
干货!分布式架构演进总结
点击上方“开源Linux”,选择“设为星标”
回复“学习”获取独家整理的学习资料!
一、前言
二、背景说明
用户模块:用户注册和管理。 商品模块:商品展示和管理。 交易模块:创建交易及支付结算。
三、阶段一:单应用架构
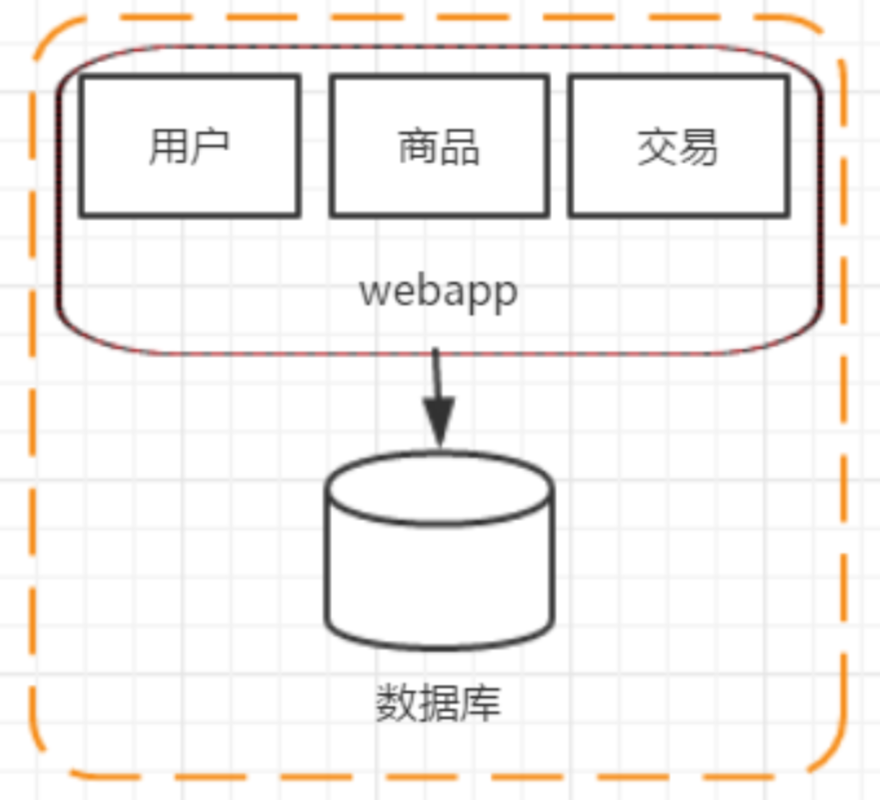
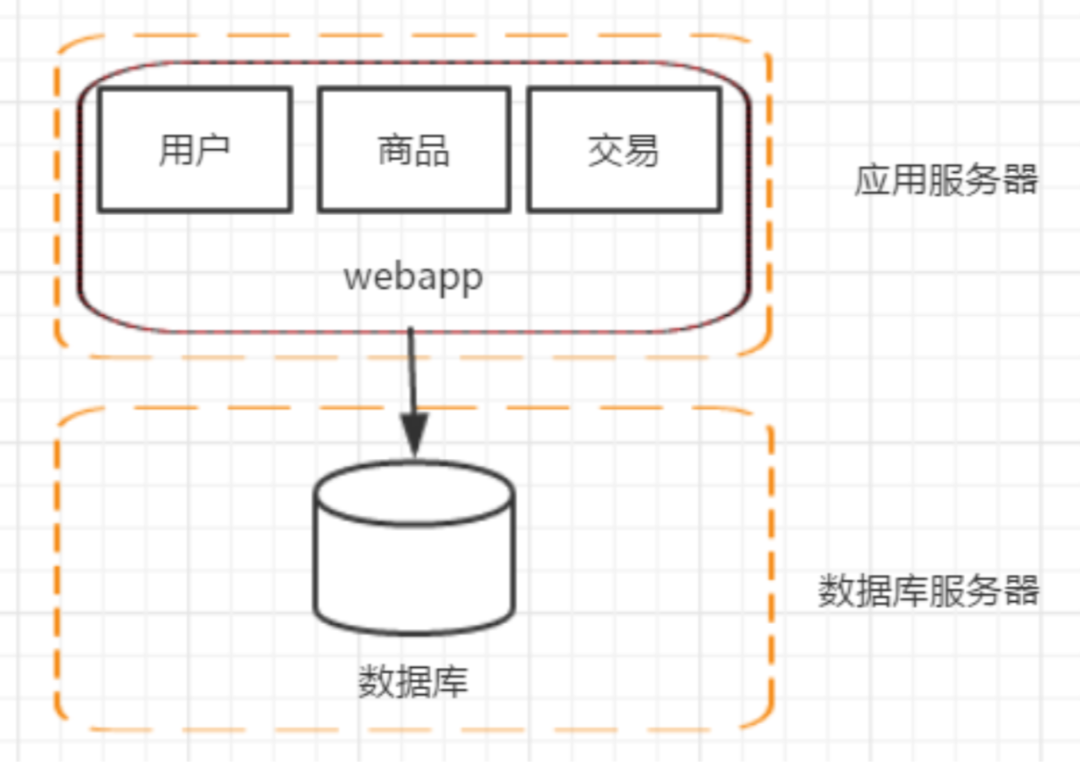
四、阶段二:应用服务器和数据库服务器分离
