
千亿级高并发MongoDB集群在某头部金融机构中的应用及性能优化实践(上)
某头部金融机构采用MongoDB存储重要的金融数据,数据量较大,数据规模约2000亿左右,读写流量较高,峰值突破百万级/每秒。本文分享该千亿级高并发MongoDB集群的踩坑经验及性能优化实践,通过本文可以了解如下信息:
如何对海量MongoDB集群进行性能瓶颈定位?
千亿规模集群常用踩坑点有哪些?
如何对高并发大数据量MongoDB集群进行性能优化?
集群监控信息缺失,如何分析集群抖动问题?
如何像原厂工程师一样借助diagnose.data(not human-readable)分析内核问题?
业务背景及MongoDB FTDC诊断介绍
1►
业务背景
数据量大,该集群总数据量突破千亿规模 集群最大表总chunks数约500万 长时间高并发读写 一致性要求较高,读写全走主节点 高峰期持续性读写qps百万/秒 单分片峰值流量接近20万/秒 内核版本:3.6.3版本 非云上集群 除了节点日志,详细监控数据因历史原因缺失,无MongoDB常用监控指标信息
2►
MongoDB FTDC诊断数据简介
2.1 Full Time Diagnostic Data Capture
To facilitate analysis of the MongoDB server behavior by MongoDB Inc. engineers, mongod and mongos processes include a Full Time Diagnostic Data Collection (FTDC) mechanism. FTDC data files are compressed, are not human-readable, and inherit the same file access permissions as the MongoDB data files. Only users with access to FTDC data files can transmit the FTDC data. MongoDB Inc. engineers cannot access FTDC data independent of system owners or operators. MongoDB processes run with FTDC on by default. For more information on MongoDB Support options, visit Getting Started With MongoDB Support.
详见MongoDb官方FTDC实时诊断说明,地址:
2.2 diagnose.data目录结构
如下所示:
root@:/data1/xxxx/xxxx/db# lsTencetDTSData WiredTiger.lock WiredTiger.wt _mdb_catalog.wt area diagnostic.data local mongod.lock mongoshake storage.bson WiredTiger WiredTiger.turtle WiredTigerLAS.wt admin config journal maicai mongod.pid sizeStorer.wt testroot@:/data1/xxxx/xxxx/db#root@:/data1/xxxx/xxxx/db#root@:/data1/xxxx/xxxx/db#root@:/data1/xxxx/xxxx/db#
diagnostic.data目录中按照时间记录各种不同诊断信息到metrics文件,除了metrics.interim文件,其他文件内容大约10M左右。
root@:/data1/xxxx/xxx/db/diagnostic.data#root@:/data1/xxxx/xxxx/db/diagnostic.data# lsmetrics.xxxx-12-27T02-28-58Z-00000 metrics.xxxx-12-28T14-33-57Z-00000metrics.xxxx-12-30T04-28-57Z-00000 metrics.xxxx-12-31T17-08-57Z-00000metrics.xxxx-01-02T05-28-57Z-00000 metrics.xxxx-12-27T09-18-58Z-00000metrics.xxxx-12-28T23-13-57Z-00000 metrics.xxxx-12-30T11-23-57Z-00000metrics.xxxx-01-01T00-53-57Z-00000 metrics.interimmetrics.xxxx-12-27T16-28-57Z-00000 metrics.xxxx-12-29T06-08-57Z-00000metrics.xxxx-12-30T19-18-57Z-00000 metrics.xxxx-01-01T07-23-57Z-00000metrics.xxxx-12-28T00-48-57Z-00000 metrics.xxxx-12-29T12-58-57Z-00000metrics.xxxx-12-31T02-58-57Z-00000 metrics.xxxx-01-01T14-18-57Z-00000metrics.xxxx-12-28T07-38-57Z-00000 metrics.xxxx-12-29T21-18-57Z-00000metrics.xxxx-12-31T09-48-57Z-00000 metrics.xxxx-01-01T22-38-57Z-00000root@:/data1/xxx/xxxx/db/diagnostic.data#root@:/data1/xxxx/xxxx/db/diagnostic.data#
