
基于K-Means聚类算法的主颜色提取
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
01.简介
02.K均值类聚算法
K-Means算法是最流行但最简单的无监督算法。对于散布在n维空间中的所有数据点,它会将具有某些相似性的数据点归为一个群集。在随机初始化k个聚类质心之后,该算法迭代执行两个步骤:
1. 聚类分配:根据每个数据点距聚类质心的距离,为其分配一个聚类。
2. 移动质心:计算聚类所有点的平均值,并将聚类质心重定位到平均位置。
根据新的质心位置,将数据点重新分配给群集。
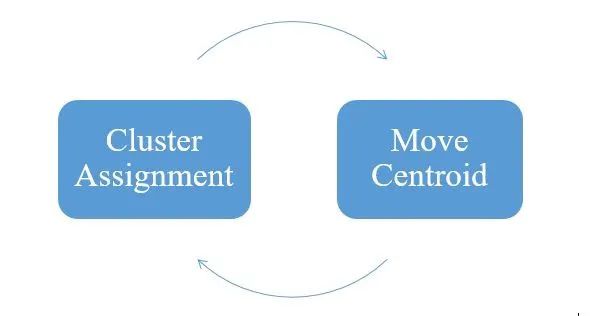
K-Means算法的迭代步骤
经过一定数量的迭代后,我们观察到聚类质心不会进一步移动或移动到任何新位置,聚类中的数据点也不会更改。至此,算法已经收敛。
我们将整个程序分为多个功能,首先导入该程序所需的模块
import matplotlib.pyplot as pltfrom mpl_toolkits.mplot3d import Axes3Dimport matplotlib.colors as colorimport numpy as npfrom collections import Counterimport pandas as pdimport mathfrom sklearn.cluster import KMeansfrom PIL import Imageimport webcolorsimport jsonimport argparse
在启动主函数之前,我们将创建一个ArgumentParser()对象以接受命令行参数,并创建相应的变量以接受命令行参数的值。与此同时保留了两个“可选”命令行参数,即clusters和imagepath。
parser = argparse.ArgumentParser()parser.add_argument("--clusters", help="No. of clusters")parser.add_argument("--imagepath", help="Path to input image")args = parser.parse_args()IMG_PATH = args.imagepath if args.imagepath else "images/poster.jpg"CLUSTERS = args.clusters if args.clusters else 5WIDTH = 128HEIGHT = 128
在clusters参数中,当imagepath用于传递带有图像名称的图像路径时,您需要提及要从图像中提取的颜色数量。默认情况下,程序将从图像中提取5种颜色,然后从文件夹图像中选择一个名为poster.jpg的图像。小伙伴们可以根据需要设置默认值。我们还将为图像调整大小定义宽度和高度,然后再从中提取颜色。我将宽度和高度保持为128px。
对于十六进制代码及其相应的颜色名称,我使用了JSON文件。颜色名称及其十六进制代码的整个词典已从下面提供的JavaScript文件中获取:
http : //chir.ag/projects/ntc/ntc.js(JavaScript文件)
http:// chir.ag/projects/ntc/(链接到创建者的网站)
我们将在名为color_dict的变量中读取JSON文件。现在,可以使用此字典变量我们可以直接访问JSON的键值对。
with open('colors.json') as clr:color_dict = json.load(clr)
现在让我们开始将图像作为输入并将其传递给K-Means算法。
def TrainKMeans(img):new_width, new_height = calculate_new_size(img)image = img.resize((new_width, new_height), Image.ANTIALIAS)img_array = np.array(image)img_vector = img_array.reshape((img_array.shape[0] * img_array.shape[1], 3))'''----------Training K-Means Clustering Algorithm----------'''kmeans = KMeans(n_clusters = CLUSTERS, random_state=0)labels = kmeans.fit_predict(img_vector)hex_colors = [rgb_to_hex(center) for center in kmeans.cluster_centers_]color_name = {}for c in kmeans.cluster_centers_:h, name = findColorName(c)color_name[h] = nameimg_cor = [[*x] for x in img_vector]'''img_cor is a nested list of all the coordinates (pixel -- RGB value) present in theimage'''cluster_map = pd.DataFrame()cluster_map['position'] = img_corcluster_map['cluster'] = kmeans.labels_cluster_map['x'] = [x[0] for x in cluster_map['position']]cluster_map['y'] = [x[1] for x in cluster_map['position']]cluster_map['z'] = [x[2] for x in cluster_map['position']]cluster_map['color'] = [hex_colors[x] for x in cluster_map['cluster']]cluster_map['color_name'] = [color_name[x] for x in cluster_map['color']]print(cluster_map)return cluster_map, kmeans
如大家所见,上面的函数“ TrainKMeans ”接受一个图像文件作为参数。在第一步中,我们将图像调整为我们之前在程序中定义的尺寸,并且使用了自定义函数来调整图像的大小。
def calculate_new_size(image):'''We are resizing the image (one of the dimensions) to 128 px and then, scaling theother dimension with same height by width ratio.'''if image.width >= image.height:wperc = (WIDTH / float(image.width))hsize = int((float(image.height) * float(wperc)))new_width, new_height = WIDTH, hsizeelse:hperc = (HEIGHT / float(image.height))wsize = int((float(image.width) * float(hperc)))new_width, new_height = wsize, HEIGHTreturn new_width, new_height
在自定义大小调整功能中,我们将图像的较长尺寸调整为固定尺寸HEIGHT或WIDTH,并重新调整了其他尺寸,同时使高度与图像宽度之比保持恒定。返回TrainKMeans函数,调整图像大小后,我将图像转换为numpy数组,然后将其重塑为3维矢量以表示下一步的RGB值。
现在,我们准备在图像中创建颜色簇。使用KMeans()函数,我们可以创建群集,其中超参数n_clusters设置为clusters,在程序开始时我们接受的命令行参数,而random_state等于零。接下来,我们将为输入图像文件拟合模型并预测聚类。使用聚类中心(RGB值),我们可以找到聚类代表的相应颜色的十六进制代码,为此使用了rgb_to_hex的自定义函数。
