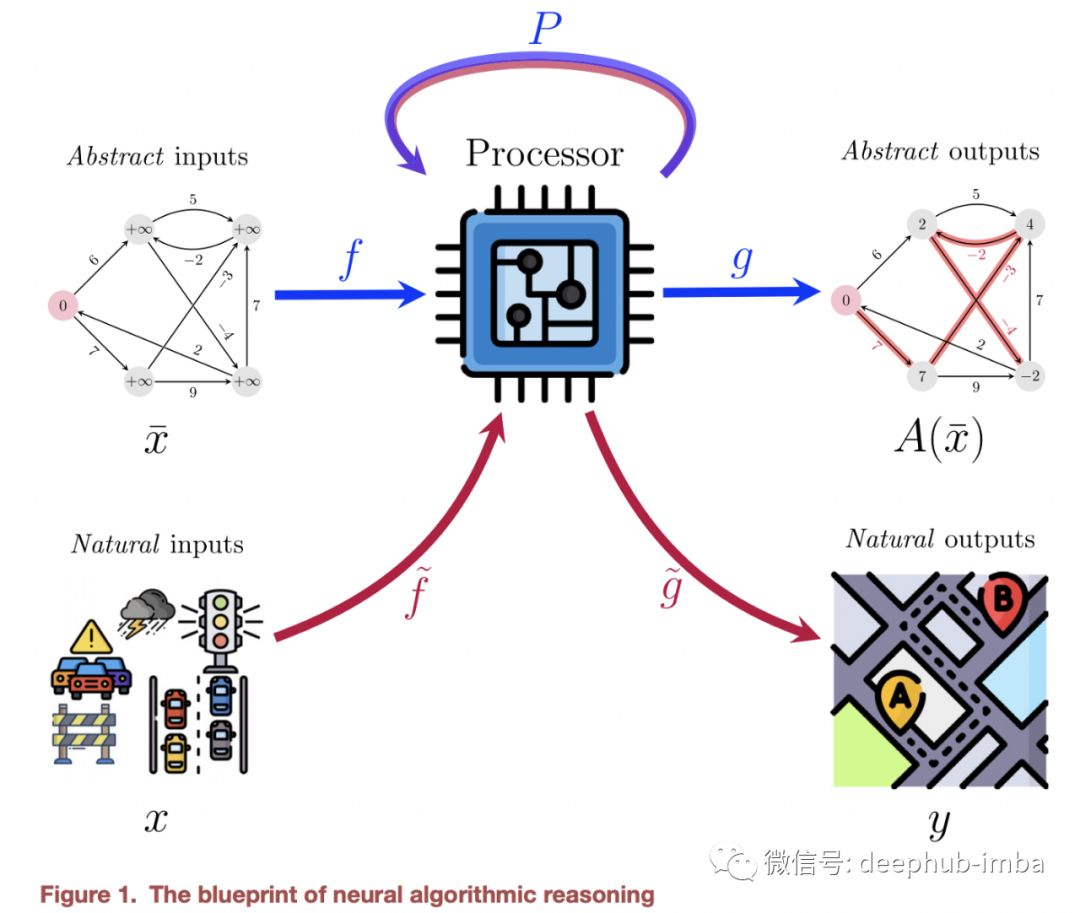
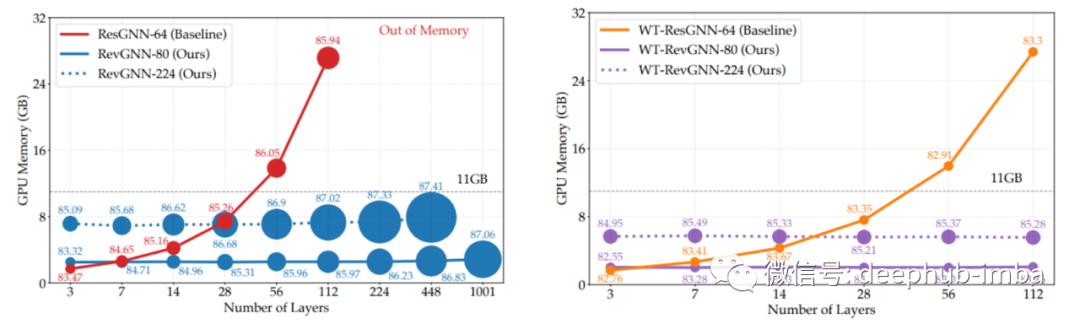
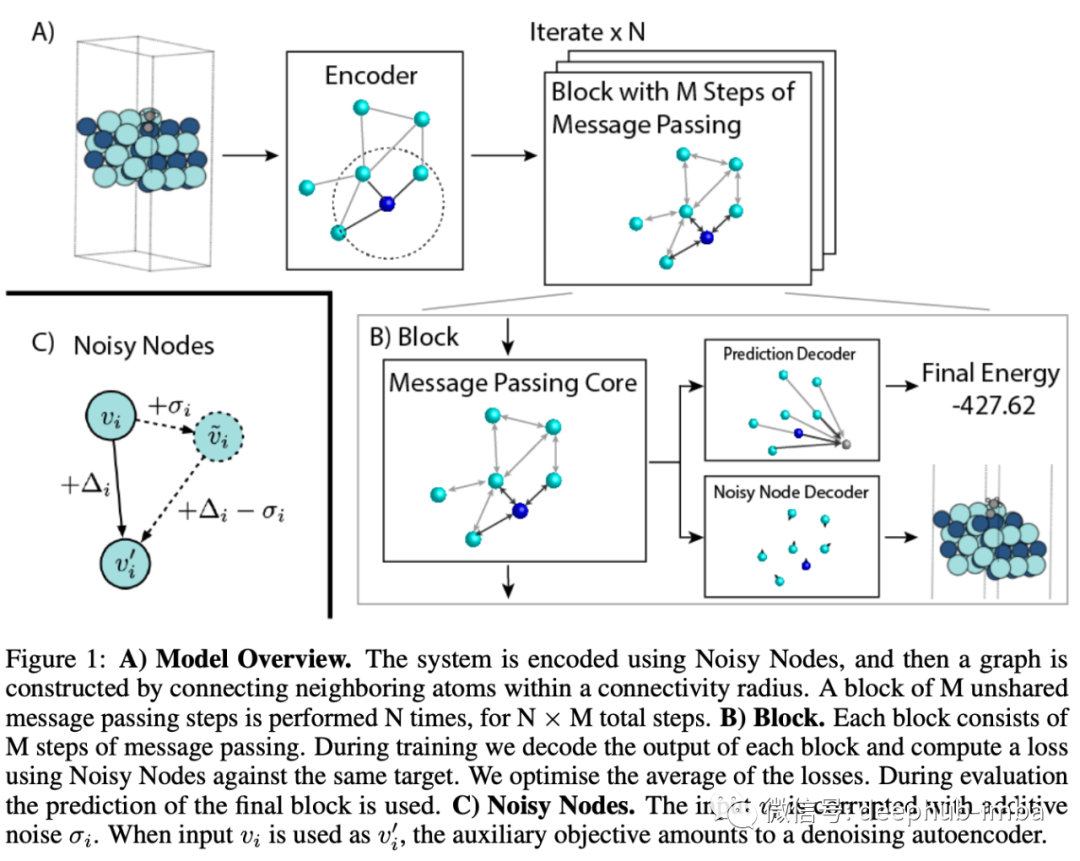
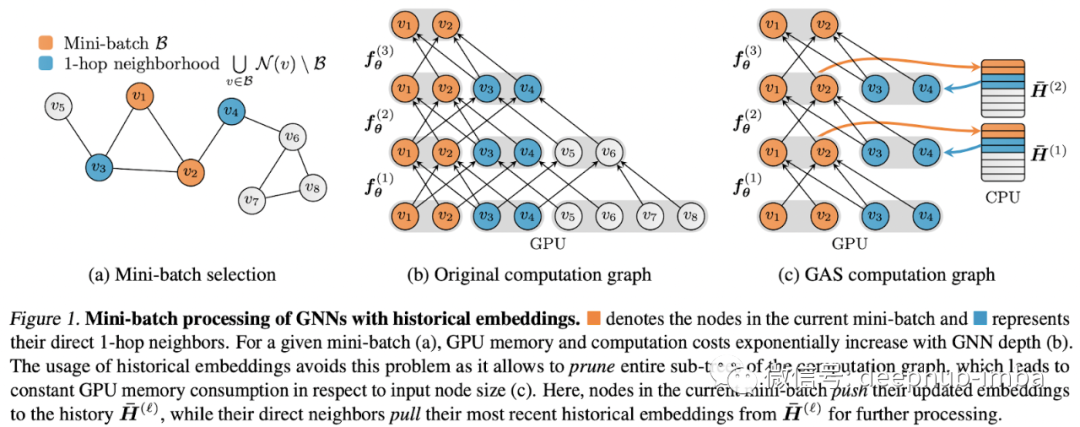
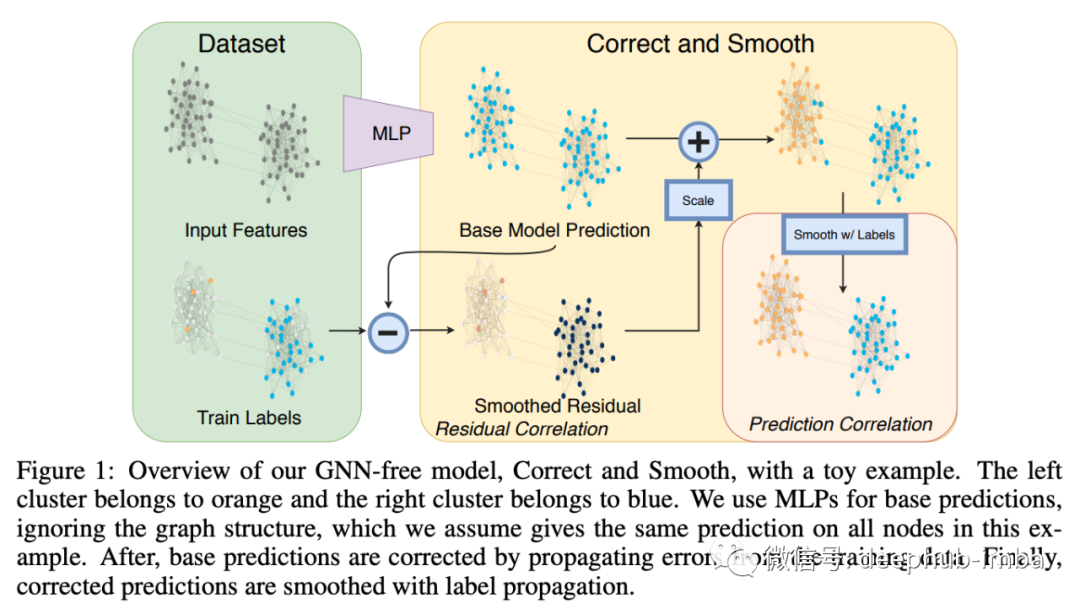
Scalability and Deep GNNs: 100 Layers and More
