
唐杉博士:人工智能芯片发展及挑战

清华大数据软件团队官方微信公众号 来源:DataFunTalk 本文约4200字,建议阅读10分钟
本文与你讨论人工智能芯片的架构特征、发展趋势、以及AI DSA架构给AI软件栈带来的挑战。

Al DSA产生的背景和产业现状 百花齐放的Al DSA硬件 Al DSA软件栈面临的挑战
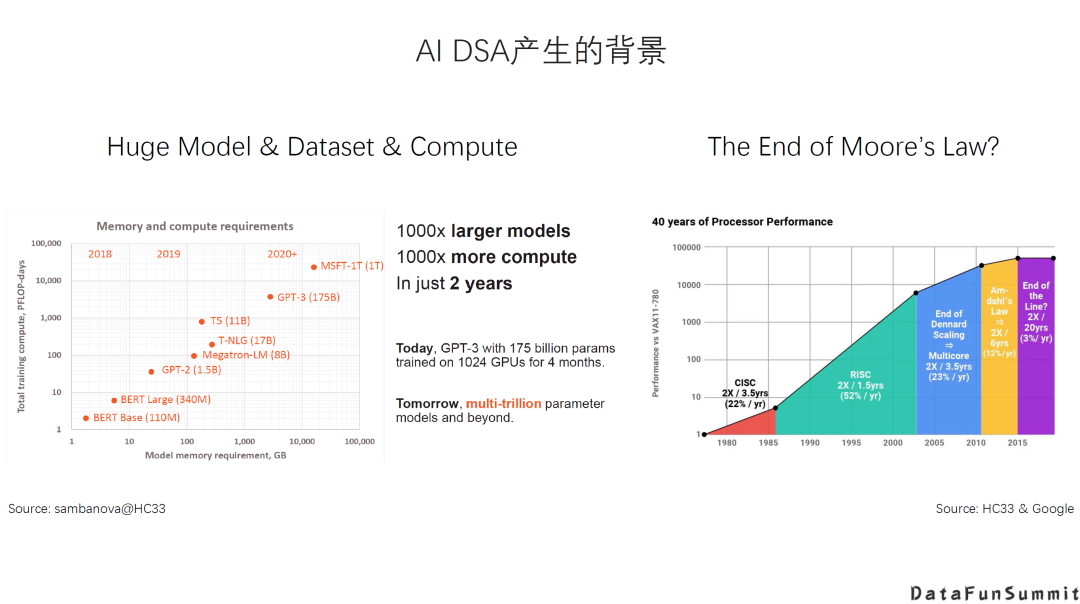