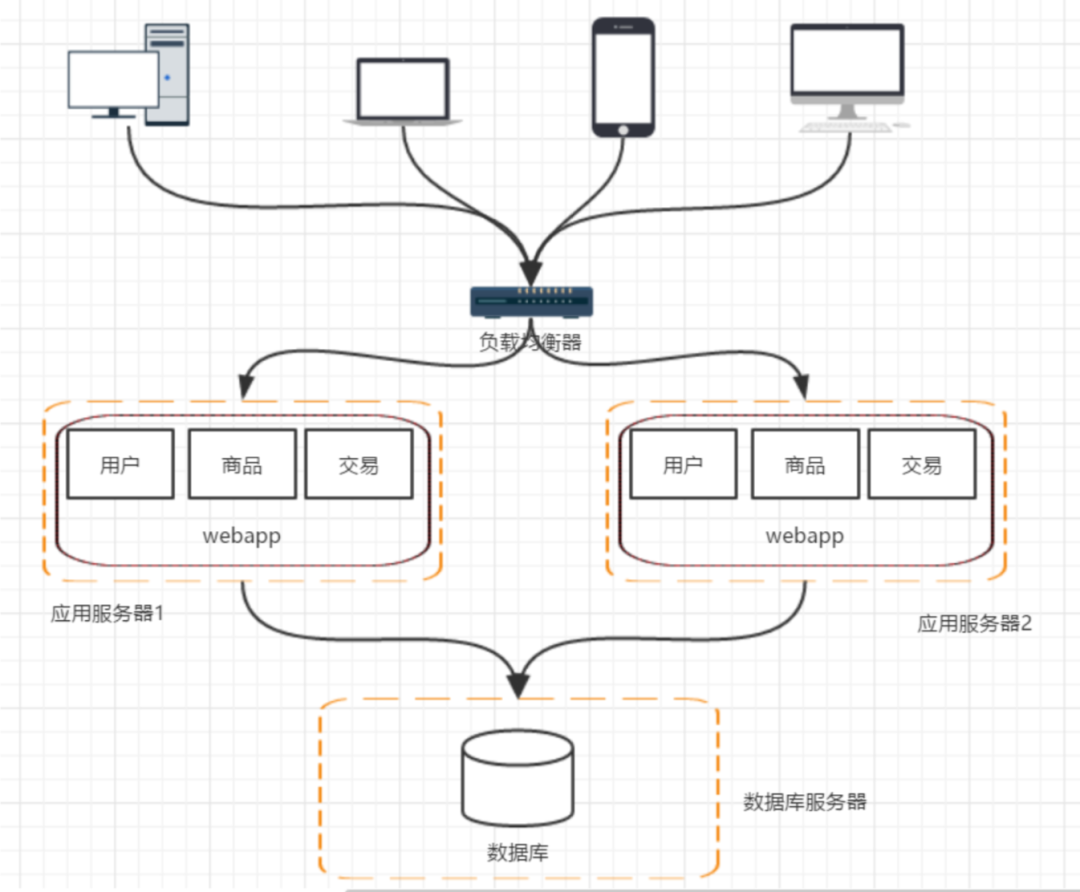
五、阶段三:应用服务器集群
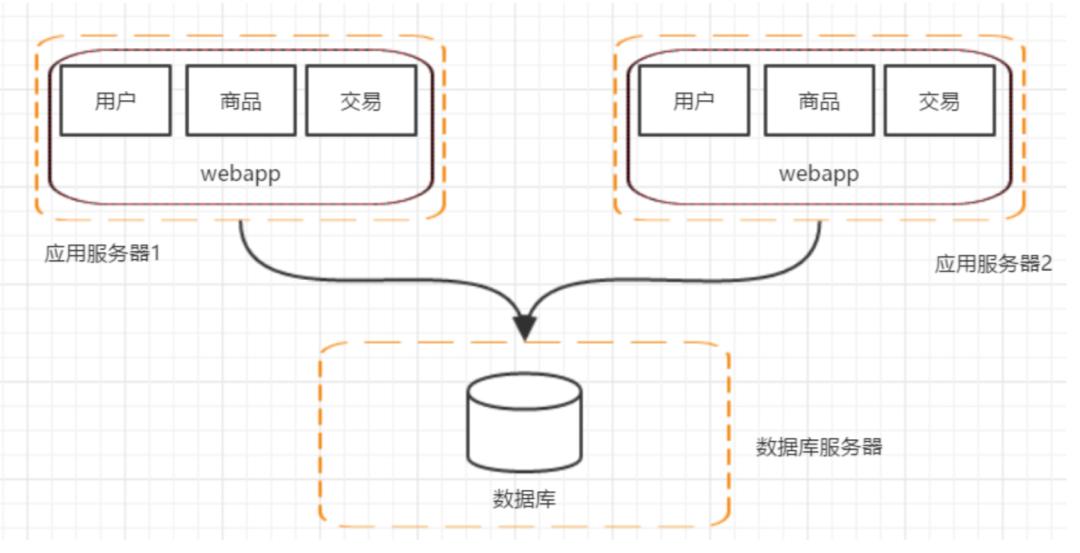
用户请求交由谁来转发到具体的应用服务器上(谁来负责负载均衡) 