
谷歌首次验证「全科医学AI系统」,看病难真要成历史?
来自:新智元
【导读】基于100万医学数据、PaLM模型、ViT模型,谷歌全新模型Med-PaLM M成医学界大模型新sota!
 论文链接:https://www.nature.com/articles/s41586-023-05881-4
论文链接:https://www.nature.com/articles/s41586-023-05881-4
 论文链接:https://arxiv.org/pdf/2307.14334.pdf
论文链接:https://arxiv.org/pdf/2307.14334.pdf
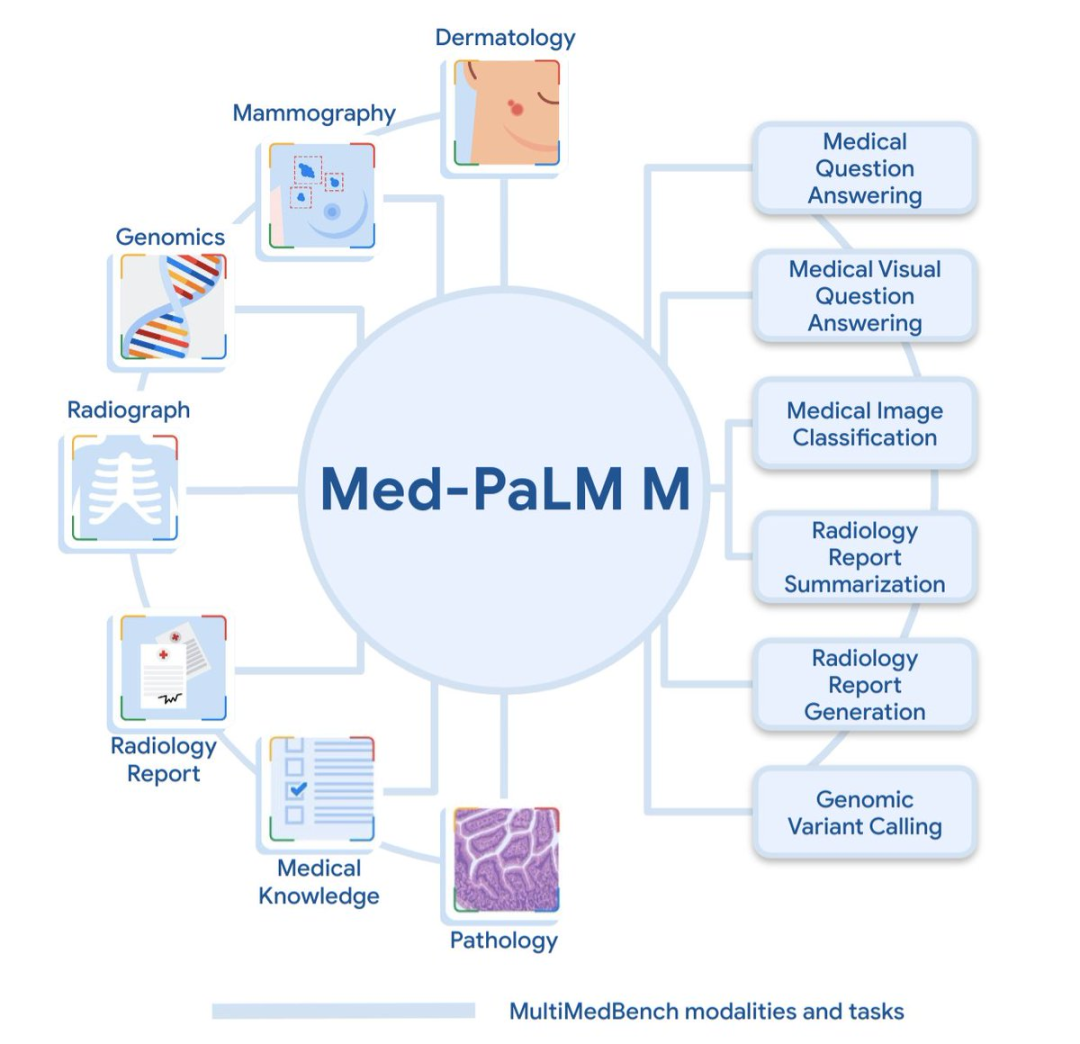
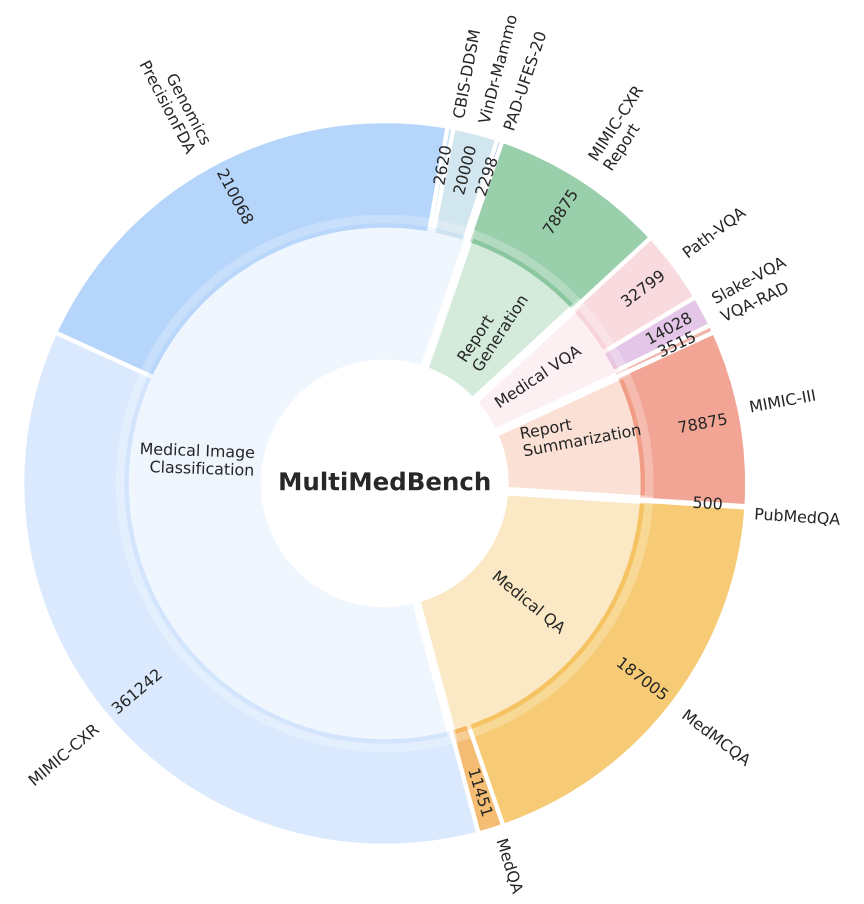