不论是模型的规模还是算力需求,都是呈指数形式的增长。同时,由于摩尔定律放缓,通用处理器的性能提升已经十分有限。因此,计算需求与处理能力的提升之间存在较大的GAP。 第二,AI计算现在无处不在,AI计算任务多样且复杂。例如,在云上、边缘侧与端设备上,不同的场景下面包括不同的训练和推理的需求,差异是非常大的。在云上进行训练,可能需要非常高的吞吐量,非常高的精度,以及非常强的扩展性等等;而在端上,情况更加复杂,会有计算量需求巨大的情况,如自动驾驶可能需要P级算力;同时,也会有能耗和成本非常受限的应用,像可穿戴设备中的AI计算等等。
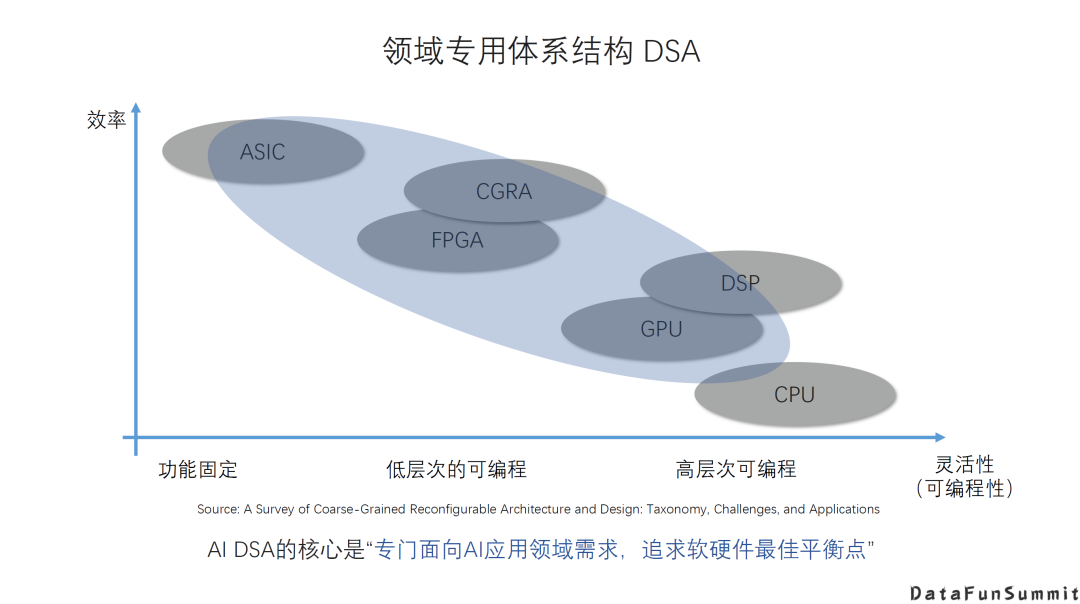
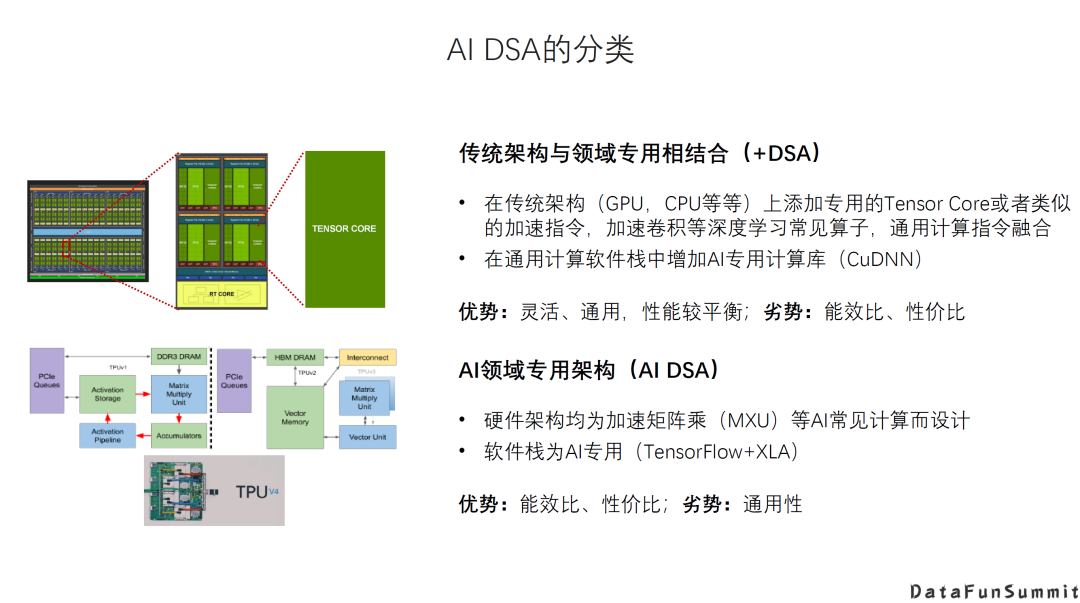
传统架构+DSA。在传统架构的基础上增加新的DSA的硬件以及相应的指令。