
实时性语义分割算法大盘点

极市导读
语义图像分割是计算机视觉中发展最快的领域之一,有着广泛的应用。本文以24篇相关论文作为切入点,总结汇总了多种实时性语义分割的算法,非常值得分享收藏。>>加入极市CV技术交流群,走在计算机视觉的最前沿
语义分割论文
分类,即将图像中最具代表性的物体归为某一个类; 带有定位的分类,对分类任务的一个扩展,使用边界框将对象框起来在分类; 目标检测,对多个不同类型的对象进行分类和定位; 语义分割,是对图像中的每个像素进行分类和定位; 实例分割,是语义分割的扩展,在实例分割中,相同类型的不同对象被视为不同的对象; 全景分割,结合语义分割和实例分割,所有像素被分配一个类标签,所有对象实例都被独立分割
【1】自主驾驶车辆实时语义分割的比较研究
【2】高效的语义分割CNN设计技术分析
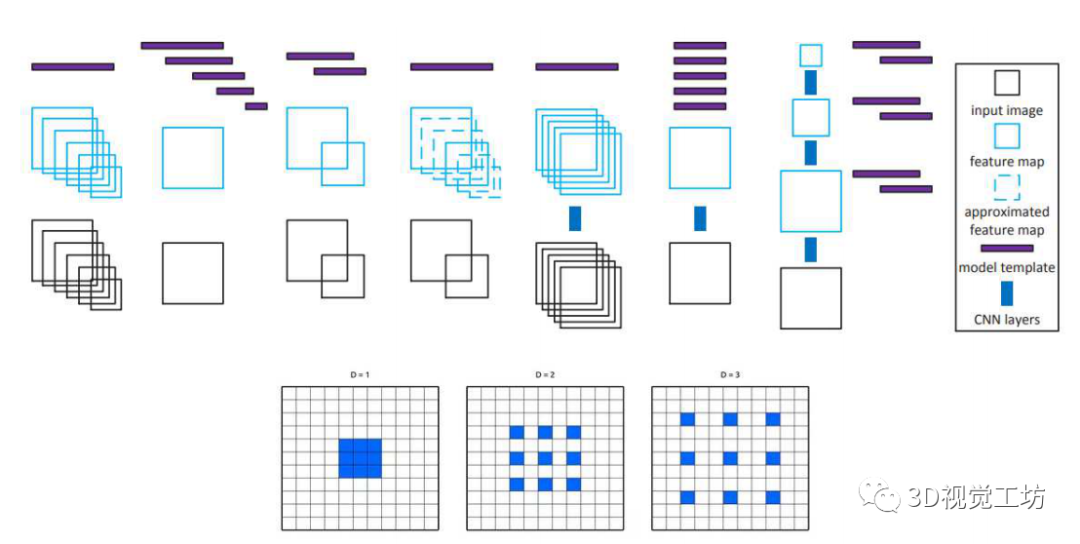

1x1卷积降维,减少卷积的输入通道数 Group convolution Depth-wise Separable convolution
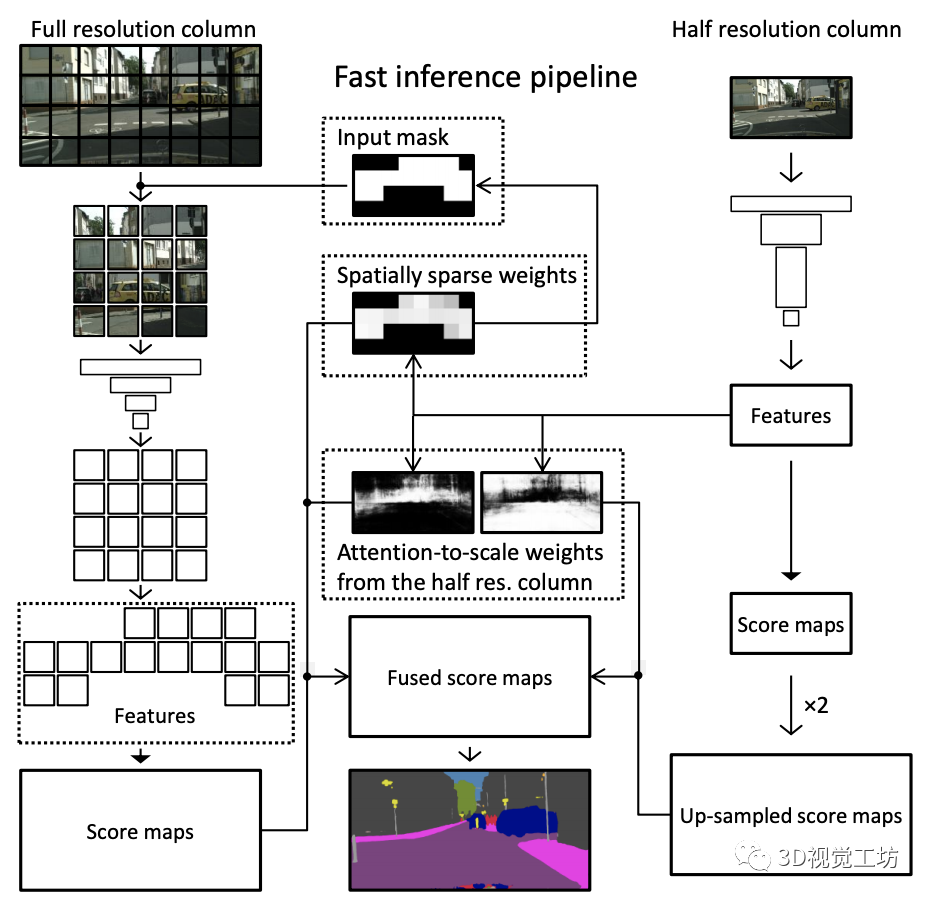
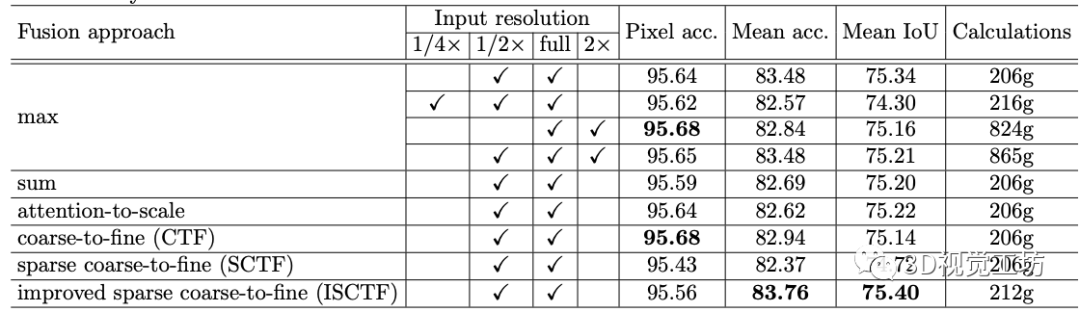
【3】基于空间稀疏性的实时语义图像分割

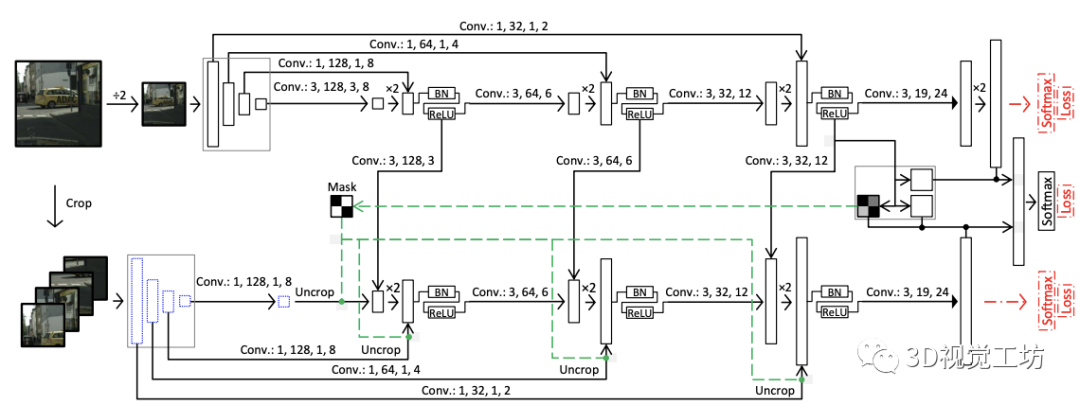
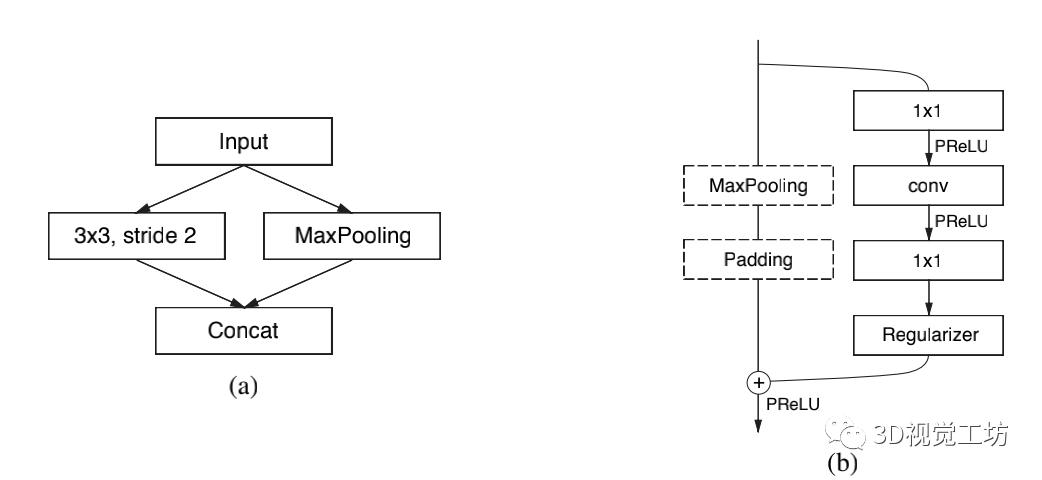
【4】ENet:一种用于实时语义分割的深度神经网络架构