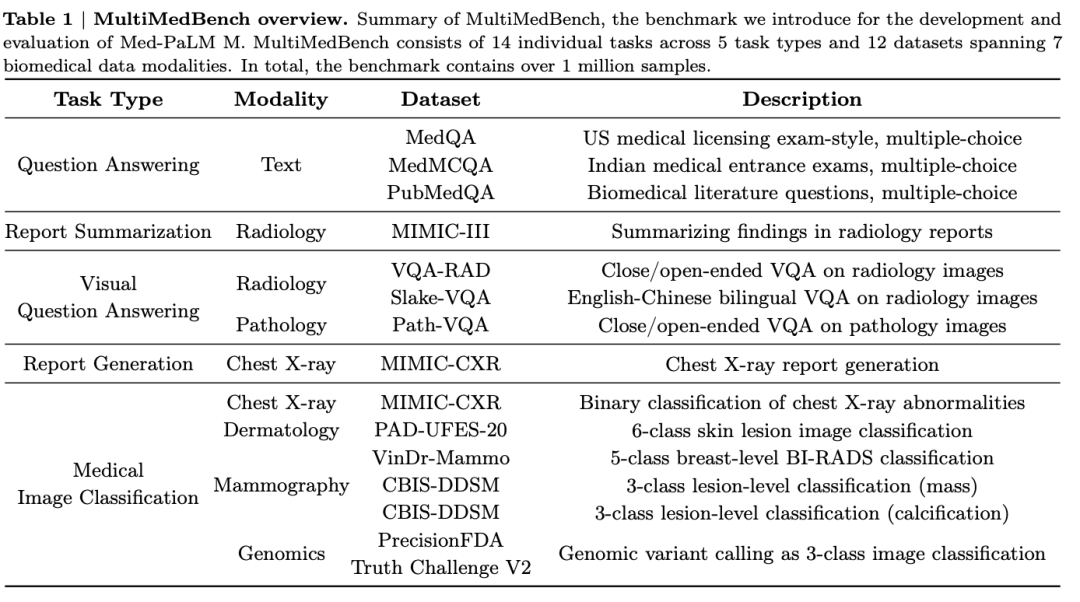
MultiMedBench
MultiMedBench
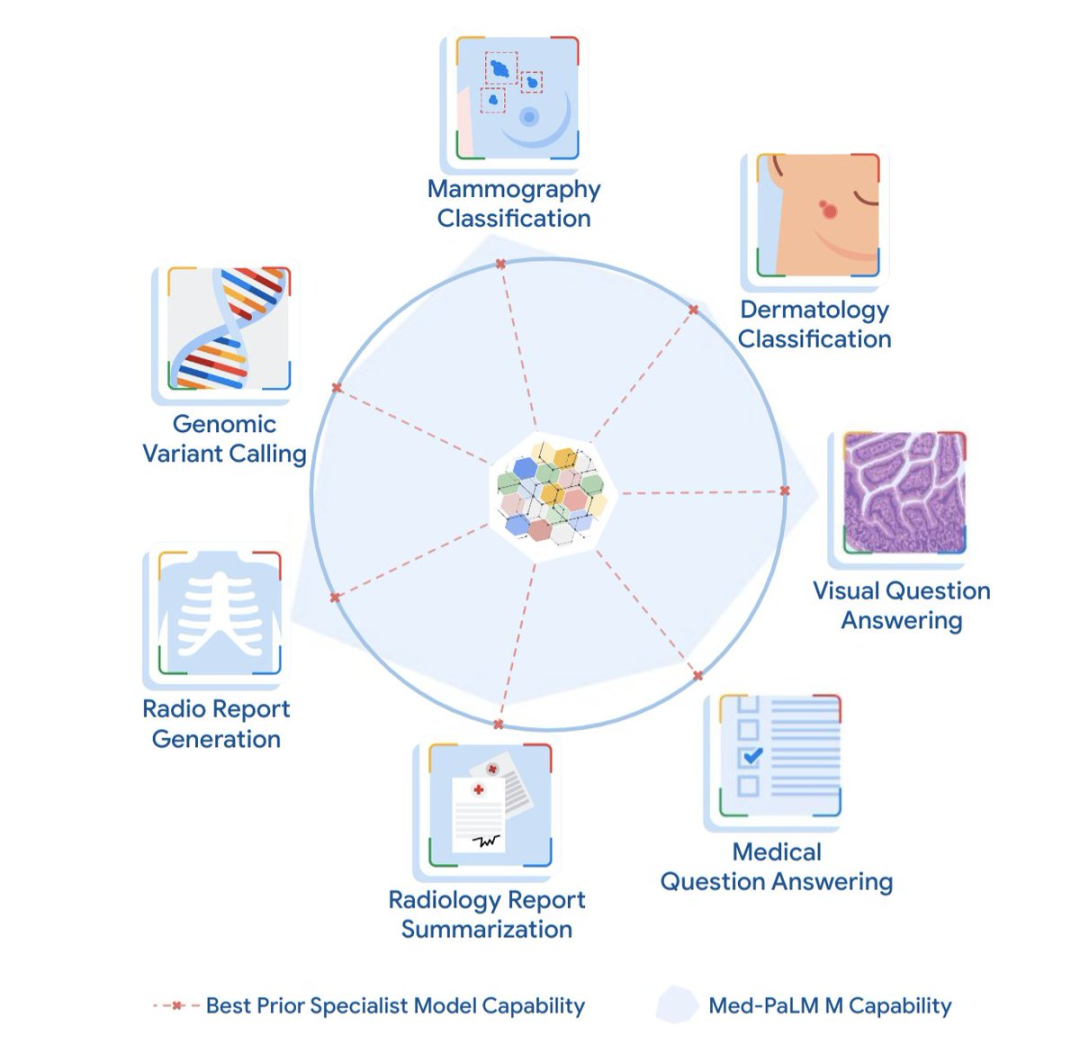
Med-PaLM M:全科生物医疗AI的概念验证