用户如果每次访问到的服务器不一样,那么如何维护 session,达到session共享的目的。
六、阶段四:数据库压力变大,数据库读写分离
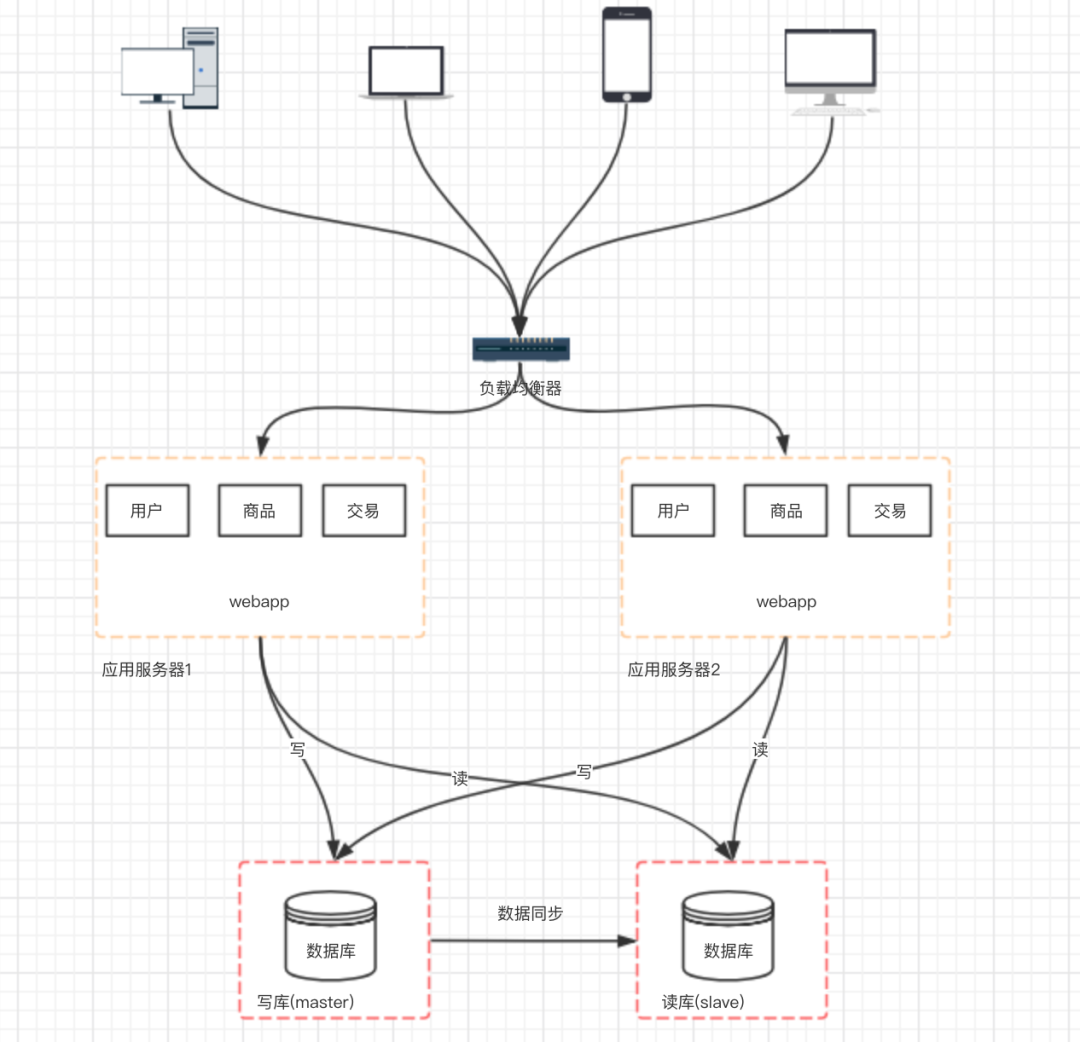