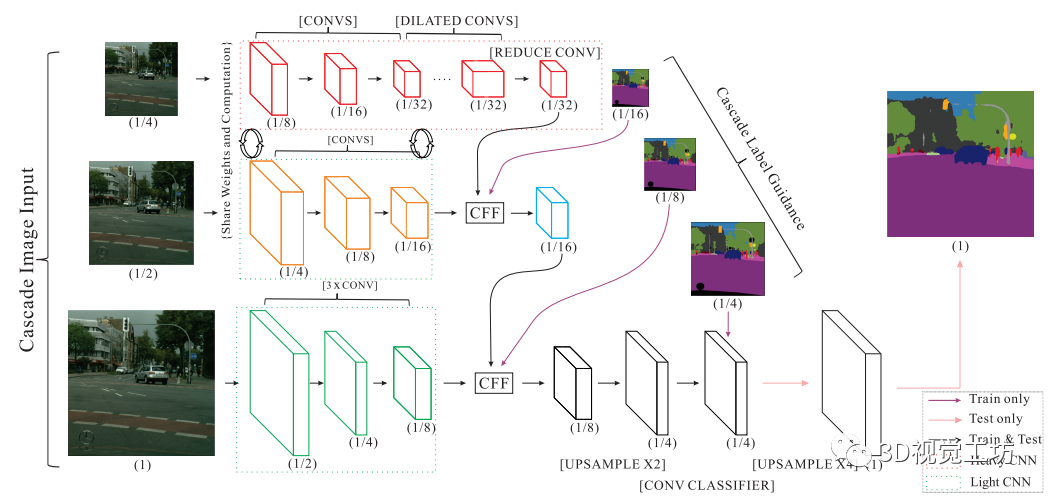
【5】ICNet用于高分辨率图像的实时语义分割

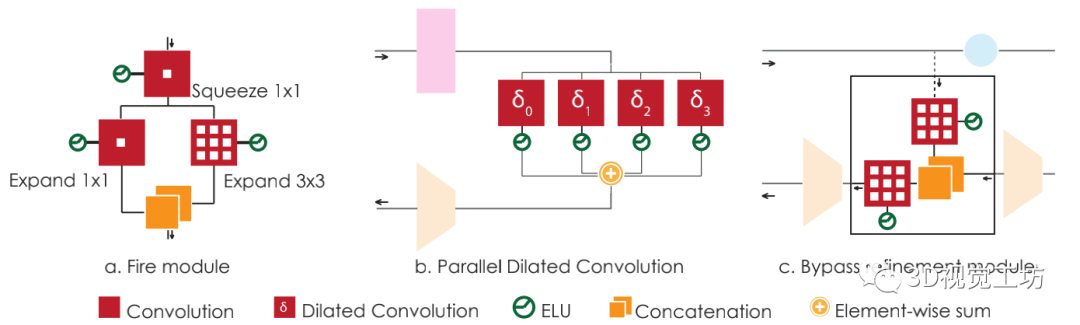
【6】加速自动驾驶的语义分割


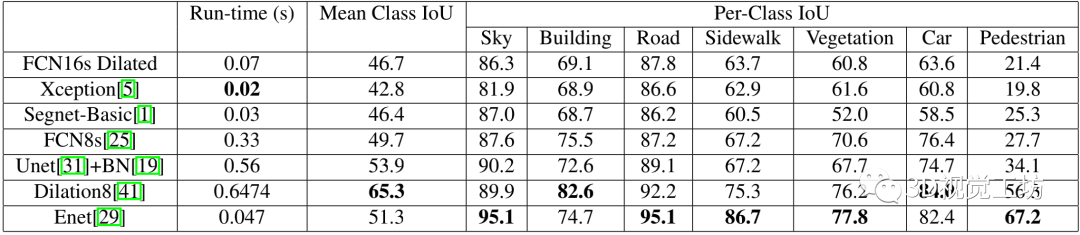
【7】高效卷积网络用于实时语义分割
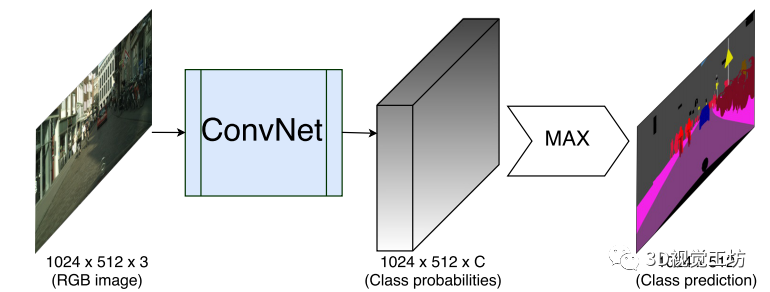
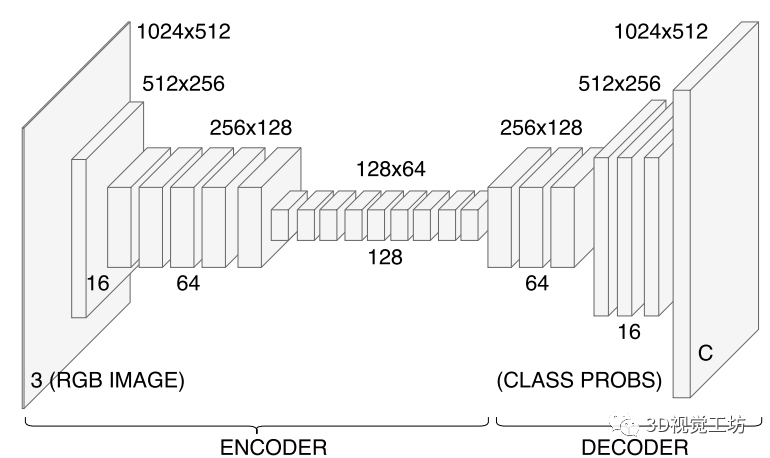