例如GPU增加Tensor Core这种专用的加速器。它的优势是灵活通用,性能比较平衡,而劣势是相对更专用的DSA在特定应用场景下的能效比、性价比。 Al领域专用架构,即针对AI的新架构。例如Google TPU,它的设计是专门针对有限的AI应用场景,牺牲一定的通用性和灵活性来换取更高的能效或者性价比。
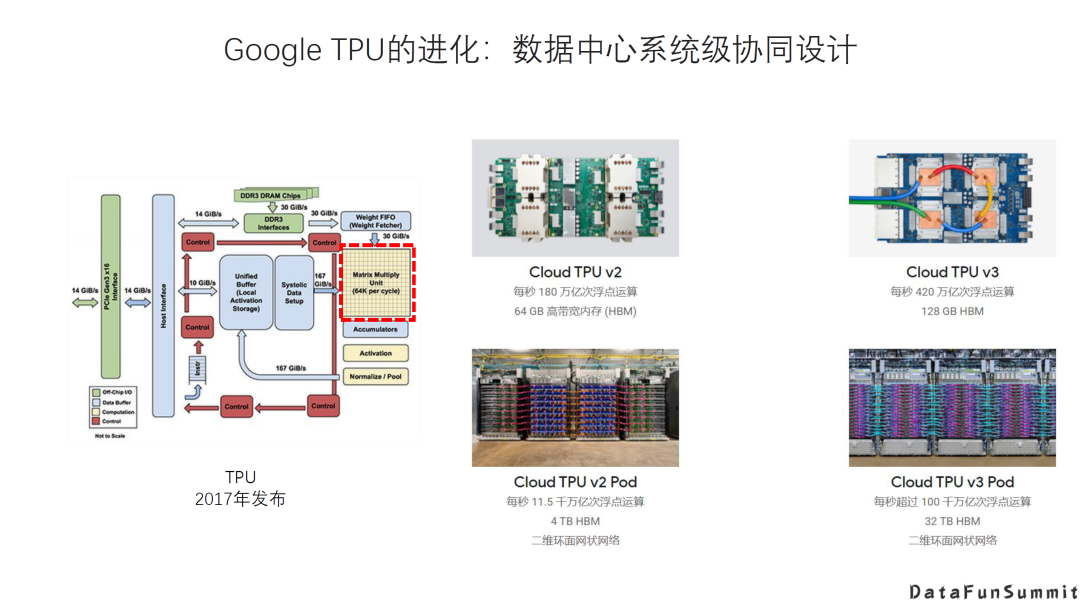