主从数据库之间的数据需要同步(可以使用 mysql 自带的 master-slave 方式实现主从复制 ) 应用中需要根据业务进行对应数据源的选择( 采用第三方数据库中间件,例如 mycat )
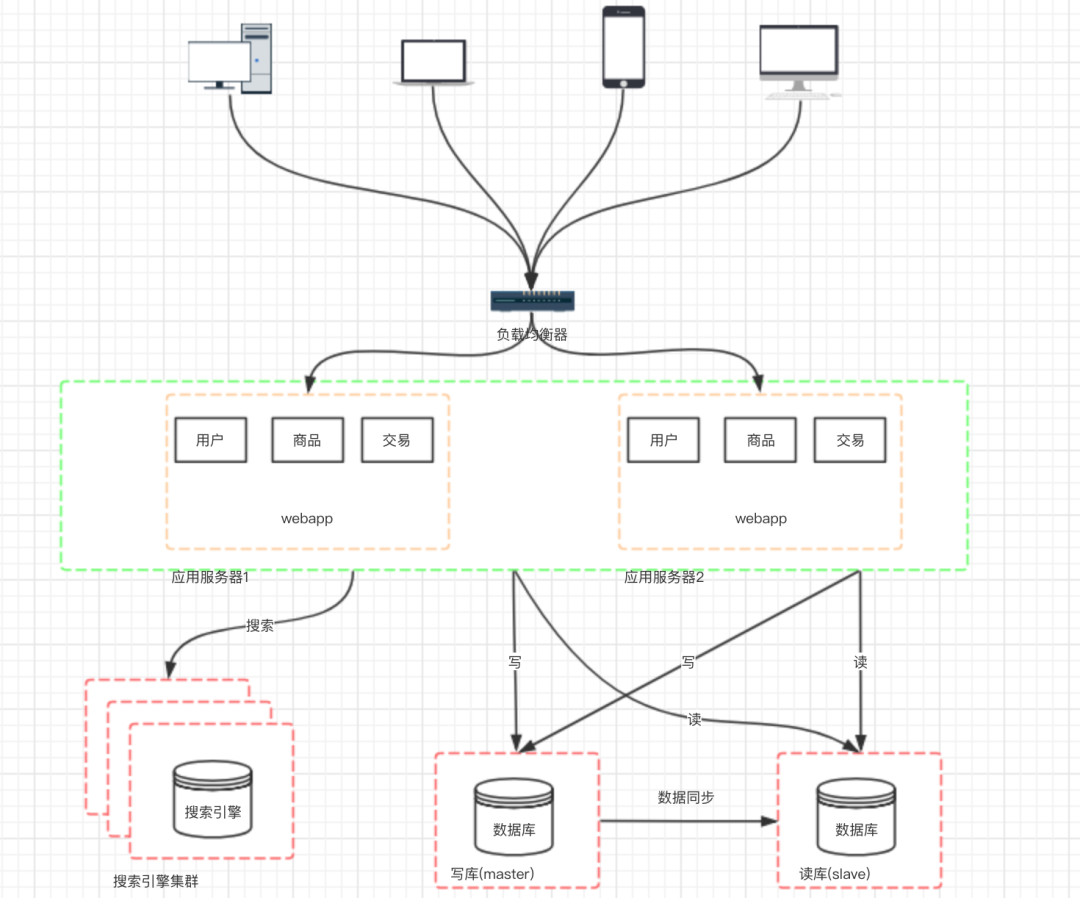