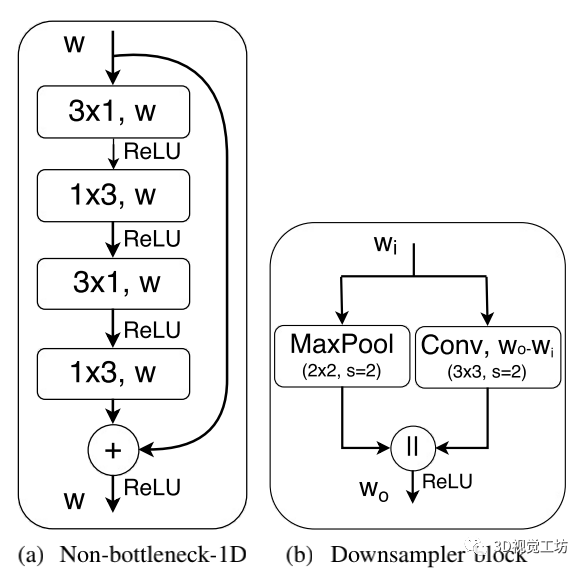


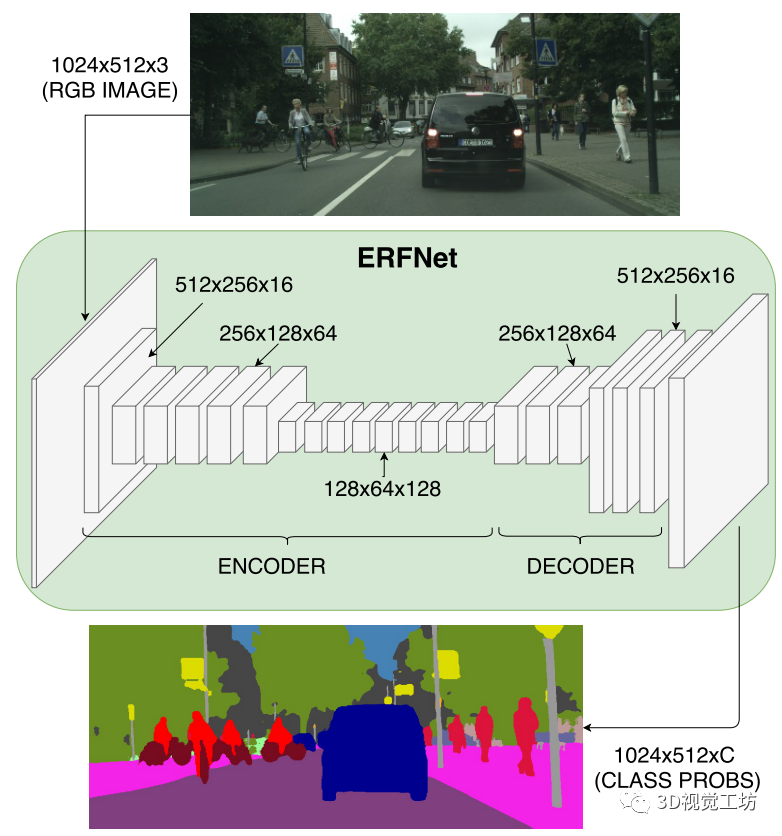
【8】ERFNet:用于实时语义分割的高效残差分解卷积网络

【9】EDANet:用于实时语义分割的高效的非对称卷积密集模块


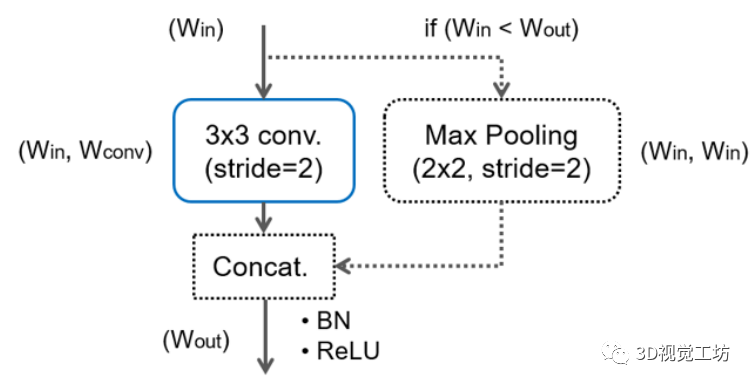
【10】ESPNet:扩展卷积的高效空间金字塔语义分割


【11】ESPNetv2:一个轻量级、高效、通用的卷积神经网络
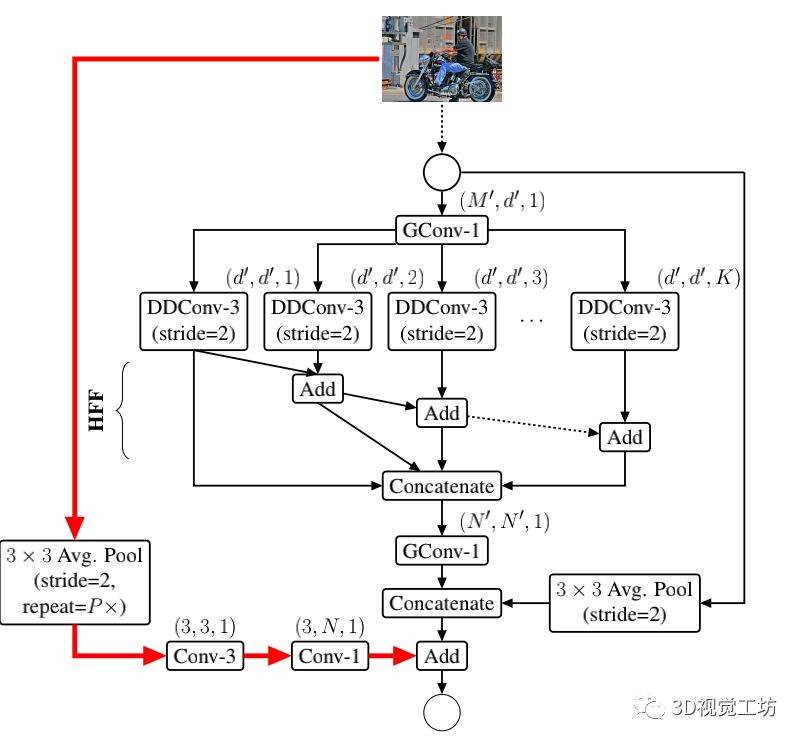
【12】轻量级语义分段的集中综合卷积
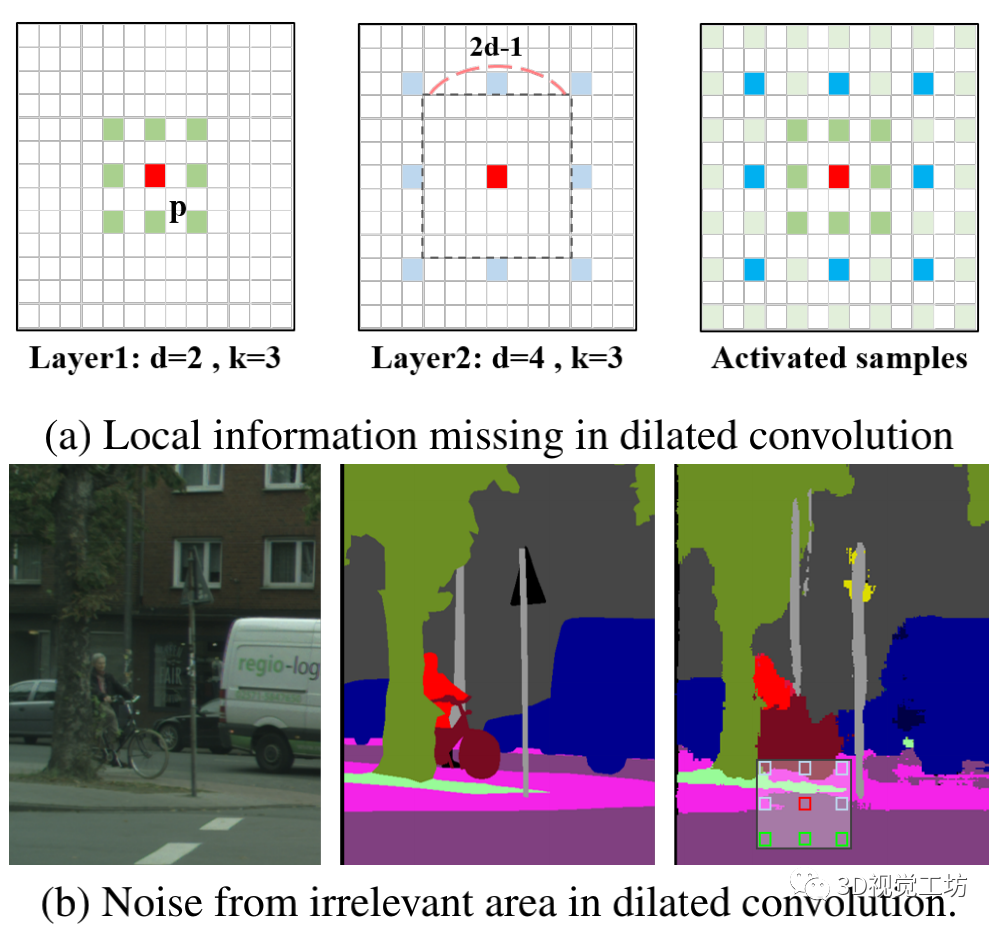
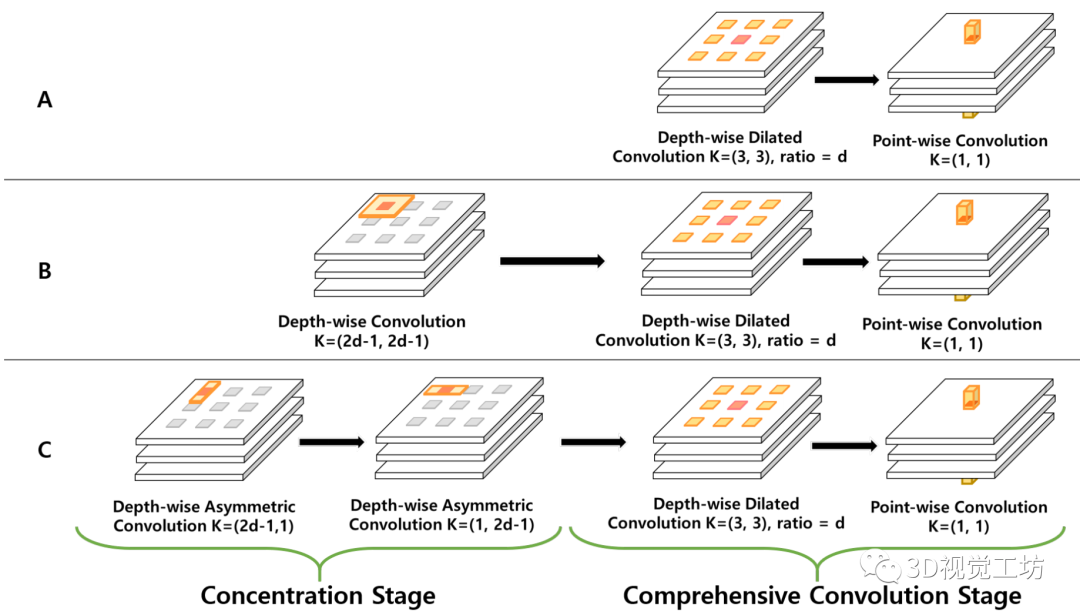
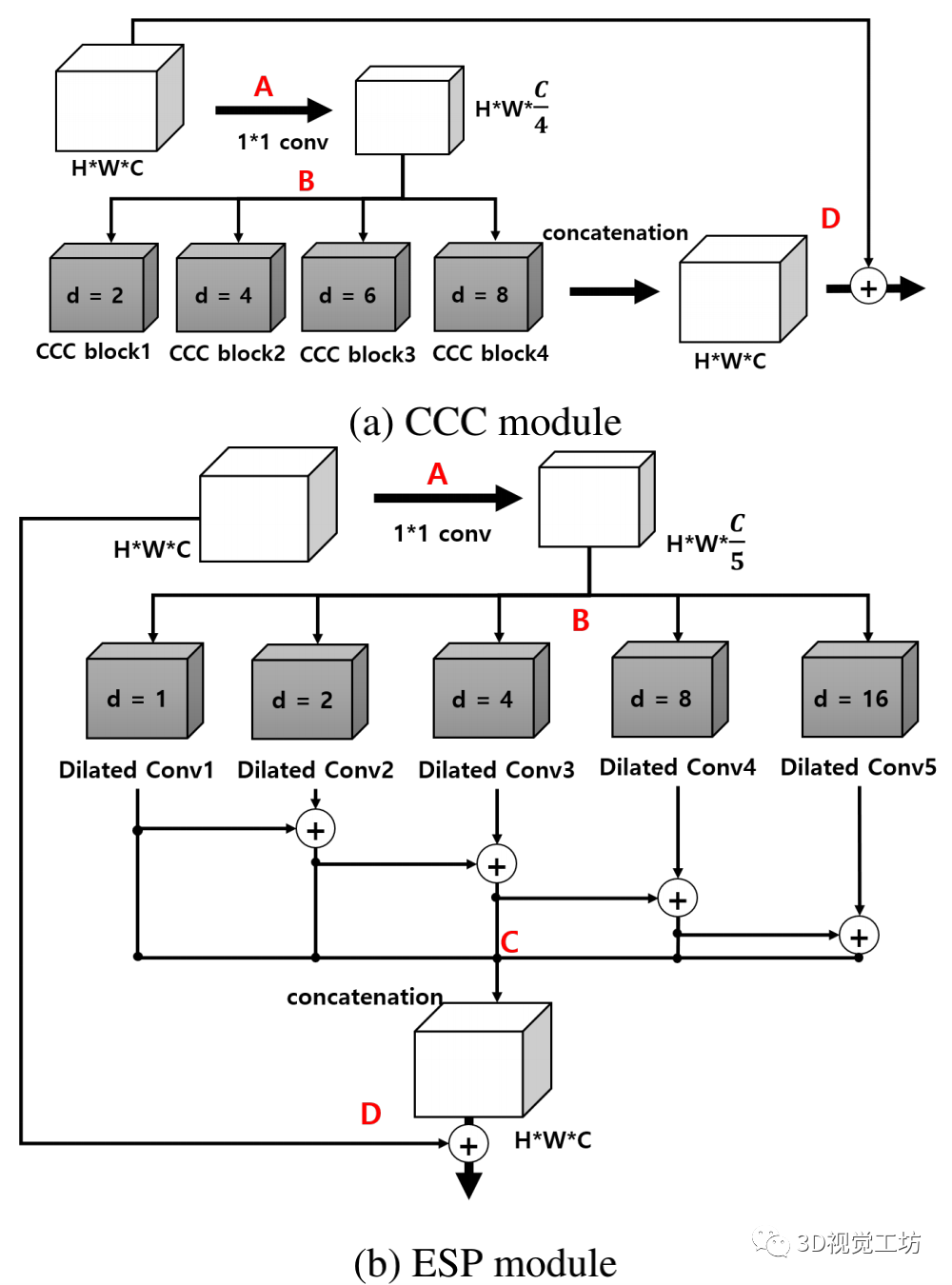
【13】用于实时语义分割的双向分割网络
《BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation》
链接:https://arxiv.org/pdf/1808.00897.pdf
本文的出发点是因为以往的工作中的1.感受野太小 2.空间信息的损失
关于空间信息
