
谷歌发布万亿参数语言模型,语言模型何时超越人类语言能力?

新智元报道
新智元报道
来源:venturebeat
编辑:keyu
【新智元导读】处理过程更加复杂的人类语言模型在近几年得到了迅速发展,近日Google提出万亿参数语言模型Switch Transformer,进一步提高了语言模型可以达到的顶峰。这一切都表明,语言模型领域正处于「快速升温」的阶段,未来如何,我们拭目以待。
在短短几年时间里,深度学习算法经过了飞速的进化,已经具有了可以打败世界最顶尖棋手的水平,并能以不低于人类识别的准确度来精确地识别人脸。
但事实证明,掌握独特而复杂的人类语言,是人工智能面临的最艰巨挑战之一。
这种现状会被改变吗?
如果计算机可以具有有效理解所有人类语言的能力,那么这将会彻底改变世界各地的品牌、企业和组织之间打交道的方式。
可媲美人类的视觉识别模型「率先登场」
直到2015年,能够以与人类相当的准确率识别人脸的算法才出现:脸书DeepFace的准确率为97.4%,略低于人类的97.5%。
而作为参考,FBI的面部识别算法仅达到85%的准确率,这意味着仍然有超过七分之一的情况是错误的。
FBI的算法是由一组工程师手工设计的:每个功能,比如鼻子的大小和眼睛的相对位置,都是手动编程的。
而Facebook的算法则主要处理学习到的特征,它使用了一种特殊的深度学习架构,称为卷积神经网络,这个网络模仿了我们视觉皮层不同层次处理图像的方式。
Facebook之所以能够做到如此高的准确率,是因为它恰当的利用了可以实现学习功能的架构和数百万用户在分享的照片中标记好友的高质量数据,这两个元素成为了训练好的视觉模型可以达到人类识别水平的关键。
多语种高精度语言模型「姗姗来迟」
相比起视觉问题,语言似乎要复杂得多——据我们所知,人类是目前唯一使用复杂语言交流的物种。
不到十年前,如果要理解文本是什么,人工智能算法只会计算特定单词出现的频率。但这种方法显然忽略了一个事实 : 单词有同义词,而且只有在特定的上下文中才有意义。
2013年,Tomas Mikolov和他在谷歌的团队发现了如何创建一个能够学习单词含义的结构:
他们的word2vec算法可以将同义词之间彼此映射,并且能够对同义词的大小、性别、速度进行建模,甚至还可以学习到诸如国家和首都等函数的关系。

然而,仍有很重要的一部分没有得到处理——语境(上下文关系)。
这一领域的真正突破出现在2018年,当时,谷歌重磅引入了BERT模型:
Jacob Devlin和他的团队利用了一种典型的用于机器翻译的架构,并使其学习与句子上下文相关的单词的含义。通过教会这个模型去填补维基百科文章中缺失的单词,这个团队能够将语言结构嵌入到BERT模型中。
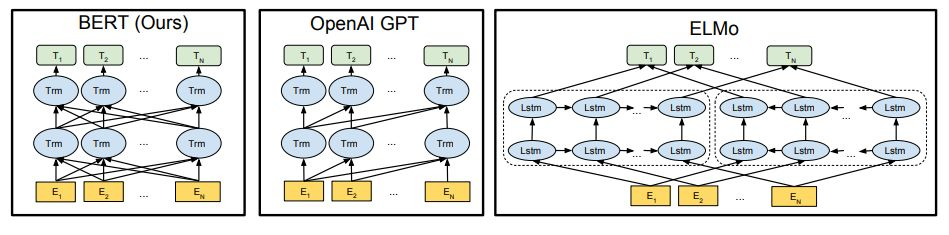
仅用有限数量的高质量标记数据,他们就能让BERT适应多种任务,包括找到问题的正确答案以及真正理解一个句子是关于什么的。
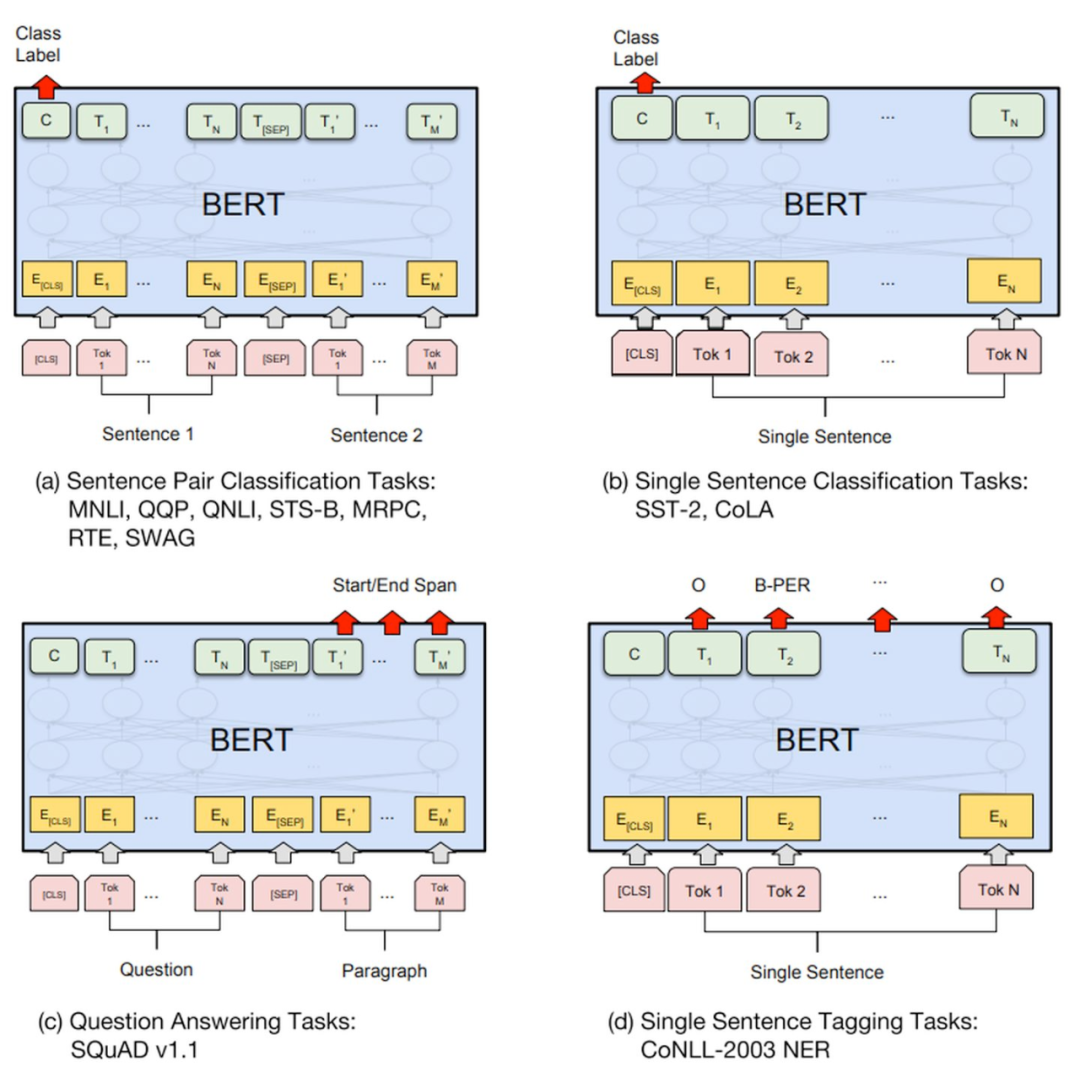
因此,他们成为了第一个真正把握语言理解的两要素的人:正确的架构和大量高质量的数据。
2019年,脸书的研究人员将这一研究进行了进一步的推进:
他们训练了一个从BERT衍生出的模型,令其同时学习100多种语言。训练的结果是,该模型能够学习一种语言的任务,例如英语,并使用它来完成其他任何语言的相同任务,如阿拉伯语、汉语和印地语。

这个语言无关模型在语言上可以与BERT有相同的表现,此外,在该模型中,语言转换过程中的一些干扰的影响是非常有限的。
在2020年初,Google的研究人员终于能够在广泛的语言理解任务中击败人类:
谷歌通过在更多数据上训练更大的网络,将BERT架构推向了极限——现在,这种T5模型在标注句子和找到问题的正确答案方面可以比人类表现得更好。
而10月份发布的语言无关的mT5模型,在从一种语言切换到另一种语言的能力方面,几乎可以与双语者一样出色。同时,它在处理语言种类方面有着不可思议的效果——它可以同时处理100多种语言。

本周公布的万亿参数模型Switch Transformer使语言模型变得更庞大,效果也变得更强大。
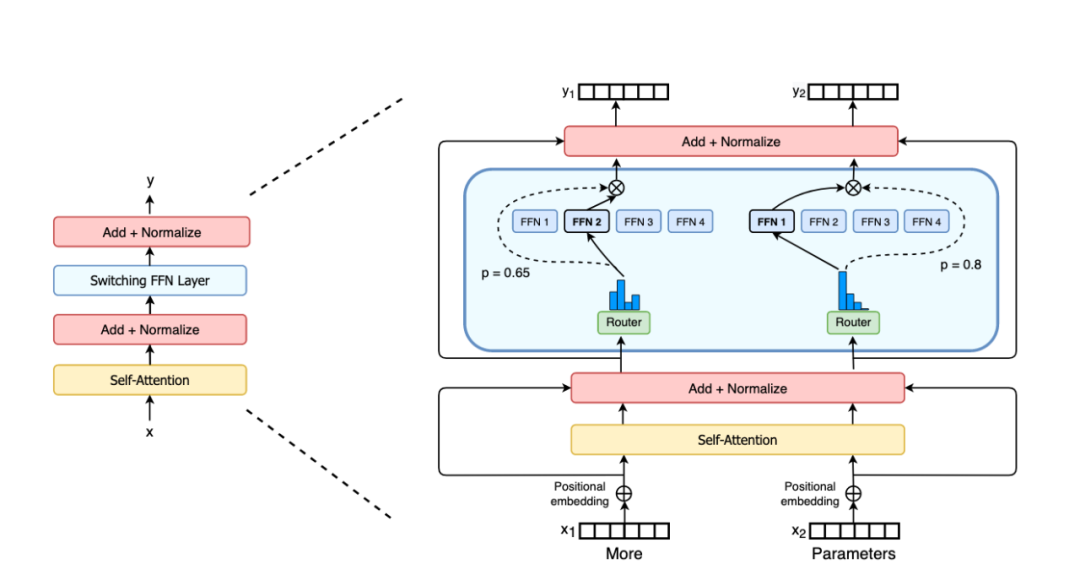
