
Pandas与SQL的超强结合,爆赞!

网传50道经典MySQL面试题中使用到的几张原表。关于下方各表之间的关联关系,我就不给大家说明了,仔细观察字段名,应该就可以发现。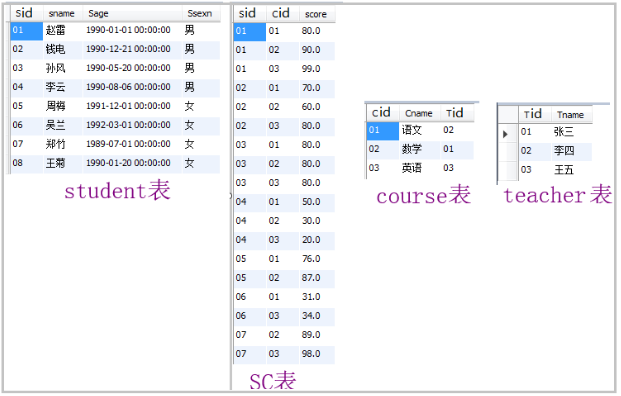
简介
pandas中的DataFrame是一个二维表格,数据库中的表也是一个二维表格,因此在pandas中使用sql语句就显得水到渠成,pandasql使用SQLite作为其操作数据库,同时Python自带SQLite模块,不需要安装,便可直接使用。
这里有一点需要注意的是:使用pandasql读取DataFrame中日期格式的列,默认会读取年月日、时分秒,因此我们要学会使用sqlite中的日期处理函数,方便我们转换日期格式,下方提供sqlite中常用函数大全,希望对你有帮助。
sqlite函数大全:http://suo.im/5DWraE
导入相关库:
import pandas as pd
from pandasql import sqldf
声明全局变量的2种方式
在使用之前,声明该全局变量;
一次性声明好全局变量;
在使用之前,声明该全局变量
df1 = pd.read_excel("student.xlsx")
df2 = pd.read_excel("sc.xlsx")
df3 = pd.read_excel("course.xlsx")
df4 = pd.read_excel("teacher.xlsx")
global df1
global df2
global df3
global df4
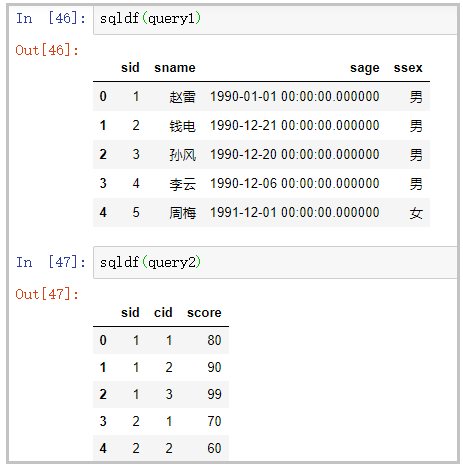
query1 = "select * from df1 limit 5"
query2 = "select * from df2 limit 5"
query3 = "select * from df3"
query4 = "select * from df4"
sqldf(query1)
sqldf(query2)
sqldf(query3)
sqldf(query4)
部分结果如下:

一次性声明好全局变量
df1 = pd.read_excel("student.xlsx")
df2 = pd.read_excel("sc.xlsx")
df3 = pd.read_excel("course.xlsx")
df4 = pd.read_excel("teacher.xlsx")
pysqldf = lambda q: sqldf(q, globals())
query1 = "select * from df1 limit 5"
query2 = "select * from df2 limit 5"
query3 = "select * from df3"
query4 = "select * from df4"
sqldf(query1)
sqldf(query2)
sqldf(query3)
sqldf(query4)
部分结果如下:
写几个简单的SQL语句
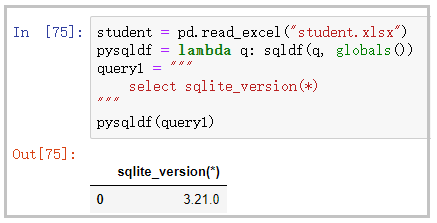
查看sqlite的版本
student = pd.read_excel("student.xlsx")
pysqldf = lambda q: sqldf(q, globals())
query1 = """
select sqlite_version(*)
"""
pysqldf(query1)
结果如下:
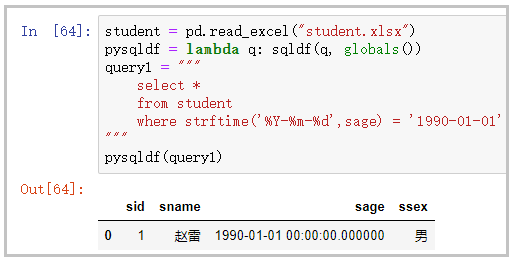
where筛选
student = pd.read_excel("student.xlsx")
pysqldf = lambda q: sqldf(q, globals())
query1 = """
select *
from student
where strftime('%Y-%m-%d',sage) = '1990-01-01'
"""
pysqldf(query1)
结果如下:
多表连接
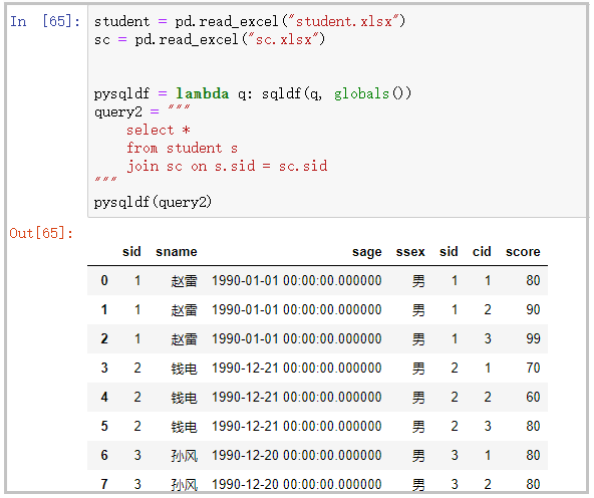
student = pd.read_excel("student.xlsx")
sc = pd.read_excel("sc.xlsx")
pysqldf = lambda q: sqldf(q, globals())
query2 = """
select *
from student s
join sc on s.sid = sc.sid
"""
pysqldf(query2)
部分结果如下:
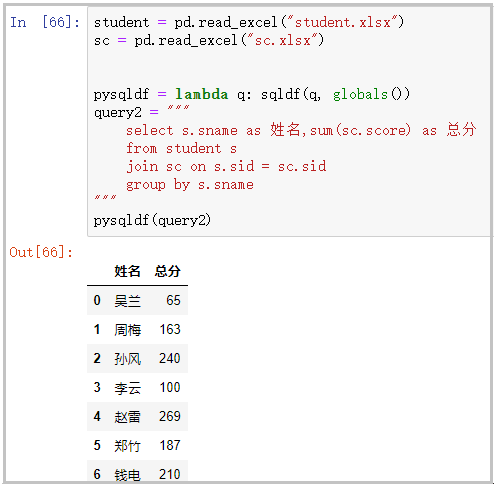
分组聚合
student = pd.read_excel("student.xlsx")
sc = pd.read_excel("sc.xlsx")
pysqldf = lambda q: sqldf(q, globals())
query2 = """
select s.sname as 姓名,sum(sc.score) as 总分
from student s
join sc on s.sid = sc.sid
group by s.sname
"""
pysqldf(query2)
结果如下:
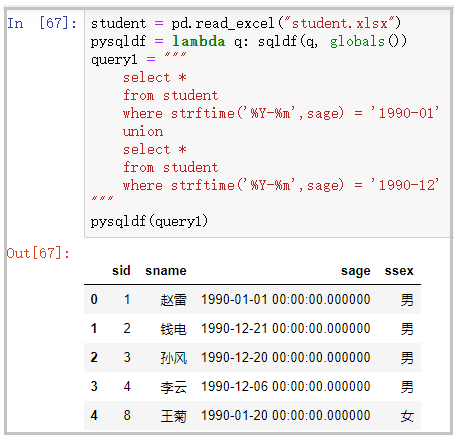
union查询
student = pd.read_excel("student.xlsx")
pysqldf = lambda q: sqldf(q, globals())
query1 = """
select *
from student
where strftime('%Y-%m',sage) = '1990-01'
union
select *
from student
where strftime('%Y-%m',sage) = '1990-12'
"""
pysqldf(query1)
结果如下:
推荐阅读:
入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径
干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影
趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!
AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影
小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|

年度爆款文案
点阅读原文,看B站我的20个视频!