空间信息(Spatial information)主要指的是图像的局部细节信息,尤其是对于边缘丰富的图像。由于卷积网络规模大,一般要求输入图像尺寸较小,需要对原始图像进行Crop或者Resize,这个过程会损失细节的空间信息。通过设置只包含3个网络的Spacial Path,可保留丰富的空间信息,进而将低纬度的空间细节信息与高纬度的信息整合。
网络框架:
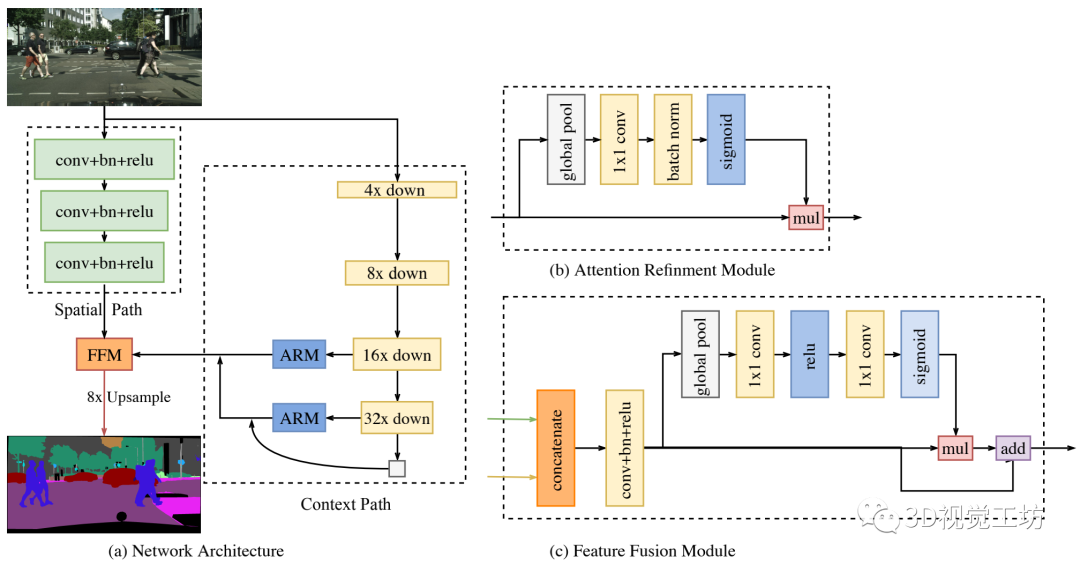
右边为特征融合模块(FFM):
Spatial Path 捕获的空间信息编码了绝大多数的丰富细节信息,Context Path 的输出特征主要编码语境信息。两路网络的特征并不相同,因此不能简单地加权两种特征,要用一个独特的特征融合模块以融合这些特征。
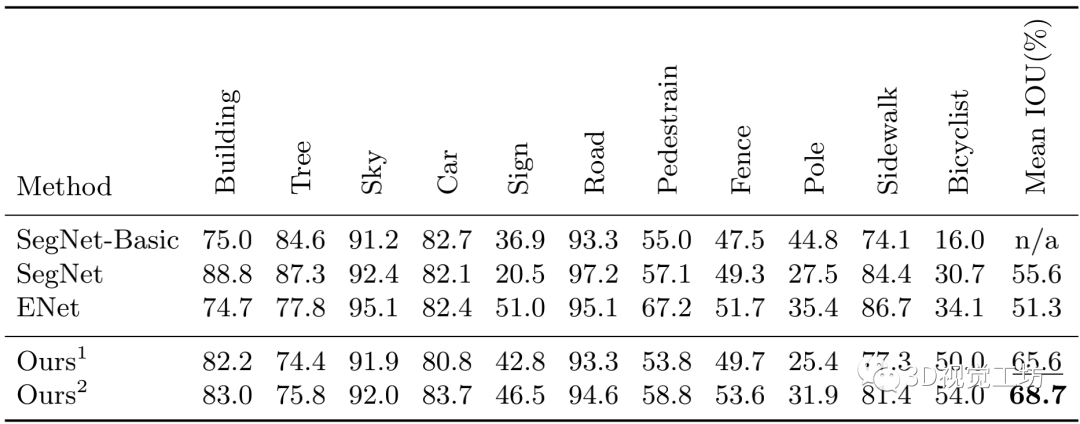
实验结果:
【14】用于实时语义分割的轻量级精细网
《Light-Weight RefineNet for Real-Time Semantic Segmentation》
链接:https://arxiv.org/pdf/1810.03272v1.pdf
论文提出了RefineNet 的轻量化版本Light-Weight RefineNet ,针对实时分割任务,将速度从20FPS提升到了55FPS(GPU,512*512输入,Mean IOU 81.1%,PASCAL VOC测试集)。
网络结构:

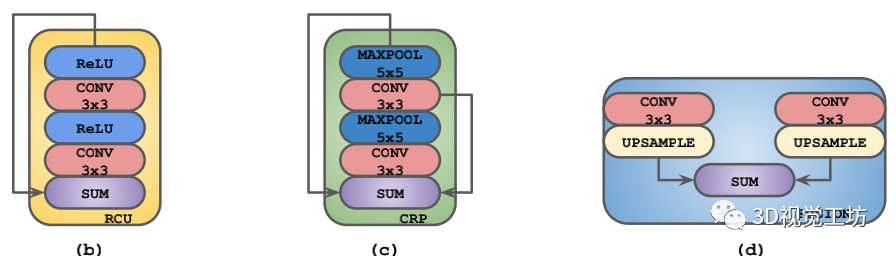
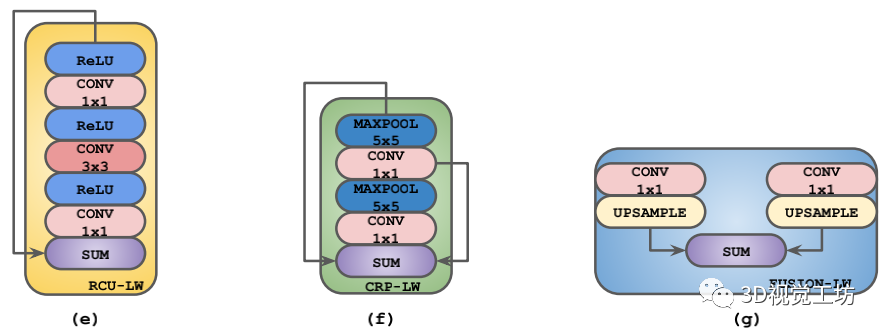
RefineNet 的总体网络结构,分为下采样的encoder部分和上采样的decoder部分。网络主要包含4个模块,RCU,CRP,FUSION,CLF。为了轻量化该网络,分别使用RCU-LW,CRP-LW。
FUSION-LW替换了原始网络的RCU,CRP,FUSION。通过后续的实验作者又发现RCU对于网络的精度提升效果微弱,因此将RCU模块也去掉了。
为什么去掉RCU模块,网络精度影响很小?
因为:
(1)虽然RCU模块中的3*3卷积使得网络具有更大的感受野,但是通过shortcut结构,底层特征和高层特征也可以共享。
(2)CRP模块也可以获得上下文的信息。
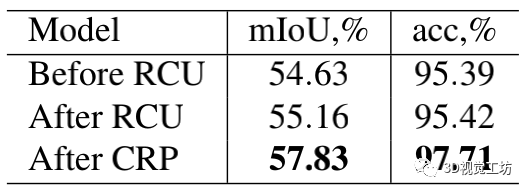
可以从下图看出,RCU模块对精度提升微弱,而CRP模块对精度提升明显。
模型参数比较:

基于ResNet101的基础结构的RefineNet,第一个为传统的RefineNet,第二个为带RCU的RefineNet,第三个为不带RCU的RefineNet。可见RefineNet-101-LW相比RefineNet-101将参数量和运算量都大大降低。
【15】ShelfNet用于实时语义分割
《ShelfNet for Real-time Semantic Segmentation》
链接:https://arxiv.org/pdf/1811.11254v1.pdf
该文章提出了一种全新的架构——ShelfNet,利用多个编码-解码结构对 来改善网络中的信息流动。
同一个残差块的两个卷积层贡献权重,在不影响精度的条件下,减少参数量;
在多个Benckmark上得到验证
模型结构:
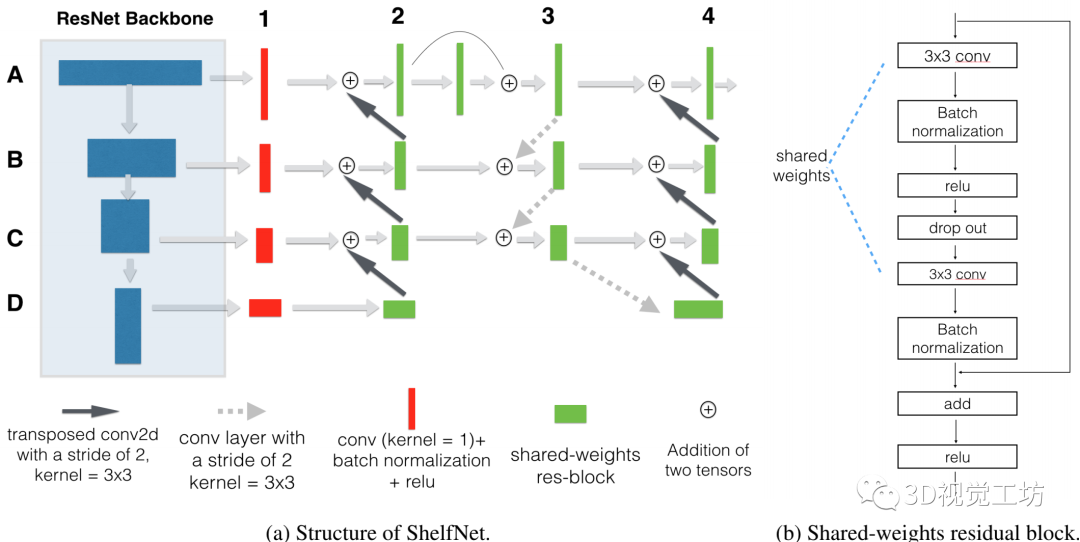
ShelfNet可以看作是FCNs的集合。一些信息流路径的例子用不同的颜色标记。每个路径相当于一个FCN(除了在ResNet主干中有池化层)。与FCN集合的等价性使ShelfNet能够用一个小的神经网络来执行精确的分割。