Med-PaLM M:全科生物医疗AI的概念验证
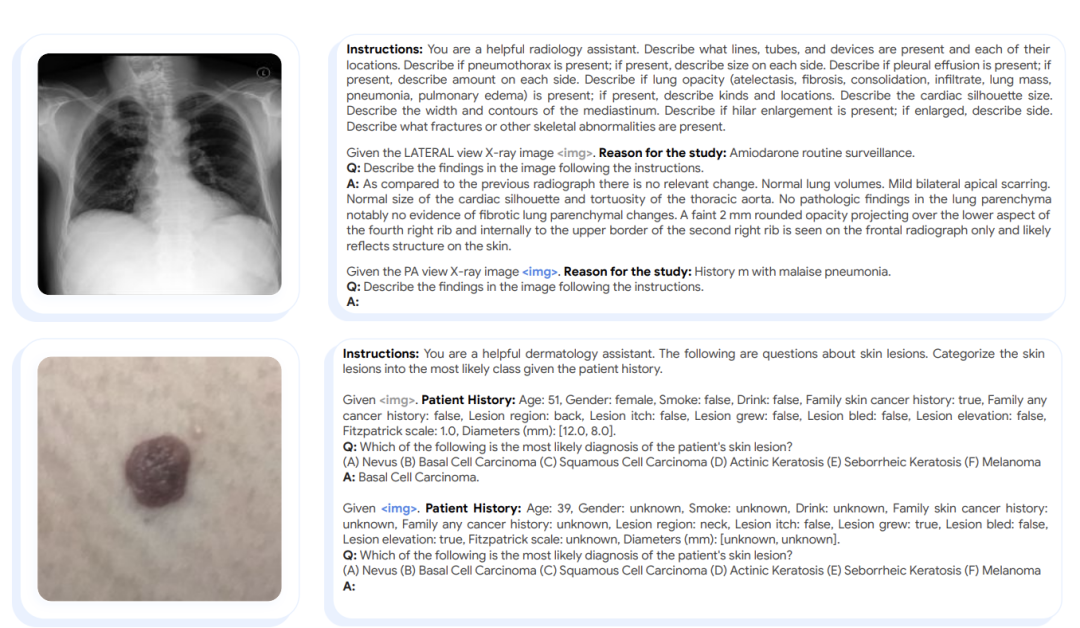
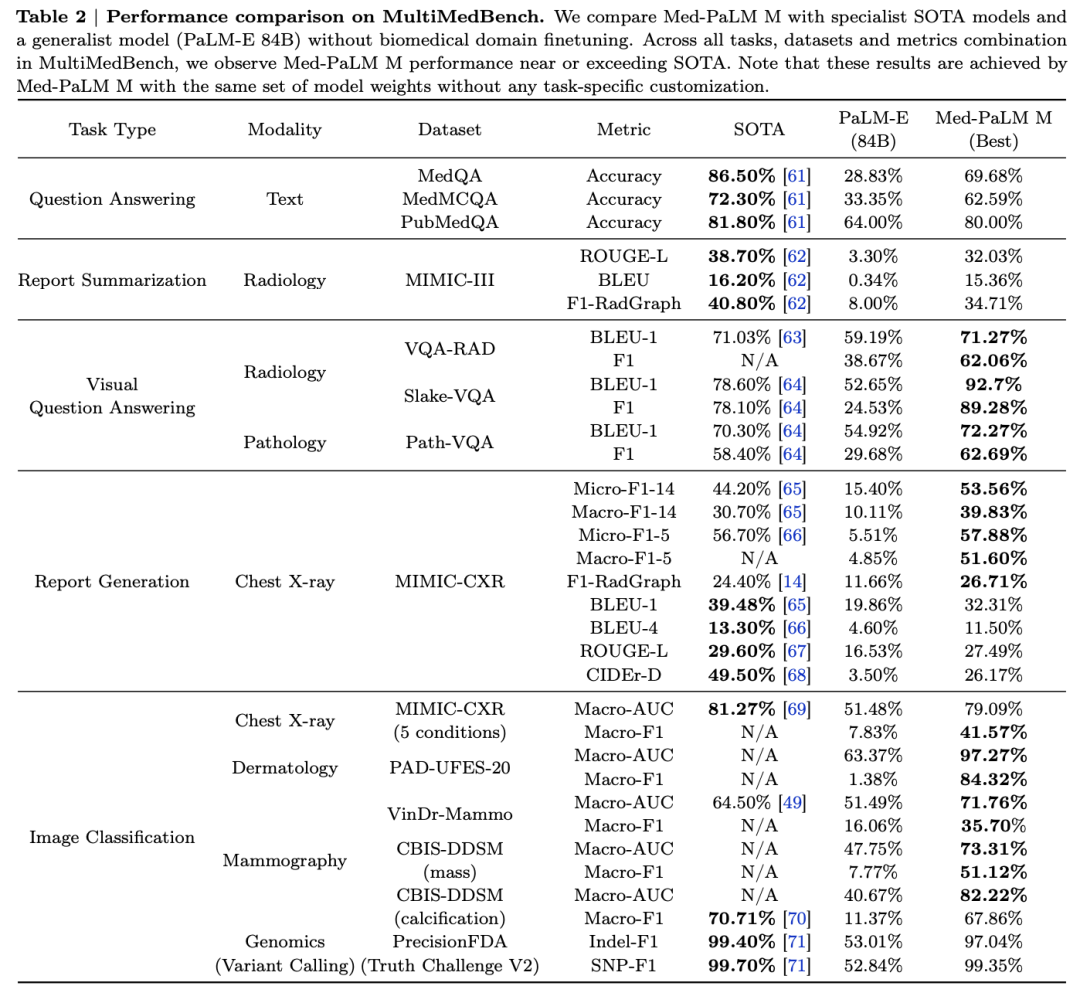
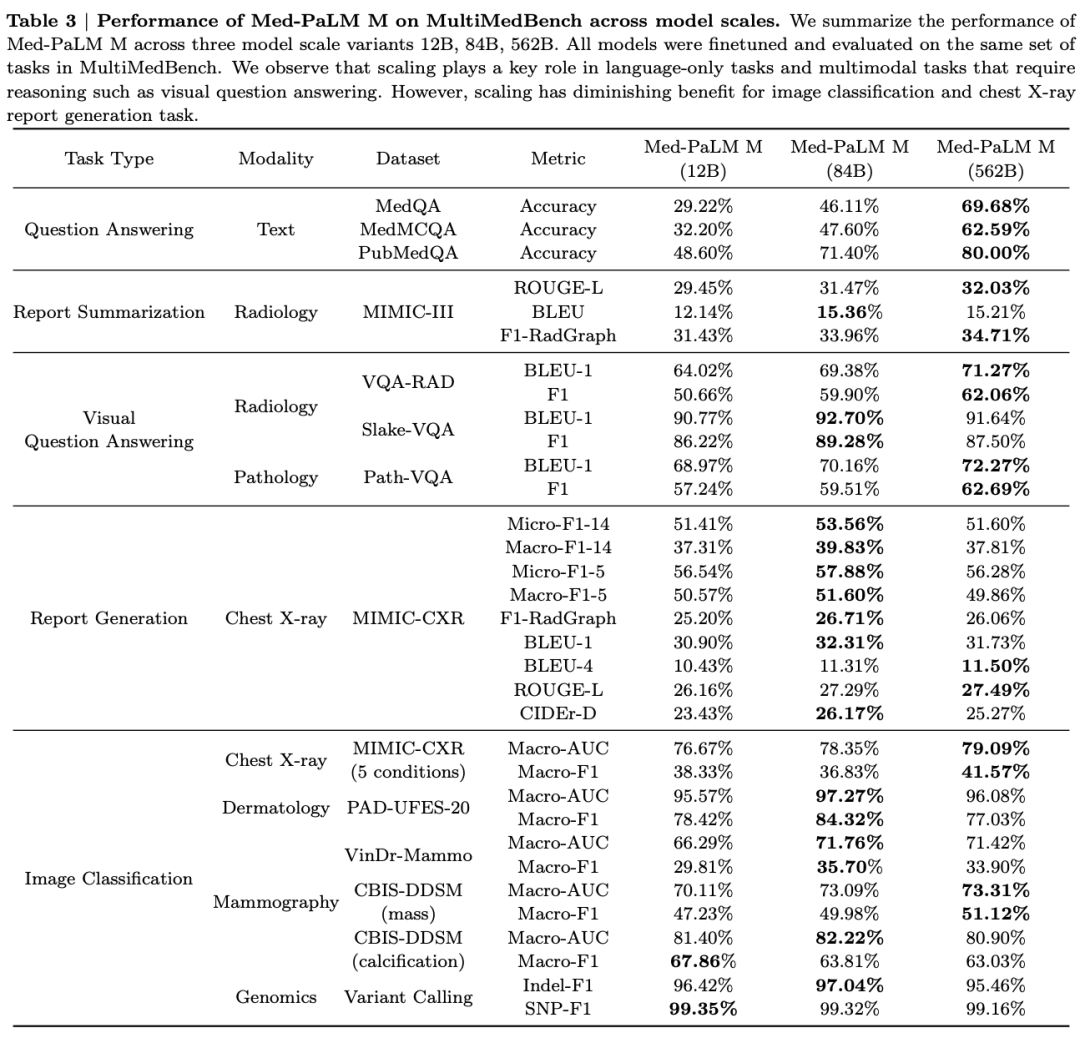