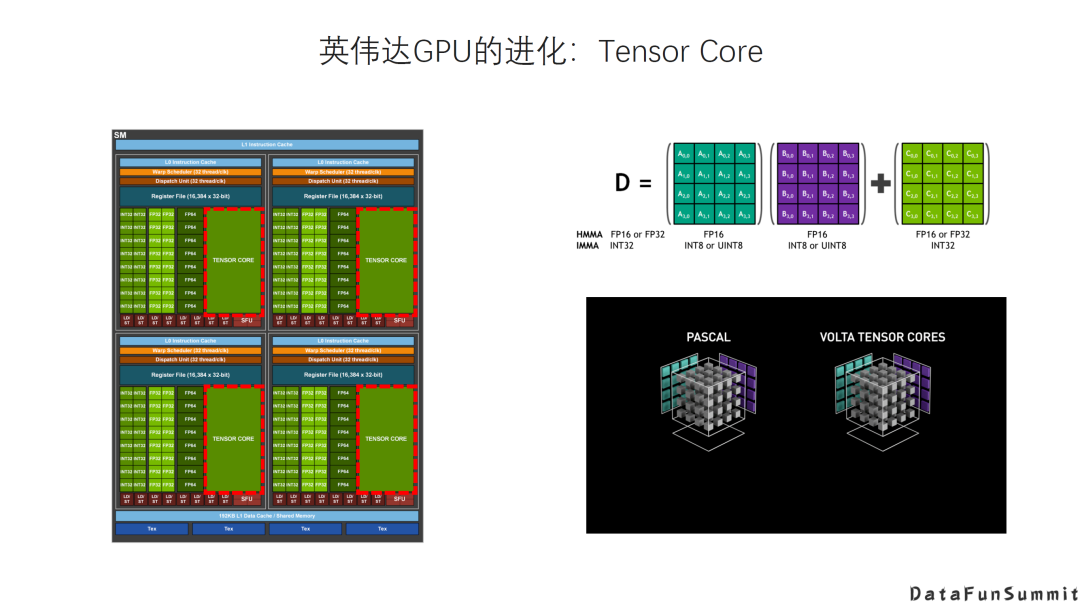
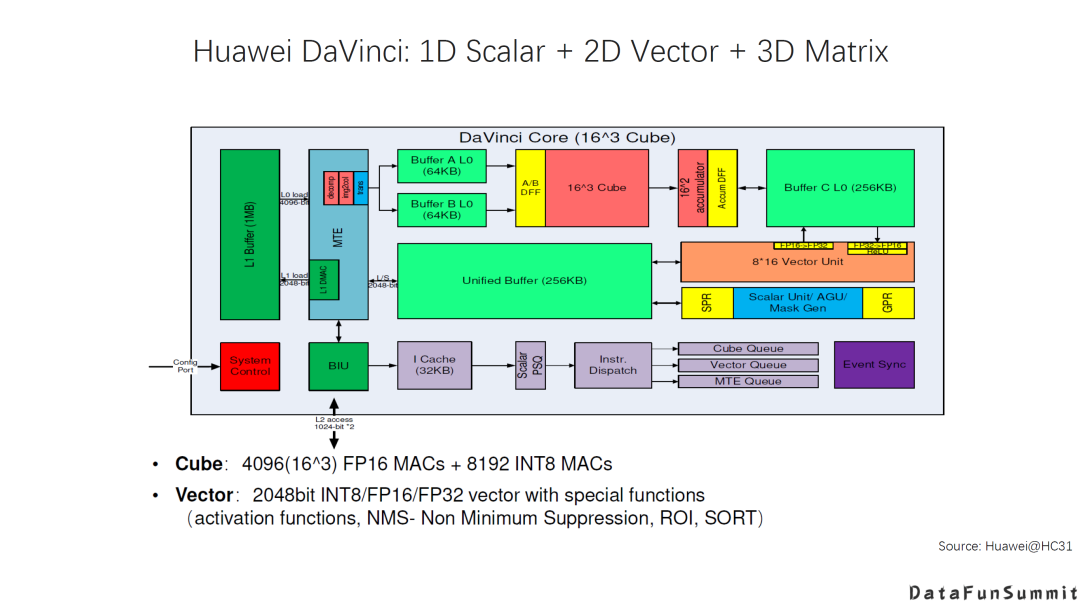


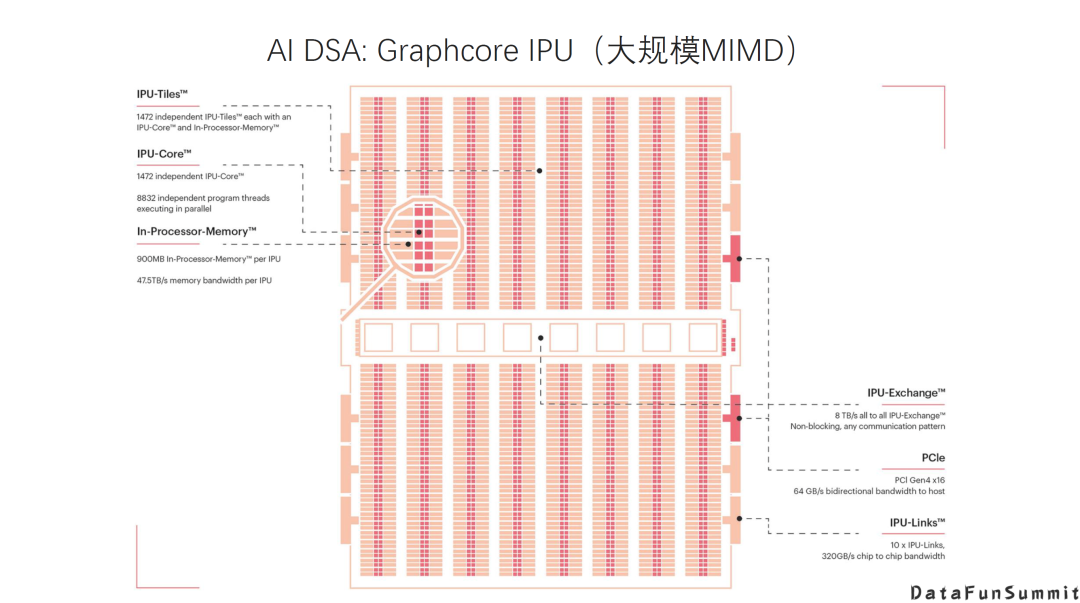


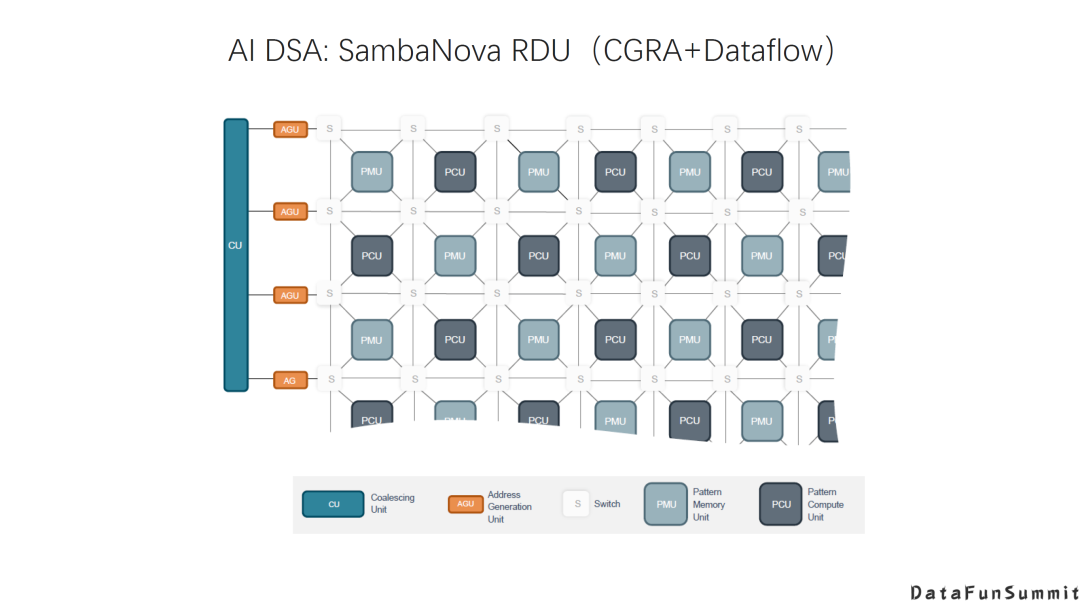

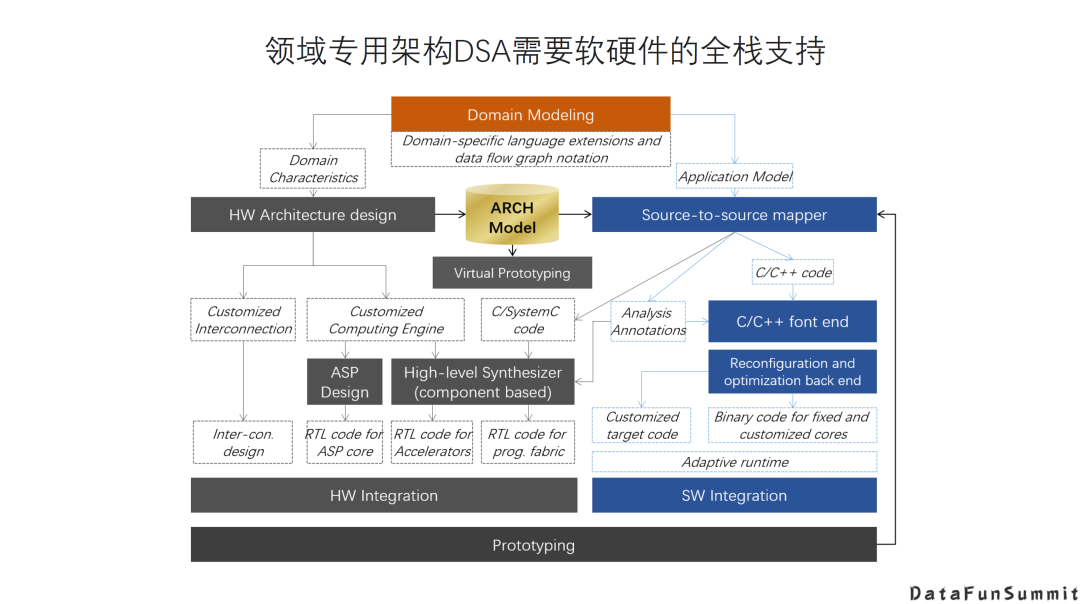