【16】LadderNet:用于医学图像分割的基于U-NET的多路径网络
《LadderNet: MULTI-PATH NETWORKS BASED ON U-NET FOR MEDICAL IMAGE SEGMENTATION》
链接:https://arxiv.org/pdf/1810.07810.pdf
模型结构:
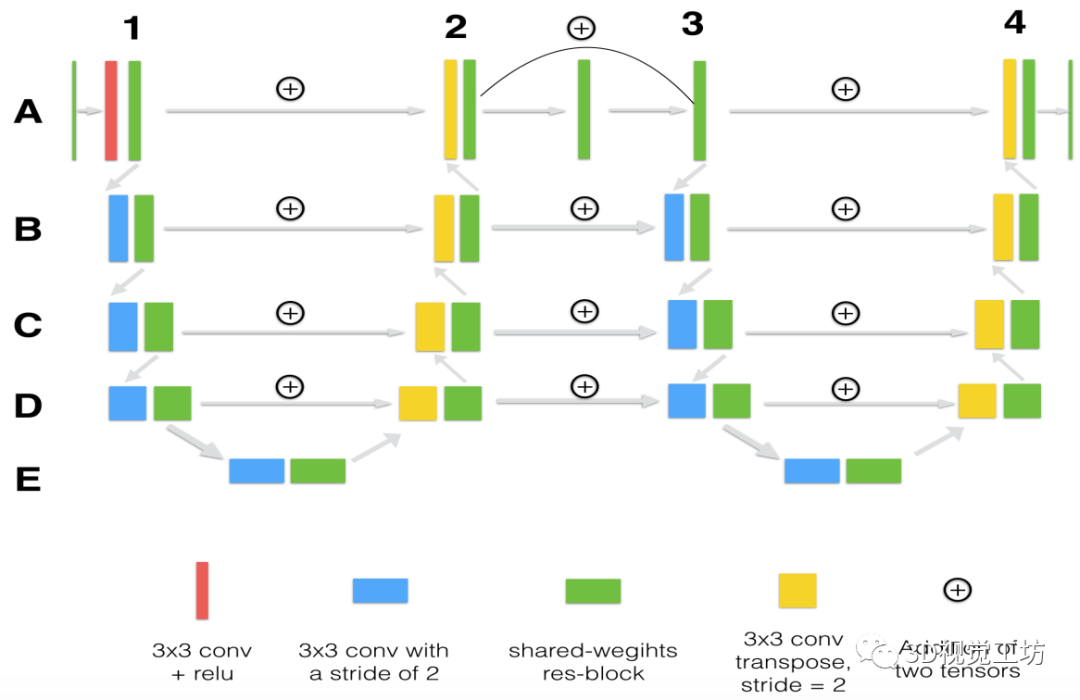
1、3是编码器分支,2、4是解码器分支,A-E是不同级的特征。整个模型没有使用池化层,用的是一个步长为2的卷积层代替,通道数在编码器部分逐级翻倍。
可以看出这是两个U-Net相连,有两个U形(12, 34),而这两个U形之间的A-D级采用跳接连接起来。U-Net网络是,跳接用的是融合,也就是通道数相加,但是这里用的直接求和的模式(要求通道数必须一样)。
但增加更多的encoder-decoder分支会导致参数增加,训练变得困难,所以作者又采用了Shared-weights residual block(参数共享残差块),如下图所示。
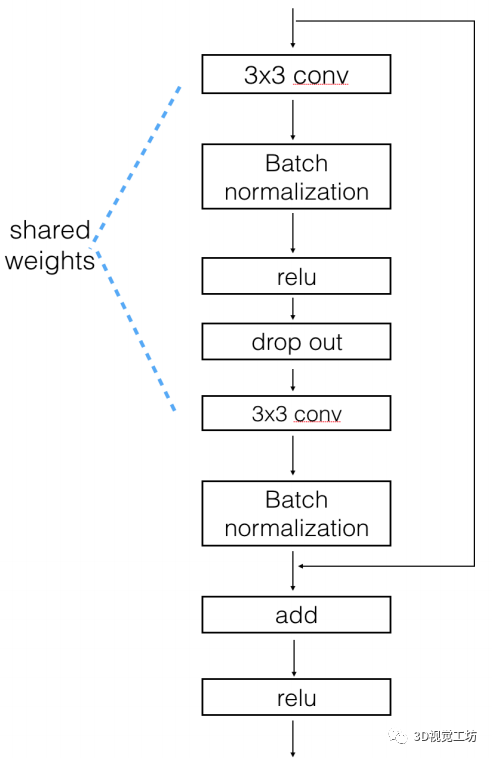
【17】ShuffleSeg实时语义分割网络
《SHUFFLESEG: REAL-TIME SEMANTIC SEGMENTATION NETWORK》
链接:https://arxiv.org/pdf/1803.03816.pdf
嗯。。。这篇文章没深刻说的,哈哈。
该架构将分成两个主要模块进行解释:负责提取特征的编码模块,负责在网络中进行上采样以计算最终类别的概率图的解码模块。
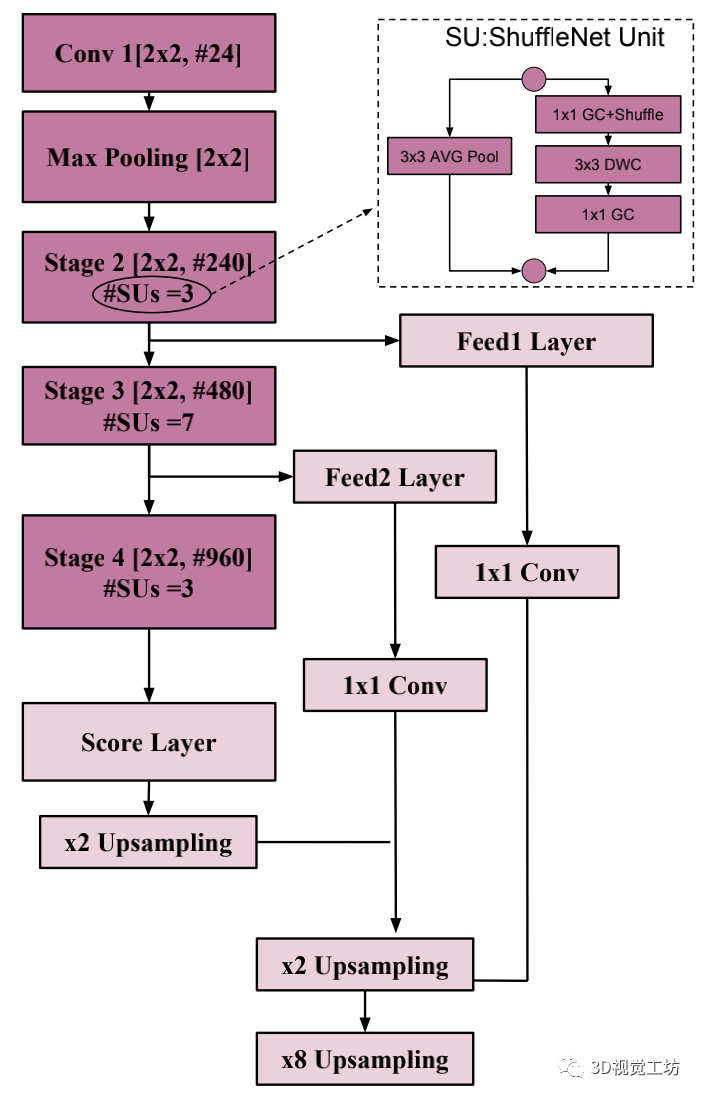
1)基于ShuffleNet (Shufflenet: An extremely efficient convolutional neural network for mobile devices) 提出的分割网络
2)编码器使用ShuffleNet 单元,解码器综合了 UNet、FCN8s 和 Dilation Frontend 的结构;速度快,没有什么创新。。。。
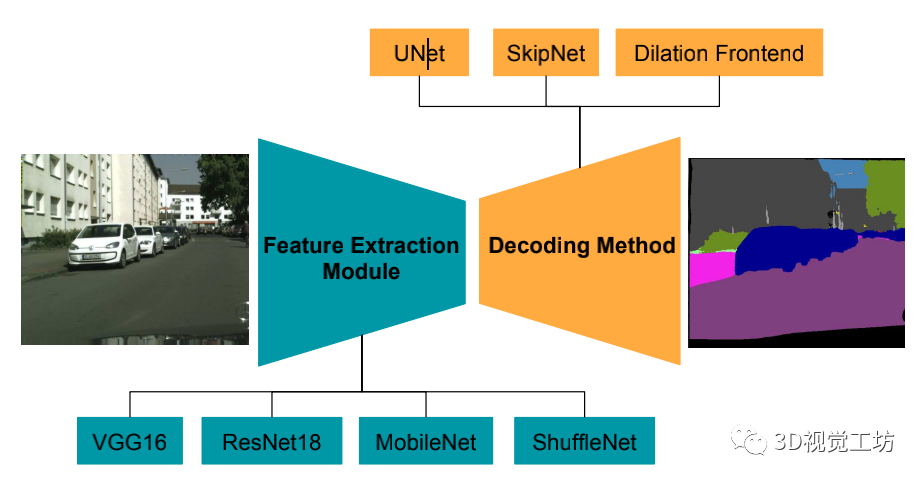
【18】RTSeg:实时语义分割比较研究
《RTSeg: REAL-TIME SEMANTIC SEGMENTATION COMPARATIVE STUDY》
链接:https://arxiv.org/pdf/1803.02758.pdf
提供特征提取和解码方法,称为元架构;
给出了计算精度和计算效率之间的权衡;
Shufflenet比segment减少了143x gflops;
模型结构:
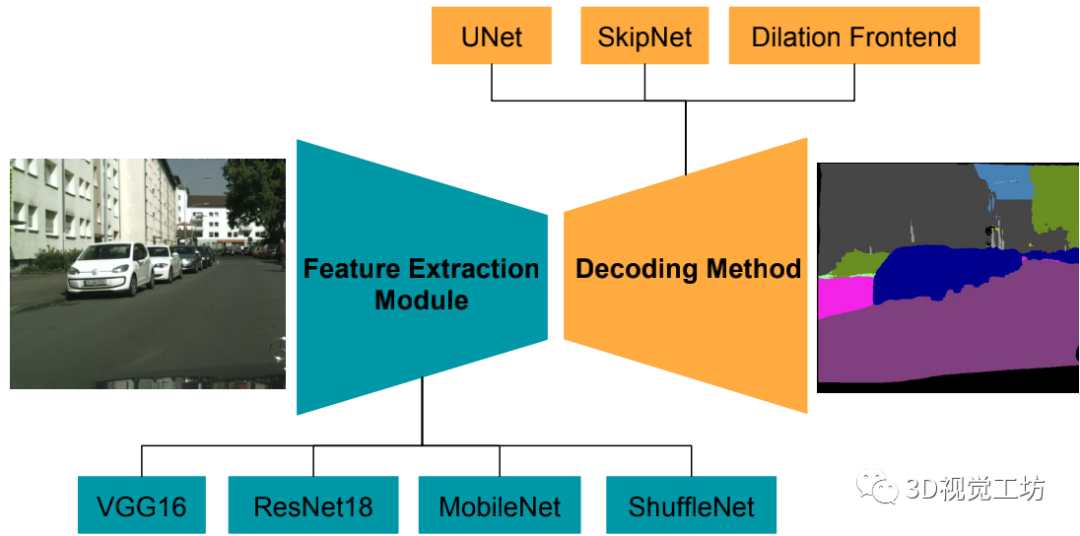
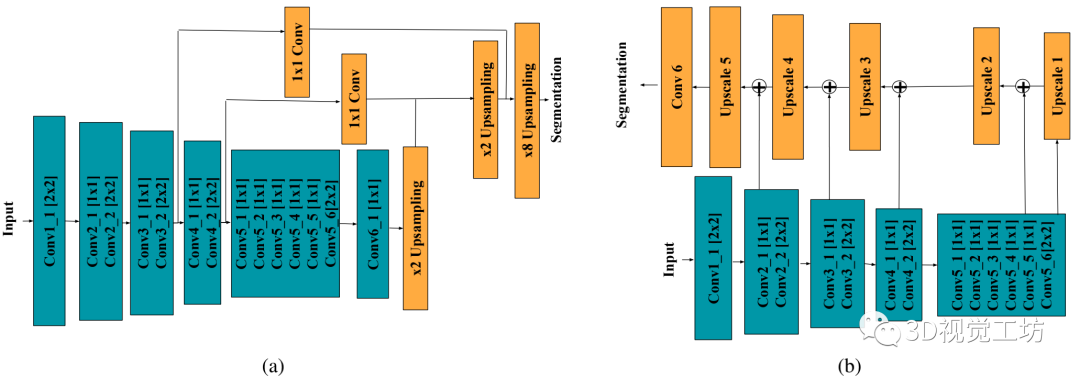
使用空洞卷积代替下采样的feature map,空洞卷积确保网络维持足够的感受野而不需要通过pooling和stride conv来破坏像素结构;
Meta-Architectures