集群踩坑过程及优化方法
3►
memlock不足引起的节点崩掉及解决办法
Xxxx 12 22:51:28.891 F - [conn7625] Failed to mlock: Cannot allocate memoryXxxx 12 22:51:28.891 F - [conn7625] Fatal Assertion 28832 at src/mongo/base/secure_allocator.cpp 246Xxxx 12 22:51:28.891 F - [conn7625]***aborting after fassert() failureXxxx 12 22:51:28.918 F - [conn7625] Got signal: 6 (Aborted)...........----- BEGIN BACKTRACE -----{"backtrace":libc.so.6(abort+0x148) [0x7fccf1b898c8]mongod(_ZN5mongo32fassertFailedNoTraceWithLocationEiPKcj+0x0) [0x7fccf3b33ed2]mongod(_ZN5mongo24secure_allocator_details8allocateEmm+0x59D) [0x7fccf51d6d6d]mongod(_ZN5mongo31SaslSCRAMServerConversationImplINS_8SHABlockINS_15SHA1BlockTraitsEEEE26initAndValidateCredentialsEv+0x167) [0x7fccf4148ca7]mongod(_ZN5mongo27SaslSCRAMServerConversation10_firstStepENS_10StringDataEPNSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEEE+0x959) [0x7fccf414dcd9]mongod(_ZN5mongo27SaslSCRAMServerConversation4stepENS_10StringDataEPNSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEEE+0x9B) [0x7fccf414eecb]mongod(_ZN5mongo31NativeSaslAuthenticationSession4stepENS_10StringDataEPNSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEEE+0x3C) [0x7fccf414731c]mongod(+0xF355CD) [0x7fccf41405cd]mongod(+0xF37D3A) [0x7fccf4142d3a]mongod(_ZN5mongo12BasicCommand11enhancedRunEPNS_16OperationContextERKNS_12OpMsgRequestERNS_14BSONObjBuilderE+0x76) [0x7fccf4cefde6]
//disabledSecureAllocatorDomains配置初始化配置ExportedServerParameter<std::vector<std::string>, ServerParameterType::kStartupOnly>SecureAllocatorDomains(ServerParameterSet::getGlobal(),"disabledSecureAllocatorDomains",&serverGlobalParams.disabledSecureAllocatorDomains);template <typename NameTrait>struct TraitNamedDomain {//该接口在SecureAllocatorDomain类中的相关接口中生效,决定走mlock流程还是普通malloc流程static bool peg() {const auto& dsmd = serverGlobalParams.disabledSecureAllocatorDomains;const auto contains = [&](StringData dt) {return std::find(dsmd.begin(), dsmd.end(), dt) != dsmd.end();};//注意这里,如果disabledSecureAllocatorDomains配置为*,直接falsestatic const bool ret = !(contains("*"_sd) || contains(NameTrait::DomainType));return ret;}};void deallocate(pointer ptr, size_type n) {return secure_allocator_details::deallocateWrapper(//peg()决定是走mlock流程还是普通malloc流程static_cast<void*>(ptr), sizeof(value_type) * n, DomainTraits::peg());}inline void* allocateWrapper(std::size_t bytes, std::size_t alignOf, bool secure) {if (secure) {//最终走mlock流程return allocate(bytes, alignOf);} else {//走std::malloc普通内存分配流程return mongoMalloc(bytes);}}