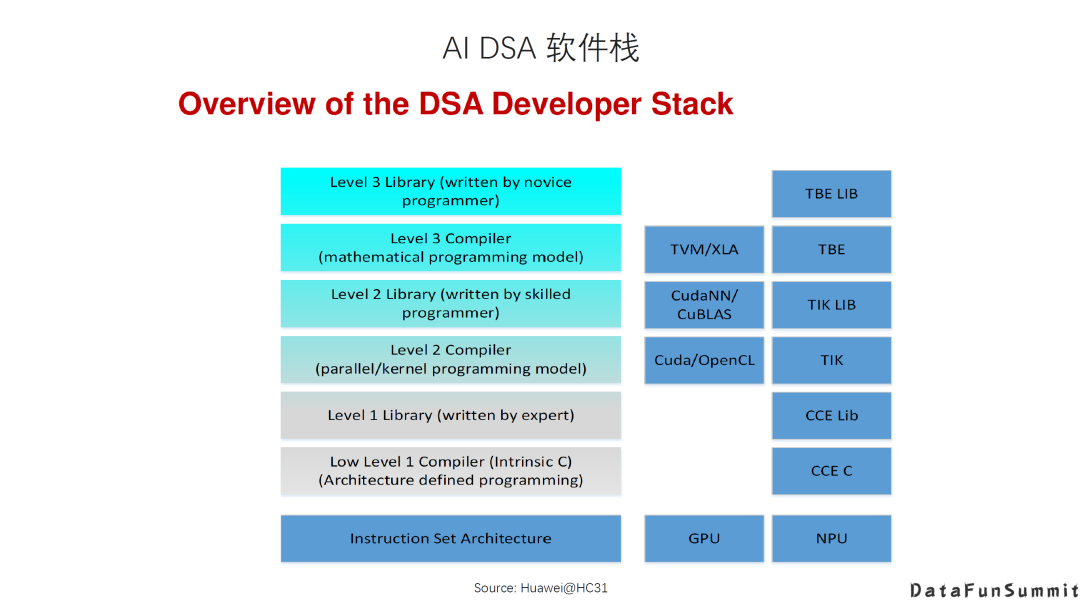
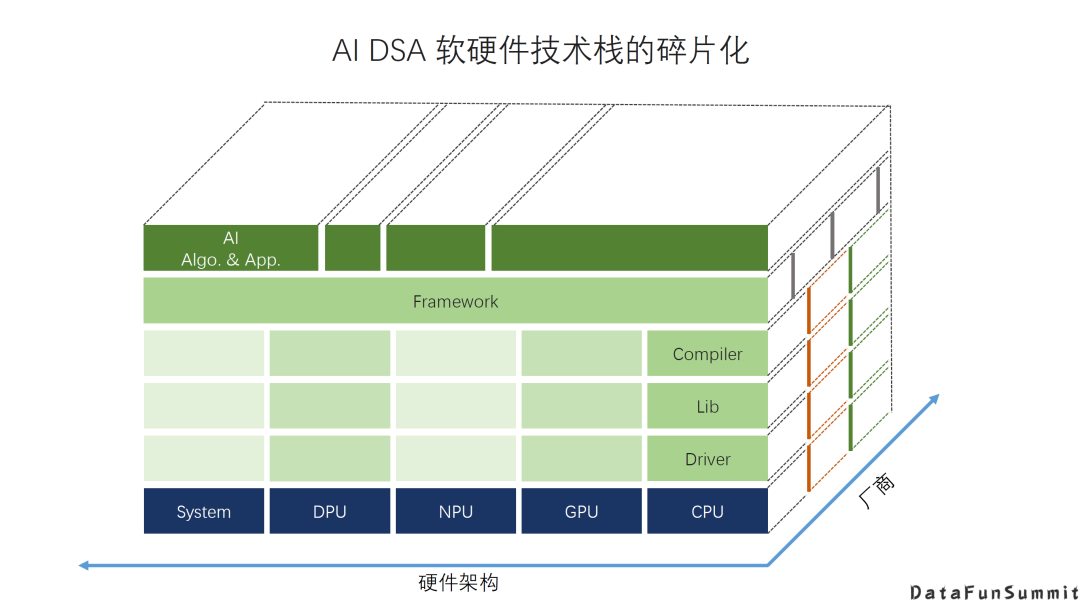
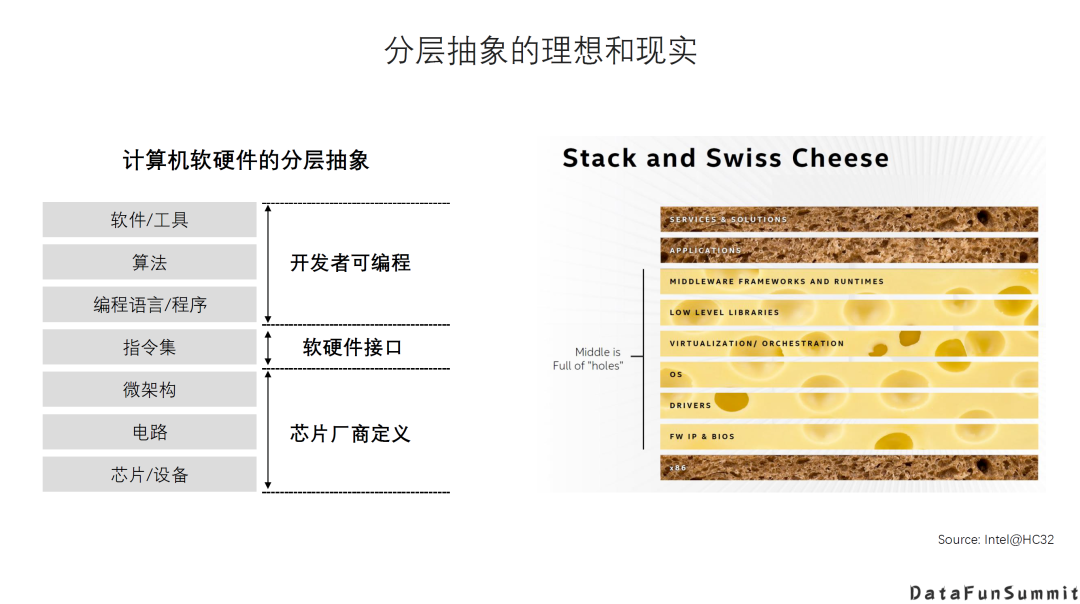
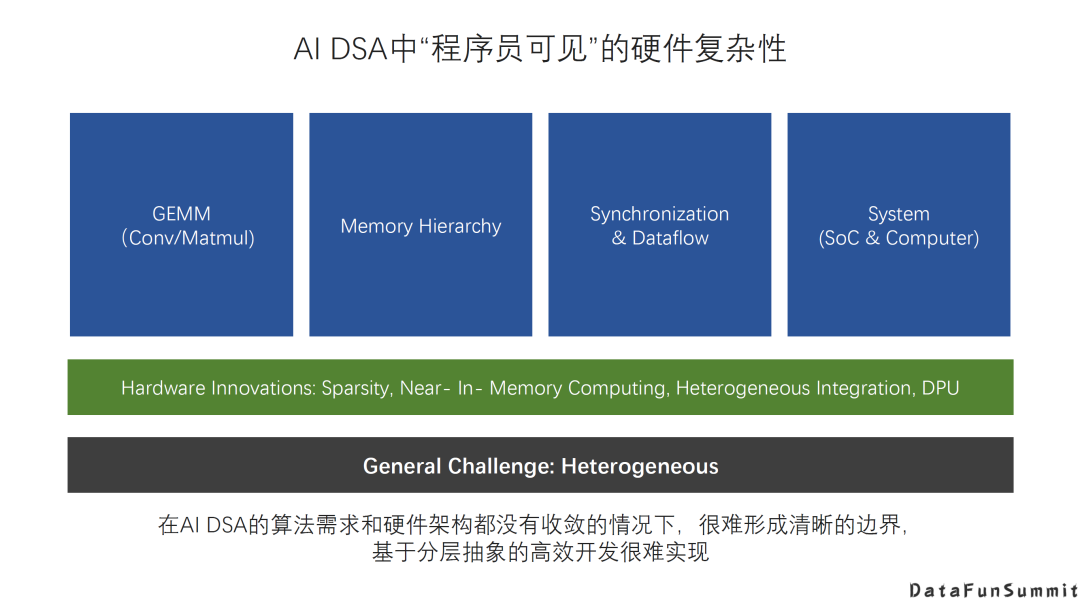
AI DSA诞生的大背景是:传统通用芯片无法满足新的计算模式的需求; AI DAS需要实现软硬件的全栈解决方案; AI DSA的发展方向取决于AI算法和应用的发展以及底层芯片技术的支撑,未来很长一段时间仍然可能是多种架构并存; 由于软件硬件不同层次间还无法形成清晰的边界,巨大的软硬件的设计空间混杂在一起,给设计和优化带来巨大挑战; 硬件架构的创新最终是以一个完整的软硬件技术栈提供给用户的,如果没有好的软件支持,硬件创新无法产生真正的收益。
编辑:黄继彦
校对:林亦霖
评论