图:Switch Transformer编码块
畅想未来,语言模型潜力巨大
想象一下,聊天机器人可以理解你的任何想法:
他们会真正理解语境并记住过去的对话。而你会得到的答案不再是泛泛的回答,而是正切主题的。
搜索引擎将能够理解你的任何问题:
你甚至不需要使用正确的关键字,他们也会给出正确的答案。
你将得到一个了解你公司所有程序的「AI同事」:
如果你知道正确的「行话」,就不用再问其他同事问题了。当然,也不再会有同事和你说:「为什么不把公司所有文件都看一遍再问我?」。
数据库的新时代即将到来:
跟结构化数据的繁琐工作说再见吧。任何备忘录,电子邮件,报告等,将得到自动解释,存储和索引。你将不再需要IT部门运行查询来创建报告,只需要和数据库说一下就行了。
而这,还只是冰山一角——
任何目前仍需要人类去理解语言的过程,都正处于被破坏或被自动化的边缘。
Talk isn’t cheap:庞大语言模型耗费巨大
在构建宏伟蓝图的同时,别忘了,还有个「陷阱」在这里:
为什么这些算法不是随处可见?
一般情况下,训练这些模型大概率要花费极其昂贵的价格。举个例子,训练T5算法的云计算成本约为130万美元。
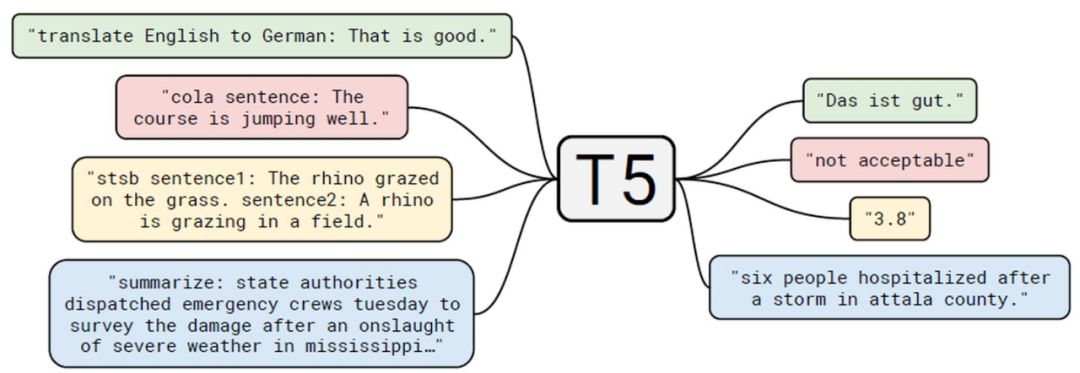
虽然谷歌的研究人员非常友好地分享了这些模型,但是,针对当前的特定任务,如果不对它们进行微调,那么这些模型在具体任务中很可能就无法使用。
因此,即使大公司开源了这些模型,对于其他人来说,直接拿来使用也是一件代价高昂的事情。
而且,一旦使用者针对特定的问题优化了这些模型,执行的过程中仍然需要大量的计算能力和超长的时间消耗。
随着时间的推移,随着各大公司在微调上的投入,我们将看到新的的应用出现。
而且,如果大家相信摩尔定律,我们可以在大约五年内看到更复杂的应用。此外,可以超越T5算法的新的模型也将会出现。
2021年初,我们距离人工智能最重大的突破以及由此带来的无限可能,仅仅只有一步之遥。
参考链接:
https://venturebeat.com/2021/01/17/language-ai-is-really-heating-up/