Memlock内存方式
普通malloc内存方式
setParameter:disabledSecureAllocatorDomains: '*'
4►
压力过大引起的主从切换及优化方法
Xxxx 11 12:02:19.125 I ASIO [NetworkInterfaceASIO-RS-0] Ending connection to host x.x.x.x:11200 due to bad connection status; 2 connections to that host remain openXxxx 11 12:02:19.125 I REPL [replication-18302] Restarting oplog query due to error: NetworkInterfaceExceededTimeLimit: error in fetcher batch callback :: caused by :: Operation timed out. Last fetched optime (with hash): { ts: Timestamp(1649926929, 5296), t: 31 }[-1846165485094137853]. Restarts remaining: 3Xxxx 11 12:02:19.125 I REPL [replication-18302] Scheduled new oplog query Fetcher source: x.x.x.x:11200 database: local query: { find: "oplog.rs", filter: { ts: { $gte: Timestamp(1649926929, 5296) } }, tailable: true, oplogReplay: true, awaitData: true, maxTimeMS: 60000, batchSize: 13981010, term: 31, readConcern: { afterClusterTime: Timestamp(1649926929, 5296) } } query metadata: { $replData: 1, $oplogQueryData: 1, $readPreference: { mode: "secondaryPreferred" } } active: 1 findNetworkTimeout: 65000ms getMoreNetworkTimeout: 10000ms shutting down?: 0 first: 1 firstCommandScheduler: RemoteCommandRetryScheduler request: RemoteCommand 3332431257 -- target:x.x.x.x:11200 db:local cmd:{ find: "oplog.rs", filter: { ts: { $gte: Timestamp(1649926929, 5296) } }, tailable: true, oplogReplay: true, awaitData: true, maxTimeMS: 60000, batchSize: 13981010, term: 31, readConcern: { afterClusterTime: Timestamp(1649926929, 5296) } } active: 1 callbackHandle.valid: 1 callbackHandle.cancelled: 0 attempt: 1 retryPolicy: RetryPolicyImpl maxAttempts: 1 maxTimeMillis: -1msXxxx 11 12:02:20.211 I REPL [replexec-4628] Starting an election, since we've seen no PRIMARY in the past 10000msXxxx 11 12:02:20.211 I REPL [replexec-4628] conducting a dry run election to see if we could be elected. current term: 31Xxxx 11 12:02:20.215 I ASIO [NetworkInterfaceASIO-Replication-0] Connecting to x.x.x.x:11200Xxxx 11 12:02:20.393 I REPL [replexec-4620] VoteRequester(term 31 dry run) received a yes vote from 10.22.13.85:11200; response message: { term: 31, voteGranted: true, reason: "", ok: 1.0, operationTime: Timestamp(1649926929, 5296), $gleStats: { lastOpTime: Timestamp(0, 0), electionId: ObjectId('7fffffff000000000000001b') }, $clusterTime: { clusterTime: Timestamp(1649926932, 3), signature: { hash: BinData(0, 0000000000000000000000000000000000000000), keyId: 0 } }, $configServerState: { opTime: { ts: Timestamp(1649926932, 3), t: 