知识图谱
在直推和归纳环境中工作 不需要节点特征 可以在归纳模式中以与直推模式相同的方式进行训练 可扩展到现实世界的 KG 大小

一些其他的GNN的研究
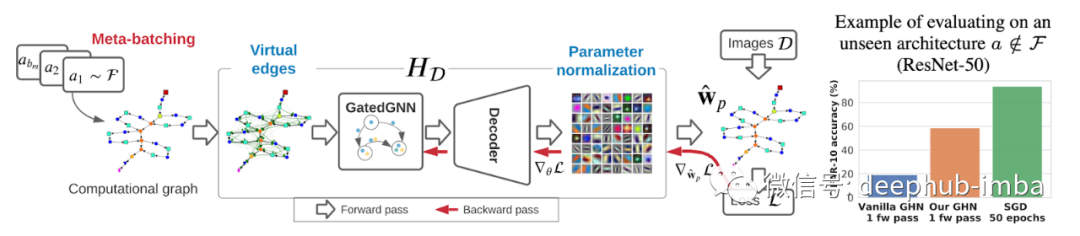
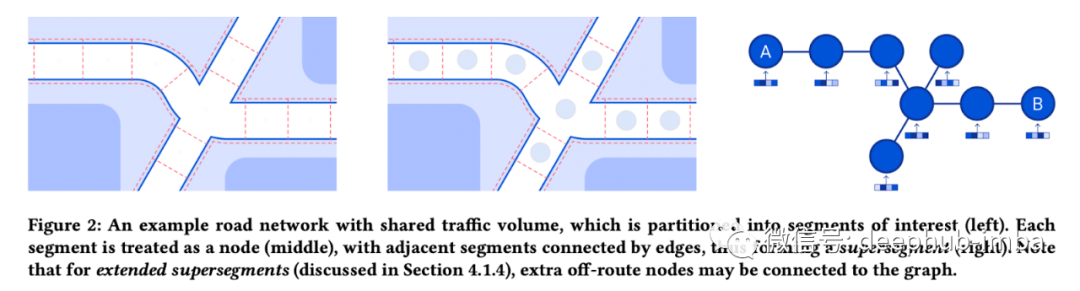
新数据集、挑战和任务
新的开源库
TensorFlow GNN - 作为 Tensorflow 世界中的一等公民的 GNN。TorchDrug - 用于分子和 KG 任务的基于 PyTorch 的 GNN 库
PyG 2.0 - 现在支持异构图、GraphGym 以及一系列改进和新模型DGL 0.7 - GPU 上的图形采样、更快的内核、更多模型PyKEEN 1.6 - 用于训练 KG 嵌入的首选库:更多模型、数据集、指标和 NodePiece 支持!Jraph - JAX 爱好者的 GNN以上就是2021年的总结,通过以上可以看到2022年将注定时Graph ML不平凡的一年。 编辑:于腾凯 校对:李敏
评论