
使用Redis来做缓存,你该知道的!
一、缓存一些知识
1.1、缓存击穿、缓存穿透、缓存雪崩是什么?
缓存击穿
用户请求的某个key在DB或者缓存中存在,但是可能正好在当这个key在缓存中到达了失效时间而过期,而此时大量访问该数据请求过来,相当于在缓存中凿开一个缺口,一下子全部打在DB上,造成DB压力压垮DB。

缓存穿透
用户通过请求一些缓存和DB中压根都不存在的数据,致使每次请求都会绕过缓存,请求DB,给DB带来压力
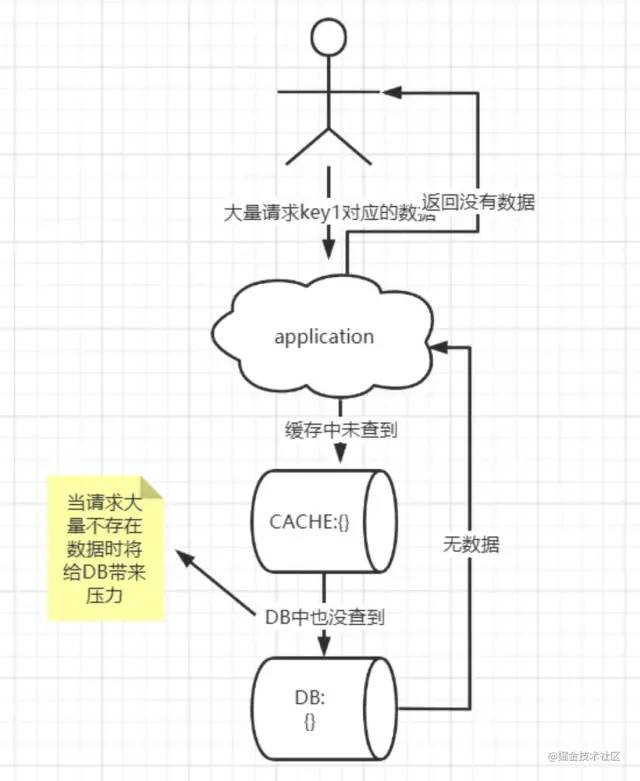
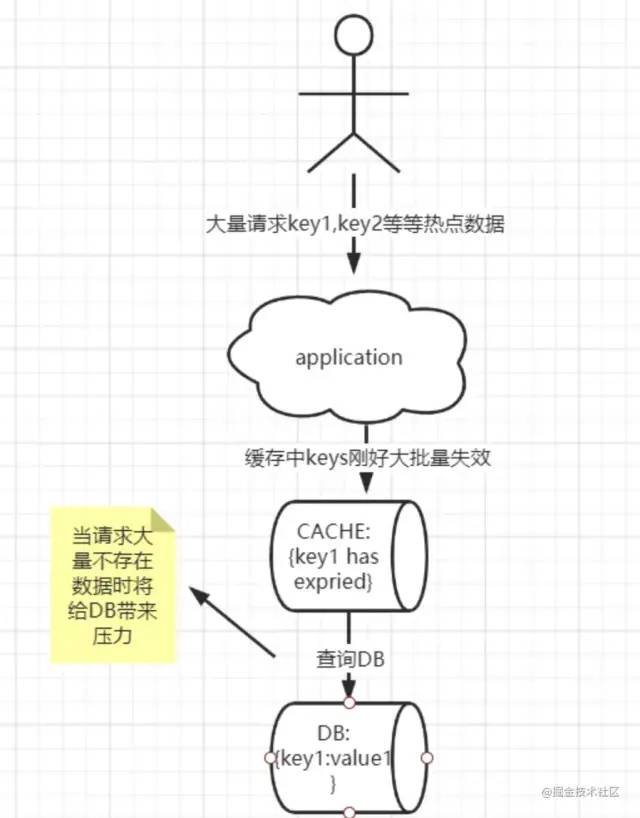
缓存雪崩
当缓存服务器重启或者大量缓存的keys过期失效,导致客户端过来的请求全部直接请求到DB中,造成DB压力大而崩溃(注意这里和缓存击穿不同的是缓存击穿是单个key失效引起,而雪崩是大量key失效)
1.2 应对缓存击穿
1)互斥锁访问数据
针对某一热点数据,在获取时可通过加互斥锁使得只有一个请求进行处理访问DB,并将数据放置到缓存中,后续阻塞的请求将直接命中缓存。
2)设置热点数据永不过期
1.3 应对缓存穿透
加强接口入参校验。将不合法入参抹杀在摇篮中
如果未查出数据,可赋予缓存中对应key一个null值,并设置一个过期时间,防止单位时间内大量请求访问DB。因为设置了过期时间,所以可以保证后续该key有值了,可以获取到。
1.4 应对缓存雪崩
1)设置缓存过期时间时,加上随机时间戳
这样做的好处就是尽量使得缓存key们的过期时间均匀分散,不至于在同一个时间点大面积缓存过期失效引起雪崩
2)不设置缓存过期时间
3)分布式缓存服务器部署的情况下,可以将热点数据分散在不同的缓存服务器中
二、redisLRU缓存机制
2.1 Redis内存淘汰机制
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 t,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最少使用的页面予以淘汰。----- 摘自百度百科
LRU缓存那就是将最近最少访问的缓存剔除。redis针对LRU机制提供了实现支持。redis在redis.conf中提供了配置选项maxmemory 来配置执行大小的内存数据集。或者在服务器运行时,可在客户端通过CONFIG SET进行设置。
maxmemory 100mb
复制代码如果设置为0,那么则表示内存不受限制。当往redis中存放值时,达到我们指定的maxmemory值时,redis提供了多种不同的剔除值策略。可以通过在redis.conf中配置策略
noeviction xxx
复制代码noeviction(default)
即当达到maxmemory内存限制时,不做数据剔除,直接返回错误
allkeys-lru
即当达到maxmemory内存限制时,删除最近最少使用的key以保证新的值可以添加进来
volatile-lru
即当达到maxmemory内存限制时,删除最近最少使用并且通过expire设置了过期时间的key,以保证新的值可以添加进来
allkeys-random
即当达到maxmemory内存限制时,随机删除一些key以保证新的值可以添加进来
volatile-random
即当达到maxmemory内存限制时,随机删除一些设置了过期时间的key以保证新的值可以添加进来
volatile-ttl
即当达到maxmemory内存限制时,删除一些设置了过期时间并且TTK所剩时间最短的keys以保证新的值可以添加进来
其中volatile-lru、volatile-random、volatile-ttl如果没有满足条件的key可以进行删除,那么它们的行为就和noeviction策略一样。剔除策略也可以在运行时进行设置。
2.2 Redis LRU淘汰机制精确度
在redis3.0之后,redis针对之前近似LRU算法进行了性能上的改进提升,以及使得LRU算法更加接近准确。通过配置参数maxmemory-samples可以调整样本的数量来为LRU算法获取精度。注意redis的LRU算法并不是LRU真正具体的实现,因为那很耗费内存。但是其实redis计算出的近似值于真实算法值是很相近的。
maxmemory-samples 5
复制代码
从上述Redis官方给的测试数据可以看出,同样样本数未5,redis3.0要比之前好一点,当提高样本数之后,更加的好一点,但是与真实LRU算法实现还是差点火候。
我们可以以额外的CPU使用为代价将样本大小增加到10,以接近真实的LRU,并检查这是否会对缓存漏报率产生影响。
在生产环境中,很容易通过CONFIG SET maxmemory-samples 命令来设置不同的样本值进行实验。
三、Redis结合Spring Cache Abstraction实现缓存