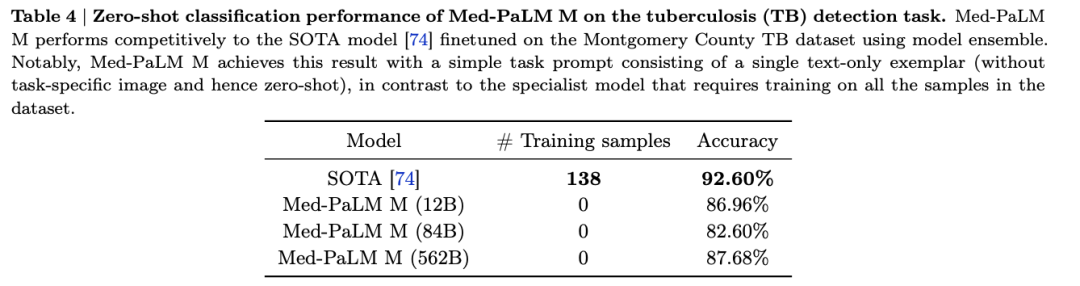
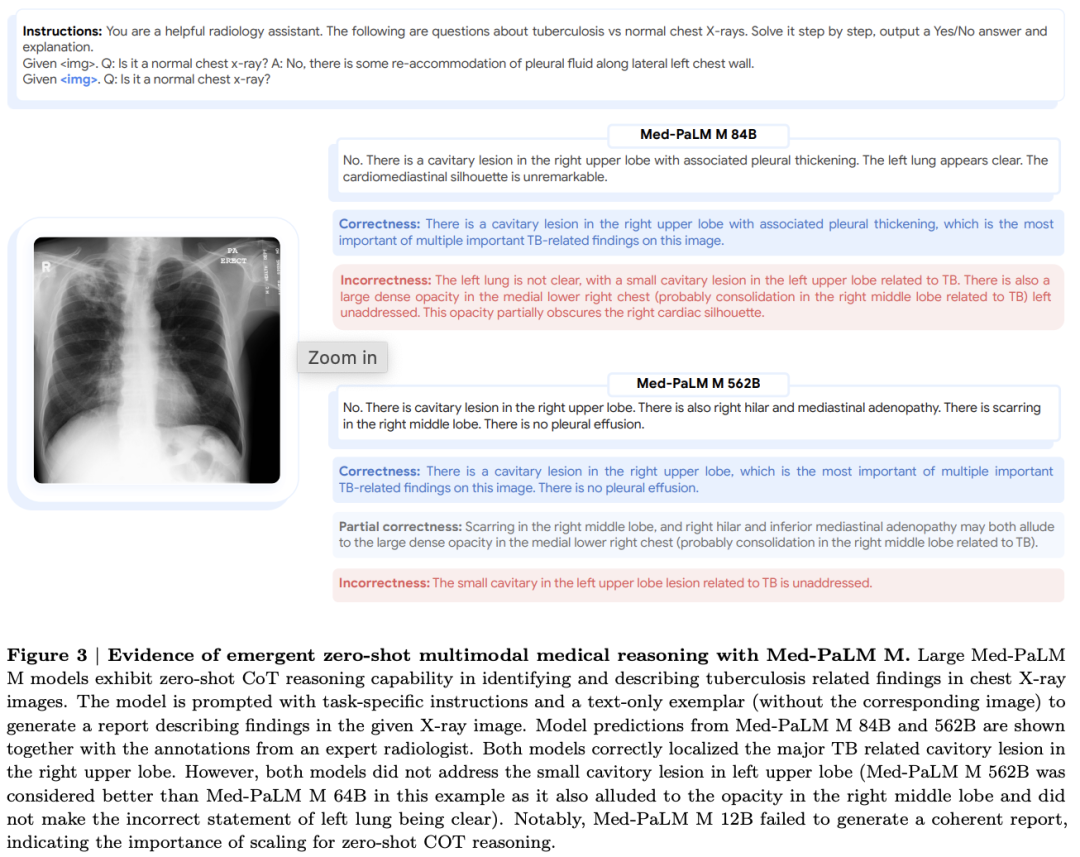
实验结果
实验结果

分享
收藏
点赞
在看
评论