七、阶段五:使用搜索引擎缓解读库的压力
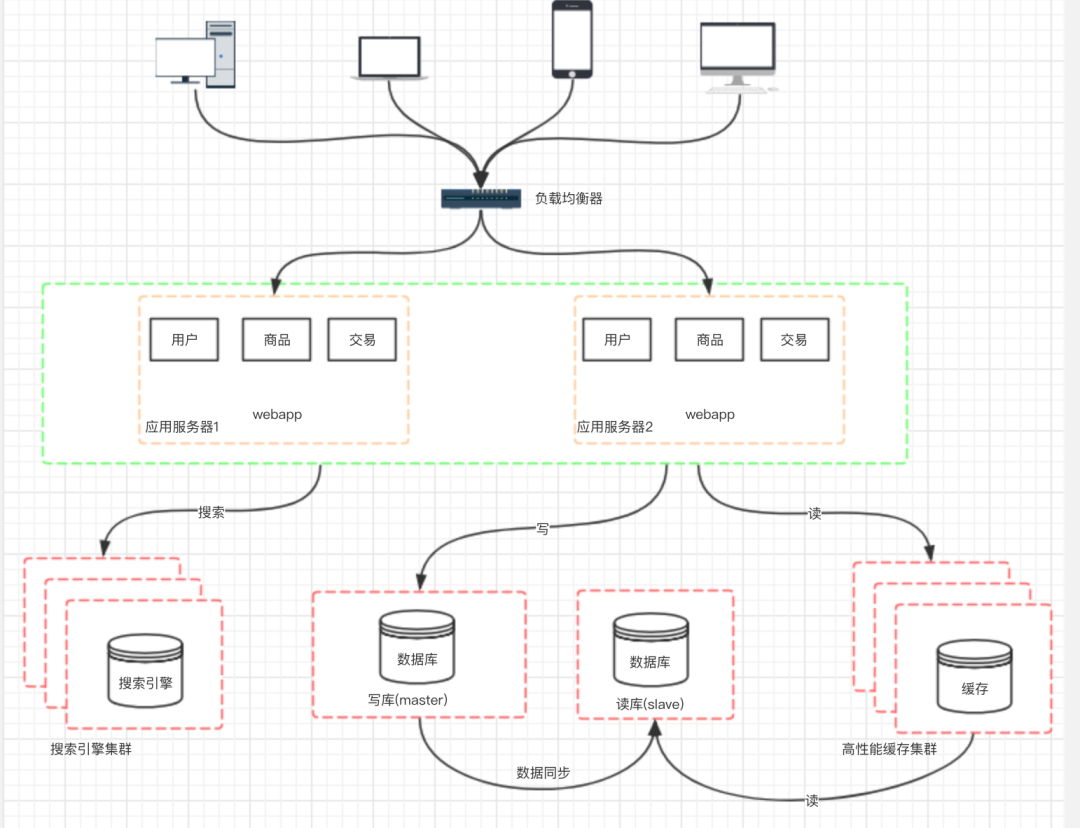
八、阶段六:引入缓存机制缓解数据库的压力
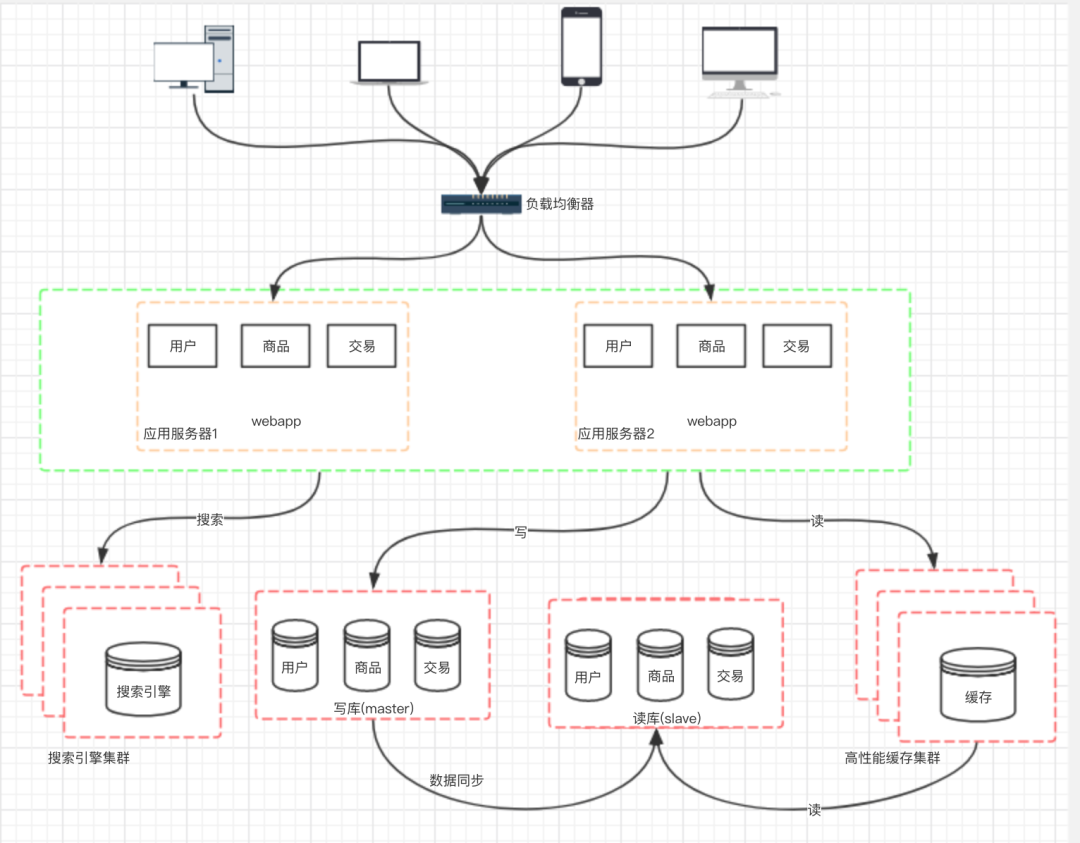
