
Network Augmentation 韩松团队新作
【GiantPandaCV导语】
本文介绍的是韩松团队针对欠拟合问题提出的一种解决方案,在代价可接受范围内能够提升小模型的性能。
1引入
专用于解决小型网络模型欠拟合 带来的问题,通过引入更大的模型包围住小模型从而得到额外的监督信息。欠拟合情况下使用正则化方法进行处理会导致性能更差。

NetAug适用场景:
数据集量比较大
模型参数量相对而言比较小
由于模型容量有限导致的欠拟合问题
2问题明确
与知识蒸馏区别:
知识蒸馏相当于学习一个soft label(或者说learned label smoothing), 而NetAug主要强调处理欠拟合问题,通过增强小模型的模型宽度来获取更多监督信息。
与普通正则化方法区别:
正则化方法有数据增强方法(Cutout,Mixup,AutoAug,RandAug)和Dropout系列(Dropout,StochasticDepth, SpatialDropout,DropBlock)。与这些解决过拟合正则化方法不同,NetAug主要关注欠拟合问题,进行数据增强反而会导致欠拟合问题。
3核心方法

如上图所示,训练的过程中会引入比原先小模型更宽的一系列网络,用宽网络的监督信号来增强小模型的学习。
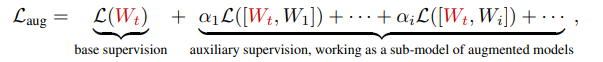
第一项是训练单个小网络需要的loss, 第二项是宽网络带来的辅助监督信息,其中
是缩放系数宽网络获取方式:augmentation factor r和diversity factor s两个系数。
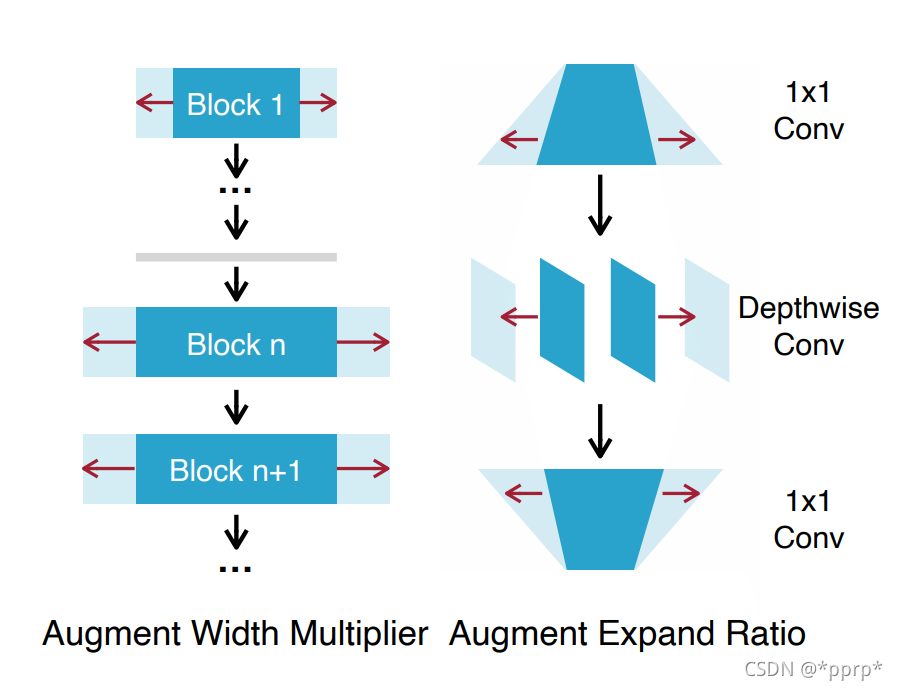
r 是用于选择最宽的边界,假设基础宽度为w,那么宽度选择范围为【w, rxw】