1 } } }Xxxx 11 12:02:20.393 I REPL [replexec-4620] dry election run succeeded, running for election in term 32Xxxx 11 12:02:20.474 I REPL_HB [replexec-4628] Error in heartbeat (requestId: 3332431247) to x.x.x.x:11200, response status: NetworkInterfaceExceededTimeLimit: Operation timed outXxxx 11 12:02:20.474 I REPL [replexec-4628] Member x.x.x.x:11200 is now in state RS_DOWNXxxx 11 12:02:20.477 I REPL [replexec-4628] VoteRequester(term 32) received a no vote from x.x.x.x:11200 with reason "candidate's data is staler than mine. candidate's last applied OpTime: { ts: Timestamp(1649926929, 5296), t: 31 }, my last applied OpTime: { ts: Timestamp(1649926940, 5), t: 31 }"; response message: { term: 31, voteGranted: false, reason: "candidate's data is staler than mine. candidate's last applied OpTime: { ts: Timestamp(1649926929, 5296), t: 31 }, my last applied OpTime: { ts: Times...", ok: 1.0, operationTime: Timestamp(1649926940, 5), $gleStats: { lastOpTime: Timestamp(0, 0), electionId: ObjectId('7fffffff000000000000001f') }, $clusterTime: { clusterTime: Timestamp(1649926940, 6), signature: { hash: BinData(0, 0000000000000000000000000000000000000000), keyId: 0 } }, $configServerState: { opTime: { ts: Timestamp(1649926937, 2), t: 1 } } }Xxxx 11 12:02:20.629 I REPL [replexec-4620] election succeeded, assuming primary role in term 32Xxxx 11 12:02:20.630 I REPL [replexec-4620] transition to PRIMARY from SECONDARY
网络抖动
主节点hang住
主压力过大

从上面的打印结果可以看出,在切换前一段时间的流量较高,该分片主节点读写流量超过15W/s,used内存逐渐接近95%。但是很遗憾,接近切换前一分钟内的mongostat监控没有获取到,对应报错信息如下:
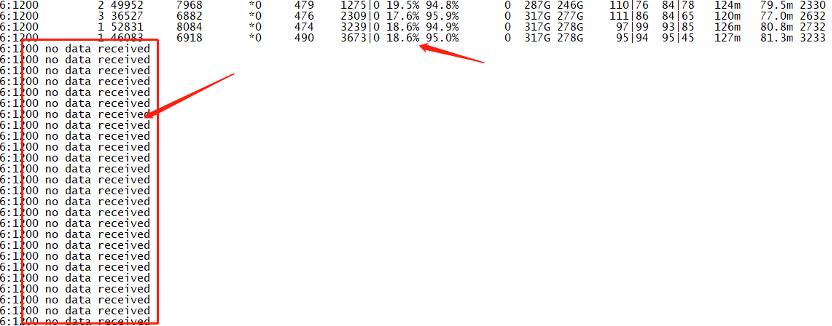
从上面的mongostat监控看出,随着userd使用越来越高,用户线程开始阻塞并进行脏数据淘汰,读写性能也有所下降,qrw、arw活跃队列和等待队列也越来越高。通过这些现象可以基本确认请求排队越来越严重,由于临近主从切换时间点附近的mongostat数据没有获取到,因此解析diagnose.data诊断数据确定根因。
主节点降级为从节点前30秒和后15秒的读写活跃队列诊断数据如下(左图为读活跃队列数,右图为写活跃队列数):
|
|


上图为读写活跃请求数,也就是mongostat监控中的arw。同时分析diagnose.data中的读写等待队列,其结果如下(左图为读等待队列,右图为写等待队列):
|
|


业务梳理优化
内核优化
cfg = rs.conf()cfg.settings.heartbeatTimeoutSecs=20cfg.settings.electionTimeoutMillis=20000rs.reconfig(cfg)
5►
节点十秒级hang住问题诊断及优化
Xxxx 11 10:08:22.107 I COMMAND [conn15350423] command xx.xxx command: find ........................... protocol:op_msg 92417ms.............Xxxx 11 10:08:22.108 I COMMAND [conn15271960] serverStatus was very slow: { after basic: 0, after asserts: 0, after backgroundFlushing: 0, after connections: 0, after dur: 0, after extra_info: 0, after globalLock: 0, after locks: 0, after logicalSessionRecordCache: 0, after network: 0, after opLatencies: 0, after opcounters: 