def rgb_to_hex(rgb):'''Converting our rgb value to hex code.'''hex = color.to_hex([int(rgb[0])/255, int(rgb[1])/255, int(rgb[2])/255])print(hex)return hex
这是一个非常简单的函数,它使用matplotlib.colors的to_hex函数。我们已经将RGB值标准化为0到1的范围,然后将它们转换为各自的十六进制代码。现在,我们有了每个颜色簇的十六进制代码。
在下一步中,我们将使用findColorName()函数查找每种颜色的名称。
def findColorName(rgb):'''Finding color name :: returning hex code and nearest/actual color name'''aname, cname = get_colour_name((int(rgb[0]), int(rgb[1]), int(rgb[2])))hex = color.to_hex([int(rgb[0])/255, int(rgb[1])/255, int(rgb[2])/255])if aname is None:name = cnameelse:name = anamereturn hex, namedef closest_colour(requested_colour):'''We are basically calculating euclidean distance between our set of RGB valueswith all the RGB values that are present in our JSON. After that, we are lookingat the combination RGB (from JSON) that is at least distance from inputRGB values, hence finding the closest color name.'''min_colors = {}for key, name in color_dict['color_names'].items():r_c, g_c, b_c = webcolors.hex_to_rgb("#"+key)rd = (r_c - requested_colour[0]) ** 2gd = (g_c - requested_colour[1]) ** 2bd = (b_c - requested_colour[2]) ** 2min_colors[math.sqrt(rd + gd + bd)] = name#print(min(min_colours.keys()))return min_colors[min(min_colors.keys())]def get_colour_name(requested_colour):'''In this function, we are converting our RGB set to color name using a thirdparty module "webcolors".RGB set -> Hex Code -> Color NameBy default, it looks in CSS3 colors list (which is the best). If it cannot findhex code in CSS3 colors list, it raises a ValueError which we are handlingusing our own function in which we are finding the closest color to the inputRGB set.'''try:closest_name = actual_name = webcolors.rgb_to_name(requested_colour)except ValueError:closest_name = closest_colour(requested_colour)actual_name = Nonereturn actual_name, closest_name
在findColorName函数中,我们调用了另一个名为get_color_name()的自定义函数,该函数返回两个值,即aname(实际名称)和cname(最近的颜色名称)。
在此功能中,使用第三方模块webcolors将RGB转换为颜色名称。默认情况下,webcolors函数在CSS3颜色列表中查找。如果无法在其列表中找到颜色,则会引发ValueError,这时使用另一个名为closest_colour()的自定义函数处理的。在此函数中,我正在计算输入RGB值与JSON中存在的所有RGB值之间的欧式距离。然后,选择并返回距输入RGB值最小距离的颜色。
在TrainKMeans()函数中创建的十六进制代码字典及其各自的名称。然后使用img_vector创建了图像中存在的所有RGB点的列表。接下来将初始化一个空的数据框cluster_map,并创建一个名为position的列,该列保存图像和列簇中存在的每个数据点(像素)的RGB值,我存储了每个数据点(像素)被分组到的簇号。然后,在color和color_name列中,我为图像的每个像素存储了十六进制代码及其各自的颜色名称。最后,我们返回了cluster_map数据框和kmeans对象。
def plotColorClusters(img):cluster_map, kmeans = TrainKMeans(img)fig = plt.figure()ax = Axes3D(fig)# grouping the data by color hex code and color name to find the total count of# pixels (data points) in a particular clustermydf = cluster_map.groupby(['color', 'color_name']).agg({'position':'count'}).reset_index().rename(columns={"position":"count"})mydf['Percentage'] = round((mydf['count']/mydf['count'].sum())*100, 1)print(mydf)# Plotting a scatter plot for all the clusters and their respective colorsax.scatter(cluster_map['x'], cluster_map['y'], cluster_map['z'], color = cluster_map['color'])plt.show()'''Subplots with image and a pie chart representing the share of each color identifiedin the entire photograph/image.'''plt.figure(figsize=(14, 8))plt.subplot(221)plt.imshow(img)plt.axis('off')plt.subplot(222)plt.pie(mydf['count'], labels=mydf['color_name'], colors=mydf['color'], autopct='%1.1f%%', startangle=90)plt.axis('equal')plt.show()def main():img = Image.open(IMG_PATH)plotColorClusters(img)
最后使用散点图绘制了3D空间中图像的每个数据点(像素),并在图像中标识了颜色,并使用饼图显示了图像的颜色分布。
项目代码:https://github.com/nandinib1999/DominantColors
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~