spring cache abstraction的更多使用spring知识之Spring Cache Abstraction的使用
实现缓存的思想其实并不复杂,简单点说,就是查询先从缓存服务器中查询,如果查询到则立即返回,否则再去DB中查询返回然后再放至到缓存当中;;在对数据进行更新操作时,操作DB成功以后,在决定缓存的更新策略(更新缓存or删除缓存)。
3.1 配置RedisCacheManager
spring-data-redis提供了spring抽象缓存的实现,为了借助于spring cache实现缓存,我们需要加载一个RedisCacheManager。
@Bean
public RedisCacheManager cacheManager(RedisConnectionFactory connectionFactory) {
return RedisCacheManager.create(connectionFactory);
}
复制代码通过RedisCacheManager.create创建出的是默认配置的RedisCacheManager,如果我们想设置一些事务或者预定义缓存则可通过builder进行构建。
3.1.1 自定义缓存配置RedisCacheConfiguration
RedisCacheConfiguration配置类,可以用来配置比如设置缓存key的过期时间、是否缓存null值、是否启用key前缀、以及key和value缓存过程中二进制数据 的序列化策略。
基本配置
// 默认缓存配置
RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig();
// 设置缓存key失效时间为2分钟
redisCacheConfiguration.entryTtl(Duration.ofMinutes(2));
// 禁用缓存null值(默认为启用)
redisCacheConfiguration.disableCachingNullValues();
// 禁用设置key前缀(默认为启用)
redisCacheConfiguration.disableKeyPrefix();
// 设置key前缀
redisCacheConfiguration.prefixCacheNameWith("miaomiao:");
复制代码key,value序列化策略
RedisCacheConfiguration默认key的序列化器是StringRedisSerializer,value的序列化器是JdkSerializationRedisSerializer
3.2 代码实操Srping Cache Abstranction
大致贴下各层demo。
entity(注意需要序列化)
@Entity
@Table(name = "user")
public class UserInfo implements Serializable {
@Id
@Column(name = "user_id")
private int userId;
@Column(name = "user_name")
private String userName;
get set 省略。。。
}
复制代码Dao
@Repository
public interface UserInfoRepository extends JpaRepository<UserInfo,Integer> {
}
复制代码Service
public interface UserInfoService {
Optional<UserInfo> getUserInfo(int userId);
}
复制代码@Service
public class UserInfoServiceImpl implements UserInfoService {
@Autowired
private UserInfoRepository userInfoRepository;
@Override
@Cacheable("user")
public Optional<UserInfo> getUserInfo(int userId) {
System.out.println("发生了真实调用!!!");
return userInfoRepository.findById(userId);
}
}
复制代码config(注意@EnableCaching启用缓存)
@Configuration
@EnableCaching
public class RedisCacheConfig {
@Bean
public RedisCacheManager cacheManager(RedisConnectionFactory redisConnectionFactory) {
// 默认缓存配置
RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig();
// 设置缓存key失效时间为2分钟
redisCacheConfiguration.entryTtl(Duration.ofMinutes(2));
// 禁用缓存null值(默认为启用)
redisCacheConfiguration.disableCachingNullValues();
return RedisCacheManager.builder(redisConnectionFactory).cacheDefaults(redisCacheConfiguration).build();
}
}
复制代码Test 以及输入
@SpringBootTest
public class UserInfoServiceImplTest {
@Autowired
private UserInfoService userInfoService;
@Test
public void getUserInfo() {
System.out.println("=========start1===========");
System.out.println(userInfoService.getUserInfo(1));
System.out.println("==========end1==========");
System.out.println("=========start2===========");
System.out.println(userInfoService.getUserInfo(1));
System.out.println("==========end2==========");
}
}
复制代码=========start1===========
发生了真实调用!!!
Hibernate: select userinfo0_.user_id as user_id1_0_0_, userinfo0_.user_name as user_nam2_0_0_ from user userinfo0_ where userinfo0_.user_id=?
Optional[UserInfo{userId=1, userName='cf'}]
==========end1==========
=========start2===========
Optional[UserInfo{userId=1, userName='cf'}]
==========end2==========
复制代码3.3 小结
从上述测试输出我们可以看出,在第一次进行调用(缓存中未存放相关值时,发生了真实调用,查库,然后返回结果),而第二次因为在第一次调用的基础上,缓存中已经有了值,所以直接将缓存结果返回,完全未触发真实的方法逻辑,所以这里也是很需要注意的地方,如果不太了解,只是跟着网上demo去使用,则可能发生将其他业务逻辑包杂在上述方法中,造成有缓存清空未调用导致bug等。
四、如何保障缓存DB一致性以及分布式数据一致性?
4.1 缓存和DB数据不一致场景(或者说诱因)
1)缓存和DB的操作不在一个事务中进行,很可能缓存的操作和DB的操作其中一个成功一个失败,导致数据不一致。2)多线程对缓存进行更新操作时,可能导致旧数据被更新至缓存中。
4.2 Cache Aside Pattern
当缓存失效时
即读缓存,未命中,则从数据库中取,成功之后将数据放到缓存中
当缓存命中时
即读缓存,若命中,则成功返回
当数据更新时
先更新数据库,然后删除缓存
着重与最后一条,当数据发生变化时,针对缓存如何进行处理?可能有以下几种情况:
先更新缓存,再更新数据库
此方案如果说更新数据库的时候,数据库宕机导致DB更新失败,造成了数据不一致
先更新数据库,再更新缓存
此方案主要存在两个问题:1).假如线程A先更新了数据,然后准备做更新数据库,更新缓存的操作,此时线程B也更新了相同的数据,更新数据库更新缓存。按道理线程B的数据应该是最新的,但是因为多线程的时序问题,很可能最终缓存被更新成了旧值。2).并不是所有缓存是热点数据,有可能此缓存不会被经常读取,而如果每次更新数据的时候,都要去更新一下缓存,就造成了不必要的性能和内存消耗。
先删除缓存,再更新数据库
developer.aliyun.com/article/712… 强推!!!!
参考文档
[1].docs.spring.io/spring-data…
[2].docs.spring.io/spring/docs…
[3].juejin.cn/post/684490…
作者:我有一只喵喵
链接:https://juejin.cn/post/6996820141405274142
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。