0, after opcountersRepl: 0, after repl: 0, after sharding: 0, after shardingStatistics: 0, after storageEngine: 0, after tcmalloc: 11515, after transactions: 11515, after wiredTiger: 11565, at end: 11565 }.........Xxxx 11 10:08:22.109 I COMMAND [conn15350423] command xx.xxxx command: find ........................... protocol:op_msg 112417msXxxx 11 10:08:22.109 I COMMAND [conn15350423] command xxx.xxx command: find ........................... protocol:op_msg 116417ms
从上面日志可以看出,ftdc诊断模块已提示时延消耗主要集中在tcmalloc模块,也就是tcmalloc模块hang住引起了整个实例请求等待。于是解析对应时间点diagnose.data诊断数据,hang住异常时间点前后的tcmalloc诊断数据如下:

如上图所示,异常时间点tcmalloc模块缓存的内存十秒钟内瞬间一次性释放了接近40G内存,因此造成了整个节点hang住。
优化方法:实时pageHeap释放,避免一次性大量cache集中式释放引起节点hang住,MongoDB实时加速释放对应内存命令如下,可通过tcmallocReleaseRate控制释放速度:
db.adminCommand( { setParameter: 1, tcmallocReleaseRate: 5.0 } )该命令可以加快释放速度,部分MongoDB内核版本不支持,如果不支持也可以通过下面的命令来进行激进的内存释放:
db.adminCommand({setParameter:1,tcmallocAggressiveMemoryDecommit:1})6►
切换成功后新主数十分钟不可用问题及优化
该集群除了遇到前面的几个问题外,还遇到了一个更严重的问题,主从切换后数十分钟不可用问题。下面我们开始结合日志和诊断数据分析新主数十分钟不可用问题根因:
6.1 问题现象
6.1.1 主从切换过程
主从切换日志如下:
Xxx xxx 8 23:43:28.043 I REPL [replication-4655] Restarting oplog query due to error: NetworkInterfaceExceededTimeLimit: error in fetcher batch callback :: caused by :: Operation timed out. Last fetched optime (with hash): { ts: Timestamp(1644334998, 110), t: 10 }[3906139038645227612]. Restarts remaining: 3Xxx xxx 8 23:43:36.439 I REPL [replexec-8667] Starting an election, since we've seen no PRIMARY in the past 10000msXxx xxx 8 23:43:36.439 I REPL [replexec-8667] conducting a dry run election to see if we could be elected. current term: 10.....Xxx xxx 8 23:43:44.260 I REPL [replexec-8666] election succeeded, assuming primary role in term 11.....Xxx xxx 8 23:43:44.261 I REPL [replexec-8666] transition to PRIMARY from SECONDARYXxx xxx 8 23:43:44.261 I REPL [replexec-8666] Entering primary catch-up mode.
从上面的日志可以,从节点发现主节点保活超时,大约15秒钟内快速被提升为新的主节点,整个过程一切正常。
6.1.2 快速切主成功后,业务访问半小时不可用
集群由于流量过大,已提前关闭balance功能。但是,从节点切主后,业务访问全部hang住,试着kill请求、手动HA、节点重启等都无法解决问题。下面是一次完整主从切换后集群不可用的日志记录及其分析过程,包括路由刷新过程、访问hang住记录等。
MongoDB内核路由模块覆盖分片集群分布式功能的所有流程,功能极其复杂。鉴于篇幅,下面只分析其中核心流程。
切主后新主hang住半小时,切主hang住核心日志如下:
Xxxx 9 00:16:22.728 I COMMAND [conn359980] command db_xx.collection_xx command: find ....... ,shardVersion: [ Timestamp(42277, 3330213) ,ObjectId('61a355b18444860129c524ec') ] numYields:0 ok:0 errMsg:"shard version not ok: version epoch mismatch detected for DBXX.COLLECTIONXX, the collection may have been dropped and recreated" errName:StaleConfig errCode:13388 reslen:570 timeAcquiringMicros: { r: 1277246 } protocol:op_msg 1941243msXxxx 9 00:16:22.728 I COMMAND [conn359980] command db_xx.collection_xx command: find ....... ,shardVersion: [ Timestamp(42277, 3330213) ,ObjectId('61a355b18444860129c524ec') ] numYields:0 ok:0 errMsg:"shard version not ok: version epoch mismatch detected for DBXX.COLLECTIONXX, the collection may have been dropped and recreated" errName:StaleConfig errCode:13388 reslen:570 timeAcquiringMicros: { r: 1277246 } protocol:op_msg 1923443msXxxx 9 00:16:22.728 I COMMAND [conn359980] command db_xx.collection_xx command: find ....... ,shardVersion: [ Timestamp(42277, 3330213) ,ObjectId('61a355b18444860129c524ec') ]numYields:0 ok:0 errMsg:"shard version not ok: version epoch mismatch detected for DBXX.COLLECTIONXX, the collection may have been dropped and recreated" errName:StaleConfig errCode:13388 reslen:570 timeAcquiringMicros: { r: 1277246 } protocol:op_msg 1831553msXxxx 9 00:16:22.728 I COMMAND [conn359980] command db_xx.collection_xx command: find ....... ,shardVersion: [ Timestamp(42277, 3330213) ,ObjectId('61a355b18444860129c524ec') ] numYields:0 ok:0 errMsg:"shard version not ok: version epoch mismatch detected for DBXX.COLLECTIONXX, the collection may have been dropped and recreated" errName:StaleConfig errCode:13388 reslen:570 timeAcquiringMicros: { r: 1277246 } protocol:op_msg 1751243msXxxx 9 00:16:22.728 I COMMAND [conn359980] command db_xx.collection_xx command: find ....... ,shardVersion: [ Timestamp(42277, 3330213) ,ObjectId('61a355b18444860129c524ec') ]numYields:0 ok:0 errMsg:"shard version not ok: version epoch mismatch detected for DBXX.COLLECTIONXX, the collection may have been dropped and recreated" errName:StaleConfig errCode:13388 reslen:570 timeAcquiringMicros: { r: 1277246 } protocol:op_msg 1954243ms
从日志中可以看出,所有用户请求都hang住了。
从节点切主后路由刷新过程核心日志,切主后,新主刷路由核心流程如下:
Xxx xxx 8 23:43:53.306 I SHARDING [conn357594] Refreshing chunks for collection db_xx.collection_xx based on version 0|0||000000000000000000000000Xxxx 9 00:15:47.486 I SHARDING [ConfigServerCatalogCacheLoader-0] Cache loader remotely refreshed for collection db_xx.collection_xx from collection version 42227|53397||ada355b18444860129css4ec and found collection version 42277|53430||ada355b18444860129css4ecXxxx 9 00:16:06.352 I SHARDING [ConfigServerCatalogCacheLoader-0] Cache loader found enqueued metadata from 42227|53397||ada355b18444860129css4ec to 42277|53430||ada355b18444860129css4ec and persisted metadata from 185|504||ada355b18444860129css4ec to 42277|53430||ada355b18444860129css4ec , GTE cache version 0|0||000000000000000000000000Xxxx 9 00:16:21.550 I SHARDING [ConfigServerCatalogCacheLoader-0] Refresh for collection db_xx.collection_xx took 1948243 ms and found version 42277|53430||ada355b18444860129css4ec