s则是控制采样频率,从w到rxw等距采样s个宽模型。
训练过程:
实际训练过程权重更新如下:
每次权重更新只训练小网络和单个宽网络,这样可以降低计算代价,并且通过实验发现,没必要同时采样多个宽网络进行训练,那样会导致性能的下降。
通过以上改进为欠拟合小模型带来了一定的收益,同时训练开销仅增大了17%
4实验
首先,论文为了证明NetAug和蒸馏方法是不相等的(正交),设计了一系列实验。
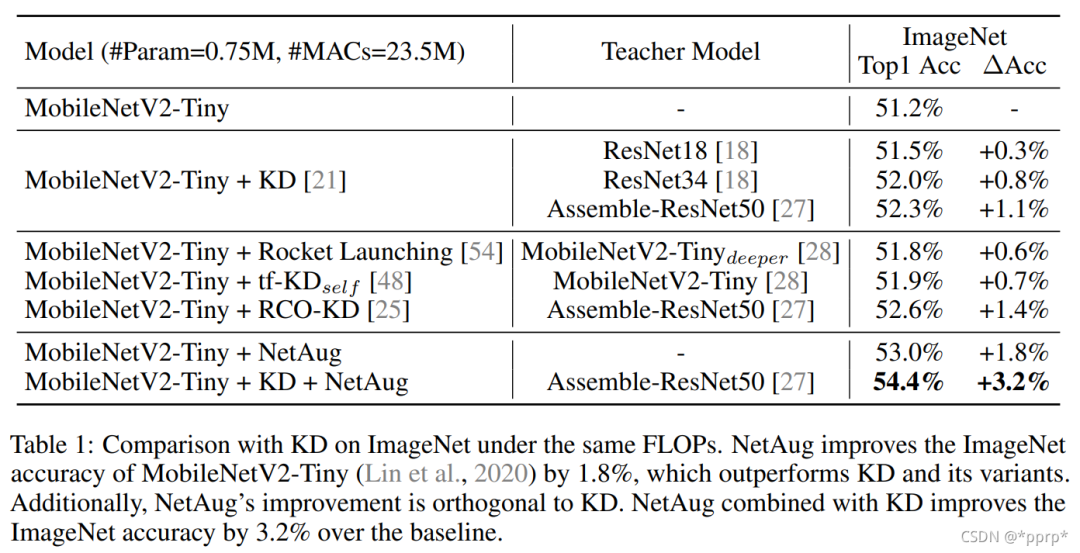
最优模型实际上是同时使用了知识蒸馏和NetAug的方案。
为了证明NetAug作用在欠拟合模型,设计了以下实验:
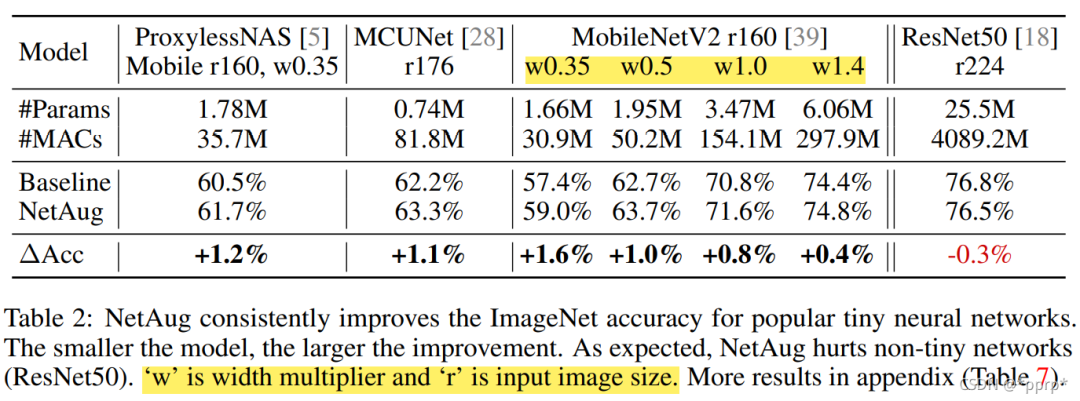
ProxylessNAS Mobile, MCUNet,MobileNetv2都是小模型,在这些小模型上使用NetAug均可以取得不错的提升。但是在比较大的模型ResNet50上,不存在欠拟合的问题,所以起到了反作用。
为了证明NetAug和其他正则化方法不同,设计了以下实验。
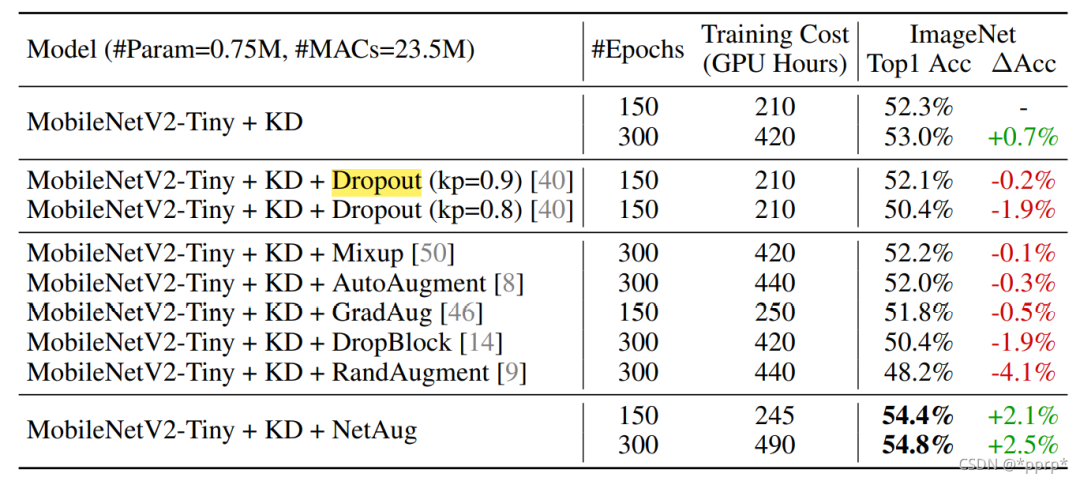
可以发现,在使用KD情况下加入正则化会导致性能下降。
但是使用KD情况下,采用NetAug会使得精度进一步提升。
在目标检测算法中应用:

5总结

针对过拟合有很多耳熟能详的处理策略,比如Dropout,数据增强,增加数据,控制模型复杂度,正则化等。
而针对模型容量不足带来的欠拟合问题,通常采用的是增加模型容量,或者增加特征表示。
本文针对欠拟合问题提出了一种更优的解法,在保证模型大小不变的情况下,提升小模型的实际性能,具有很高的价值(缺点是实现起来比较复杂)。