九、阶段七:数据库的水平/垂直拆分
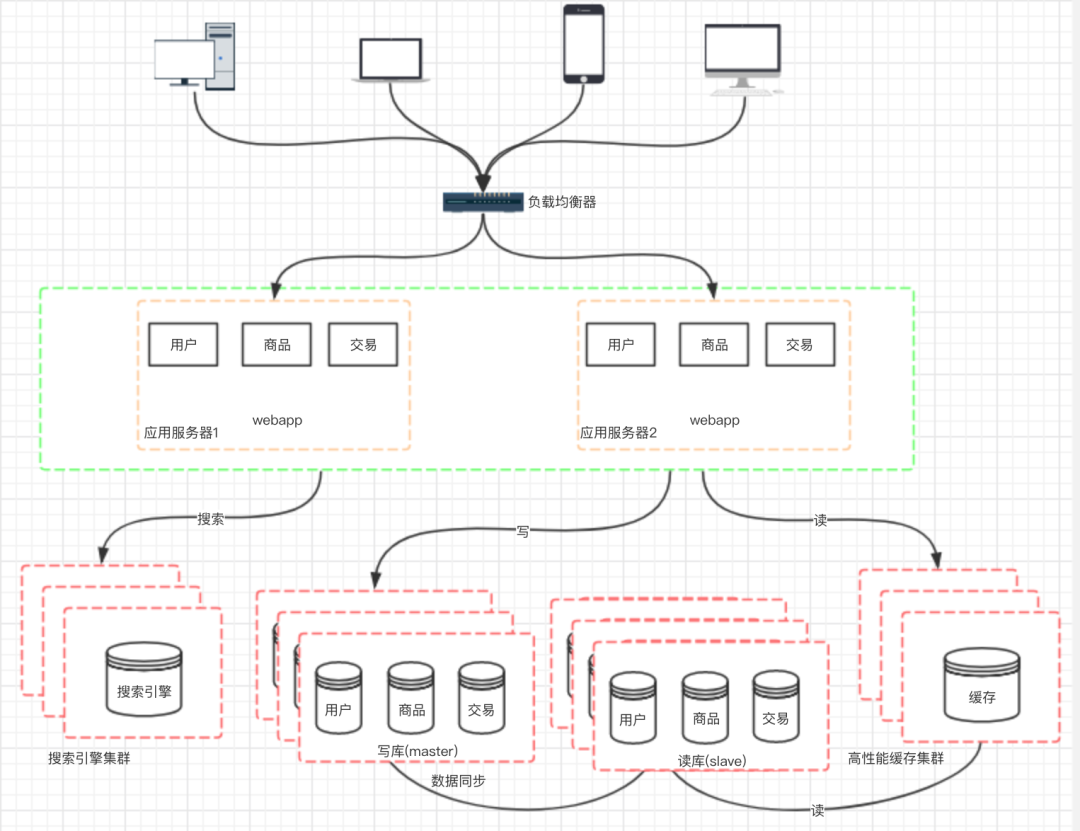
十、阶段八:应用的拆分
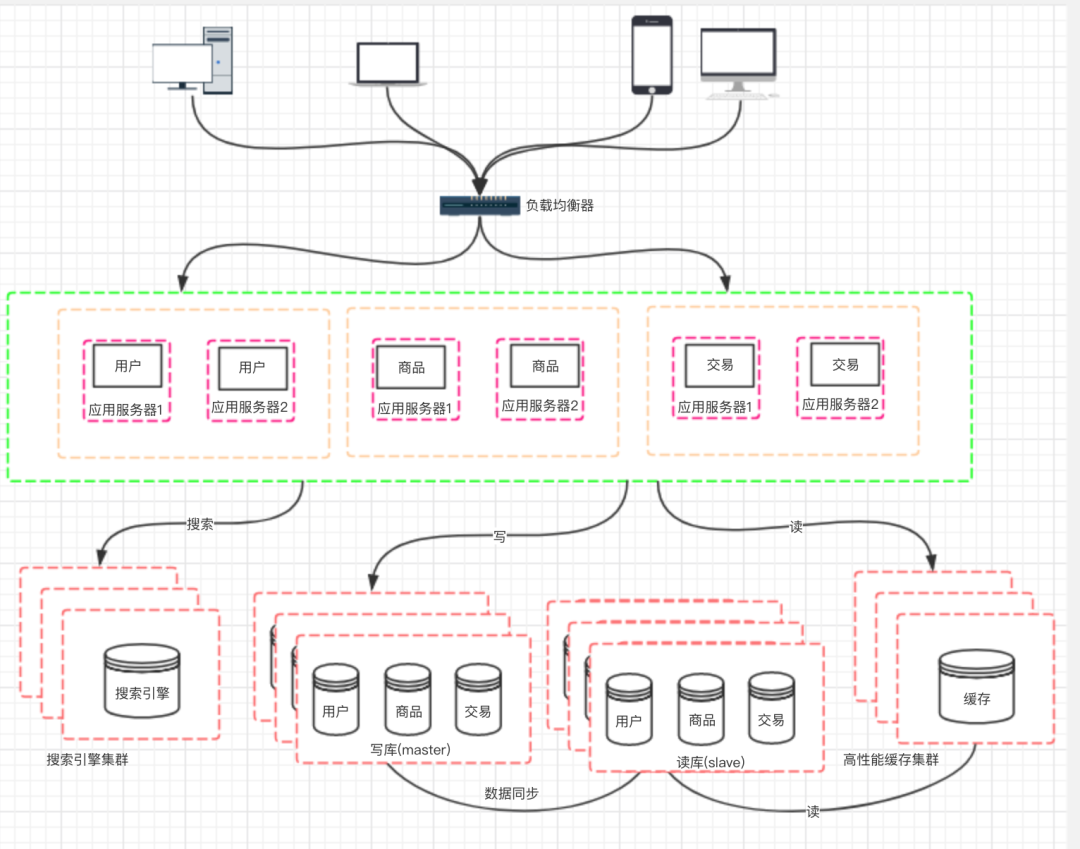