上面的刷路由过程主要时间段如下:
第一阶段:从远端config server获取全量或者增量路由信息(持续32分钟)
23:43:53 - 00:15:47,持续时间约32分钟。
第二阶段:把获取到的增量chunks路由信息持久化到本地(持续时间约20秒)
第三阶段:加载本地cache.chunks表中的路由信息到内存(持续时间15秒)
通过上面的日志分析,基本上可以确认问题是由于主从切换后路由刷新引起,但是整个过程持续30分钟左右,业务30分钟左右不可用,这确实不可接受。
6.1.3 切主后路由刷新核心原理
MongoDB内核路由刷新流程比较复杂,这里只分析3.6.3版本切主后的路由刷新主要流程:
1. mongos携带本地最新的shard版本信息转发给shard server
例如上面日志中的mongos携带的路由版本信息为:shardVersion: [ Timestamp(42277, 3330213) ,ObjectId('61a355b18444860129c524ec') ],shardVersion中的42277为该表路由大版本号,3330213为路由小版本号;ObjectId代表一个具体表,表不删除不修改,该id一直不变。
2. 新主进行路由版本检测
新主收到mongos转发的请求后,从本地内存中获取该表版本信息,然后和mongos携带shardVersion版本号做比较,如果mongos转发的主版本号比本地内存中的高,则说明本节点路由信息不是最新的,因此就需要从config server获取最新的路由版本信息。
3. 进入路由刷新流程
第一个请求到来后,进行路由版本检测,发现本地版本低于接受到的版本,则进入刷新路由流程。进入该流程前加锁,后续路由刷新交由ConfigServerCatalogCacheLoader线程池处理,第一个请求线程和后面的所有请求线程等待线程池异步获取路由信息。
6.2 切主数十分钟hang住问题优化方法
构造500万chunk,然后模拟集群主从切换刷路由流程,通过验证可以复现上一节刷路由的第二阶段20秒和第三阶段15秒时延消耗,但是第一阶段的32分钟时延消耗始终无法复现。
6.2.1 刷路由代码走读确认32分钟hang住问题
到这里,没辙,只能走读内核代码,通过走读内核代码发现该版本在第一阶段从config server获取变化的路由信息持久化到本地config.cache.chunks.db_xx.collection_xx表时,会增加一个waitForLinearizableReadConcern逻辑,对应代码如下:
Status ShardServerCatalogCacheLoader::_ensureMajorityPrimaryAndScheduleTask(OperationContext* opCtx, const NamespaceString& nss, Task task) {//写一个noop到多数派节点成功才返回,如果这时候主从延迟过高,则这里会卡顿Status linearizableReadStatus = waitForLinearizableReadConcern(opCtx);if (!linearizableReadStatus.isOK()) {return {linearizableReadStatus.code(),str::stream() << "Unable to schedule routing table update because this is not the"<< " majority primary and may not have the latest data. Error: "<< linearizableReadStatus.reason()};}//继续处理后续逻辑......}
从上面代码可以看出,在把获取到的增量路由信息持久化到本地config.cache.chunks表的时候会写入一个noop空操作到local.oplog.rs表,当noop空操作同步到大部分从节点后,该函数返回,否则一直阻塞等待。
6.2.2 诊断数据确认hang住过程是否由主从延迟引起
上面代码走读怀疑从config server获取增量路由信息由于主从延迟造成整个流程阻塞,由于该集群没有主从延迟相关监控,并且异常时间点mongostat信息缺失,为了确认集群异常时间点是否真的有主从延迟存在,因此只能借助diagnose.data诊断数据来分析。
由于主节点已经hang住,不会有读写流量,如果主节点流量为0,并且从节点有大量的回放opcountersRepl.insert统计,则说明确实有主从延迟。刷路由hang住恢复时间点前35秒左右的opcountersRepl.insert增量诊断数据如下:

从节点回放完成时间点,和刷路由hang住恢复时间点一致,从诊断数据可以确认问题由主从延迟引起。
6.2.3 模拟主从延迟情况下手动触发路由刷新复现问题
为了进一步验证确认主从延迟对刷路由的影响,搭建分片集群,向该集群写入百万chunks,然后进行如下操作,手动触发主节点进行路由刷新:
1. 添加anyAction权限账号。
2. 通过mongos修改config.chunks表,手动修改一个chunk的主版本号为当前shardversion主版本号+1。
3. Shard server主节点中的所有节点设置为延迟节点,延迟时间1小时。
4. 通过mongos访问属于该chunk的一条数据。
通过mongos访问该chunk数据,mongos会携带最新的shardVersion发送给主节点,这时候主节点发现本地主版本号比mongos携带的请求版本号低,就会进入从config server获取最新路由信息的流程,最终走到waitForLinearizableReadConcern等待一个noop操作同步到多数节点的逻辑,由于这时候两个从节点都是延迟节点,因此会一直阻塞
通过验证,当取消从节点的延迟属性,mongos访问数据立刻返回了。从这个验证逻辑可以看出,主从延迟会影响刷路由逻辑,最终造成请求阻塞。
说明:3.6.8版本开始去掉了刷路由需要等待多数派写成功的逻辑,不会再有因为主从延迟引起的刷路由阻塞问题。
6.3.3 刷路由阻塞优化方法
1. 事前优化方法:避免切主进入路由刷新流程
前面提到该集群只会在主从切换的时候触发路由刷新,由于该集群各个分片balance比较均衡,因此关闭了balance,这样就不会进行moveChunk操作,表对应的shardVserion主版本号不会变化。
但是,由于该业务对一致性要求较高,因此只会读写主节点。路由元数据默认持久化在cache.chunks.dbxx.collectionxx表中,内存中记录路由信息是一种“惰性”加载过程,由于从节点没有读流量访问该表,因此内存中的该表的元数据版本信息一直为0,也就是日志中的”GTE cache version 0|0||000000000000000000000000”,切主后内存元数据版本同样为0。当用户通过mongos访问新主的时候版本号肯定小于mongos转发携带的版本号,进而会进入路由刷新流程。
Chunk路由信息存储在cache.chunks.dbxx.collectionxx表中,从节点实时同步主节点该表的数据,但是该数据没有加载到从内存元数据中。如果我们在切主之前提前把cache.chunks表中持久化的路由数据加载到内存中,这样切主后就可以保证和集群该表的最新版本信息一致,同时通过mongos访问该主节点的时候因为版本信息一致,就不会进入路由刷新流程,从而优化规避切主进行路由刷新的流程。
结合3.6.3版本MongoDB内核代码,内核只有在用户请求同时带有以下参数的情况下才会从对应从节点进行路由版本检查并加载cache.chunks表中持久化的最新版本信息到内存元数据中:
请求带有读写分离配置
请求携带readConcern: { level:
}配置或者请求携带afterClusterTime参数信息
从节点进行版本检测判断及路由刷新流程核心代码如下:
void execCommandDatabase(…) {......if (!opCtx->getClient()->isInDirectClient() &&readConcernArgs.getLevel() != repl::ReadConcernLevel::kAvailableReadConcern &&(iAmPrimary ||((serverGlobalParams.featureCompatibility.getVersion() ==ServerGlobalParams::FeatureCompatibility::Version::kFullyUpgradedTo36) &&//如果是从节点,则需要请求携带readConcern: { level:}配置 // 或者请求携带afterClusterTime参数信息(readConcernArgs.hasLevel() || readConcernArgs.getArgsClusterTime())))) {//获取版本信息,并记录下来oss.initializeShardVersion(NamespaceString(command>parseNs(dbname, request.body)), shardVersionFieldIdx);......}//刷新元数据信息,例如表对应chunk路由信息等Status ShardingState::onStaleShardVersion(…) {......//本地的shardversion和代理mongos发送过来的做比较,如果本地缓存的//版本号比mongos的高,则啥也不做不用刷新元数据if (collectionShardVersion.epoch() == expectedVersion.epoch() &&collectionShardVersion >= expectedVersion) {return Status::OK();}//如果本地路由版本比接收到的低,则直接进入路由刷新流程refreshMetadata(opCtx, nss);......}
use dbxxdb.getMongo().setReadPref('secondary')//访问分片1从节点数据db.collectionxx.find({"_id" : ObjectId("xxx")}).readConcern("local")......//访问分片n从节点数据db.collectionxx.find({"_id" : ObjectId("xxx")}).readConcern("local")
登录新主
rs.printSlaveReplicationInfo()查看主从延迟
确认有延迟的从节点
rs.remove()剔除有延迟的从节点
﹀
﹀
﹀

亿级月活全民K歌Feed业务在腾讯云MongoDB中的应用及优化实践

叮咚买菜自建MangoDB上腾讯云实践