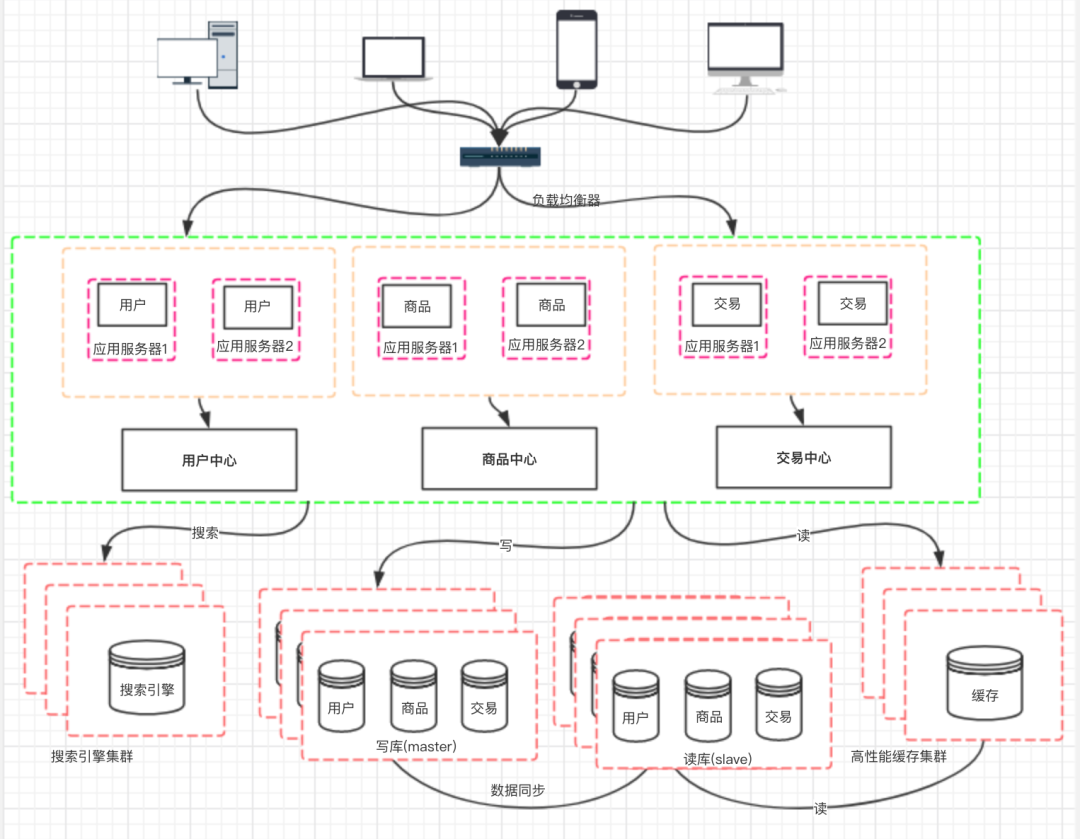
来自:https://www.cnblogs.com/logsharing/p/13037372.html
作者:在途中#
关注「开源Linux」加星标,提升IT技能
评论