1)SkipNet meta-architecture;
2)U-Net meta-architecture;
3)Dilation Frontend meta-architecture;
【19】ContextNet:实时为语义分割探索上下文和细节
《ContextNet: Exploring Context and Detail for Semantic Segmentation in Real-time》
链接:https://arxiv.org/pdf/1805.04554.pdf
模型结构:
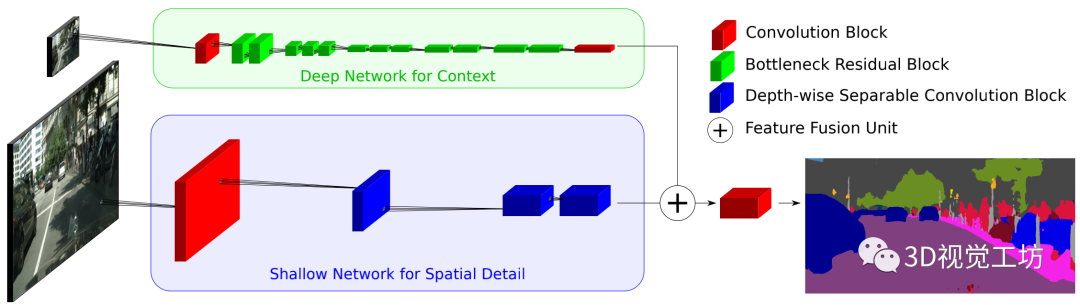
ContextNet利用更深层的网络,增加的层数有助于学习更复杂和抽象的特征,从而提高准确性,但也增加了运行时间。聚合来自多个分辨率的上下文信息是有益的,结合了多个级别的信息以提高性能。
Depth-wise Convolution to Improve Run-time:
深度可分离卷积将标准卷积(Conv2d)分解为深度上的卷积(DWConv),也称为空间或通道上的卷积,然后是1×1的点卷积层。因此,跨通道和空间相关性的计算是独立的,这大大减少了参数的数量,导致更少的浮点运算和快速的执行时间。
ContextNet利用了DWConv,输入下采样的子网使用了DWConv的瓶颈残差块。
Capturing Global and Local Context:
ContextNet有两个分支,一个是全分辨率(h×w),另一个是低分辨率(如h/4 w/4),输入图像高度h,宽度w。每个分支都有不同的职责;后者捕捉图像的全局上下文,前者为更高分辨率的分割提供细节信息。
为了快速提取特征,语义丰富的特征只从最低可能的分辨率提取;
局部上下文的特征通过一个非常浅的分支从全分辨率输入中分离出来,然后与低分辨率的结果相结合。
【20】CGNet:一个轻量级的上下文引导的语义分割网络
《CGNet: A Light-weight Context Guided Network for Semantic Segmentation》
链接:https://arxiv.org/pdf/1811.08201.pdf
该文分析了语义分割的内在特性,提出了学习局部特征和周围上下文的联合特征,并进一步改进全局上下文的联合特征的CG块。有效的利用 local feature, surrounding context and global context。其中的CG块,在各个阶段有效地捕获上下文信息。CGNet的主干是专门为提高分割精度而定制的,以减少参数的数量和节省内存占用。在相同数量的参数下,提出的CGNet显著优于现有的分割网络(如ENet和ESPNet)。
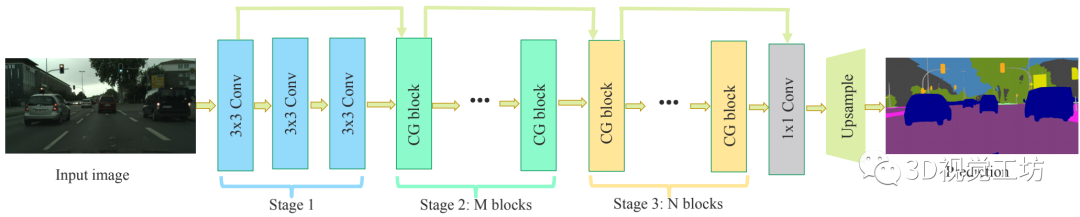
模型结构:
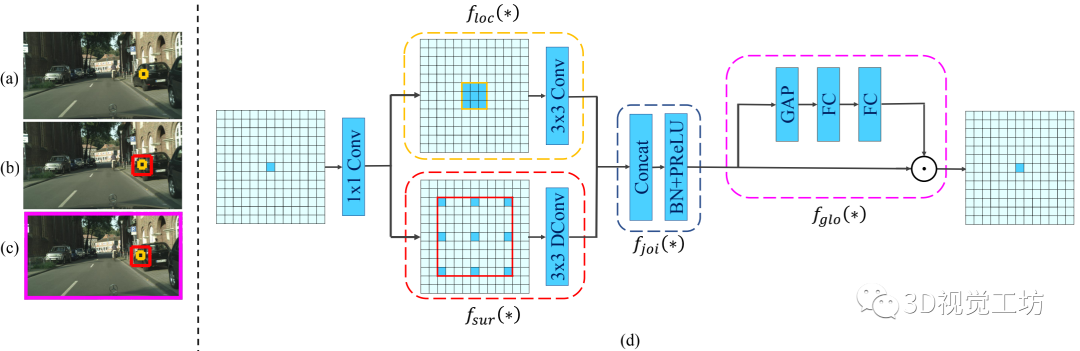
在CG block引入残差学习,两种方式:local residual learning (LRL) 和global residual learning (GRL),如下图所示:

由CG block定义CGNet:较少的卷积层和较少的通道数,从而减少参数量。
个人观点:
1)CGNet进一步拓展了non-local的概念,从local,surrounding和global三个层次获取空间特征间的关联。
2)在CGNet的stage2和stage3都使用GC block,区别于non-local中只有resnet部分stage和部分blcok之间引入non-local机制。
【21】用于自动驾驶的实时语义分割解码器的设计
《Design of Real-time Semantic Segmentation Decoder for Automated Driving》
链接:https://arxiv.org/pdf/1901.06580.pdf
本文是采用编码解码结构,编码器是独立的10层VGG。
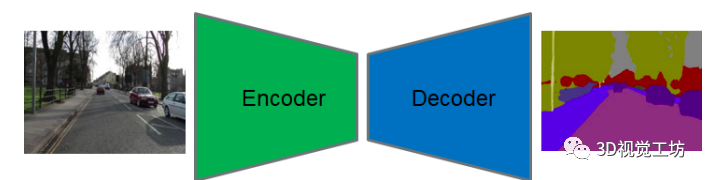
使用stride 2卷积后的max-pooling来减少空间问题,这样就减少了超参数的数量和运行时。显然,这是为了分割精度的权衡,但对于检测、分类等其他任务则不是这样。考虑到该编码器是功能独立的,需要在解码器方面通过广泛学习语义特征来克服空间信息探索的差距。
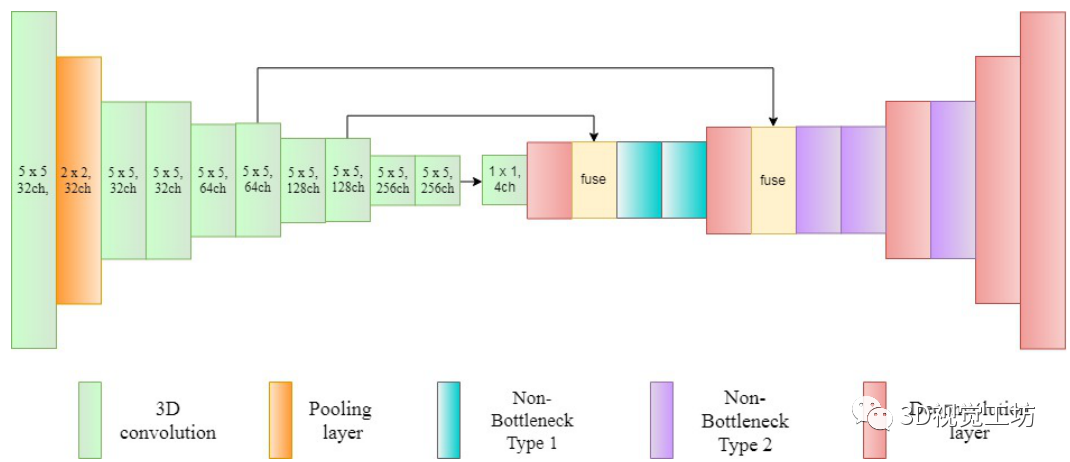
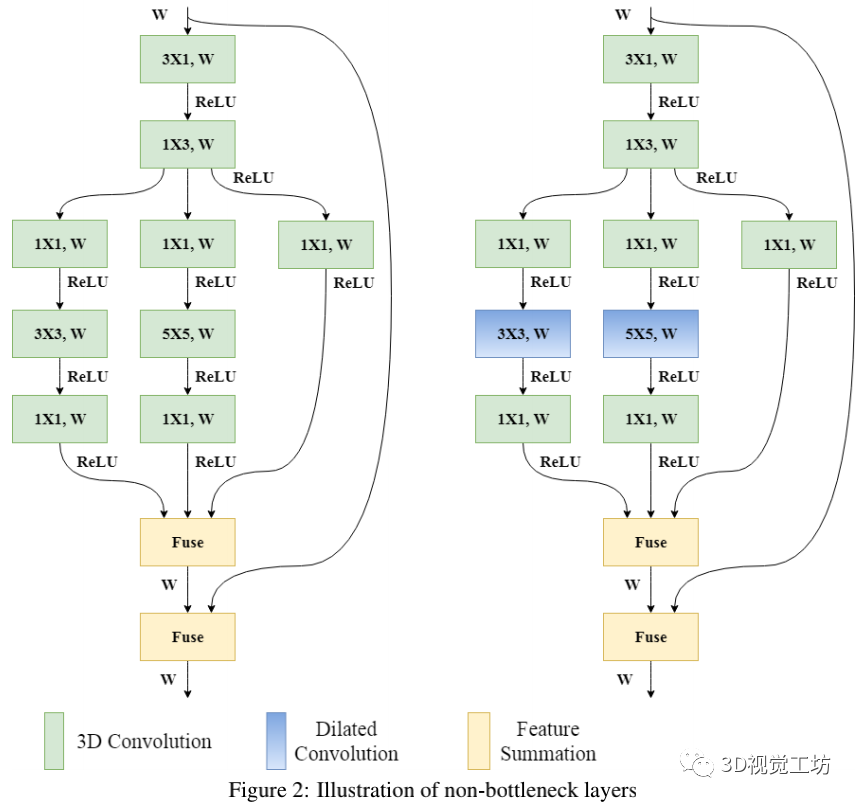
非瓶颈层的设计如下图所示。它同时包含1D和3D卷积核。一维核主要一次从一个方向提取信息,三维核主要从较大的接受区域收集特征。之后通过不同大小的多个kernel来寻找密集的信息,例如3×3, 5×5和1×1。接下来,融合使用不同内核提取的特征。该方法有助于总结从不同接受区域收集到的语义特征。合成的特征再一次与输入特征融合到同一个非瓶颈层。在所提出的非瓶颈层中,多个跳转连接到特征融合块,这有助于处理高梯度流,因为在反向传播时,传入的梯度分布在所有路径中。
我们知道解码器做得更宽,运行时间会大幅提高。因此,定期减少特征图的数量是负担不起的,也超出了模型的预算。
【22】DSNet:用于实时驾驶场景的语义分割
《DSNet: DSNet for Real-Time Driving Scene Semantic Segmentation》
链接:https://arxiv.org/pdf/1812.07049v1.pdf
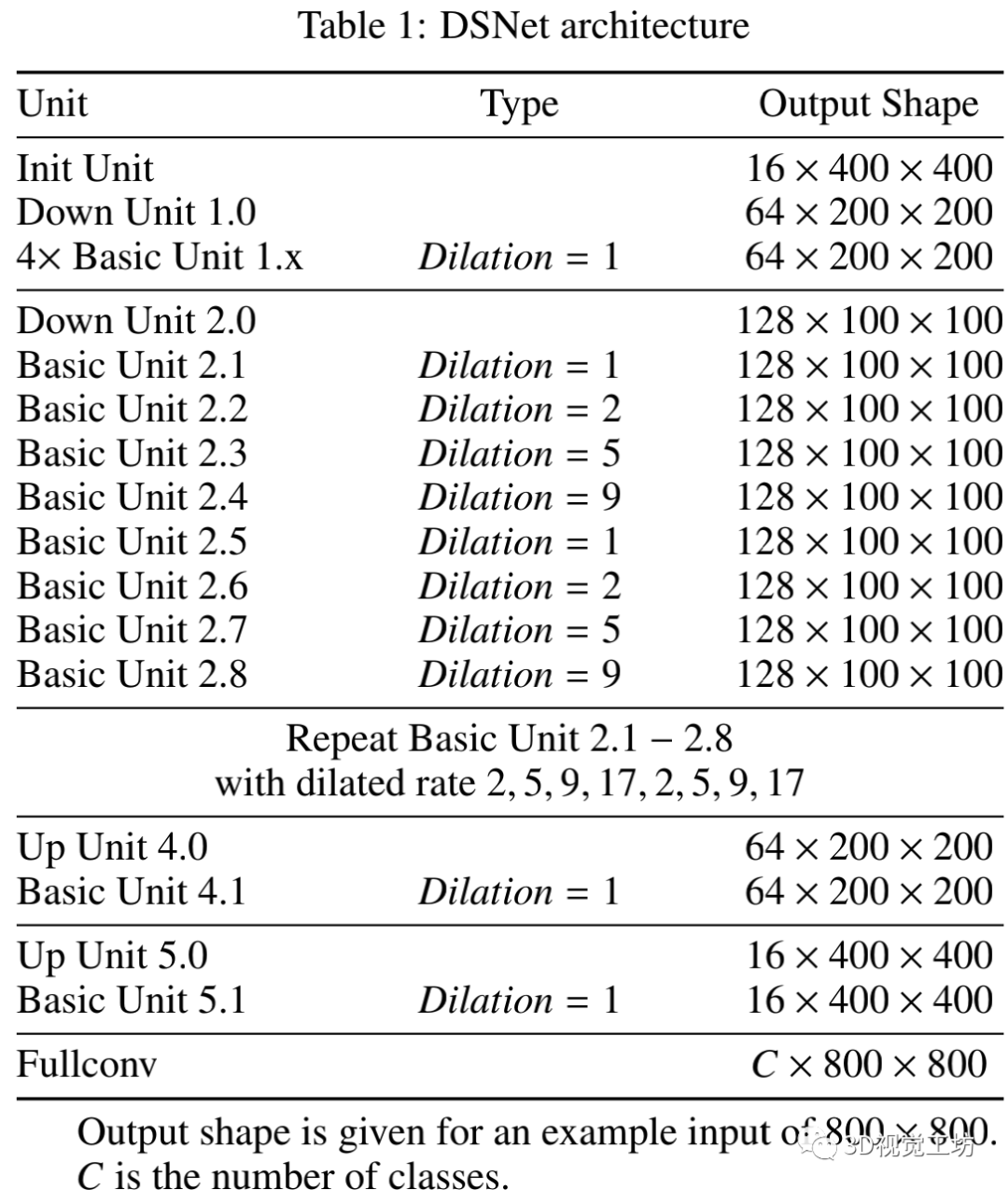
DSNet是一种高效且强大的单元和非对称的编解码器架构。采用混合扩张卷积方案来克服网格化问题。
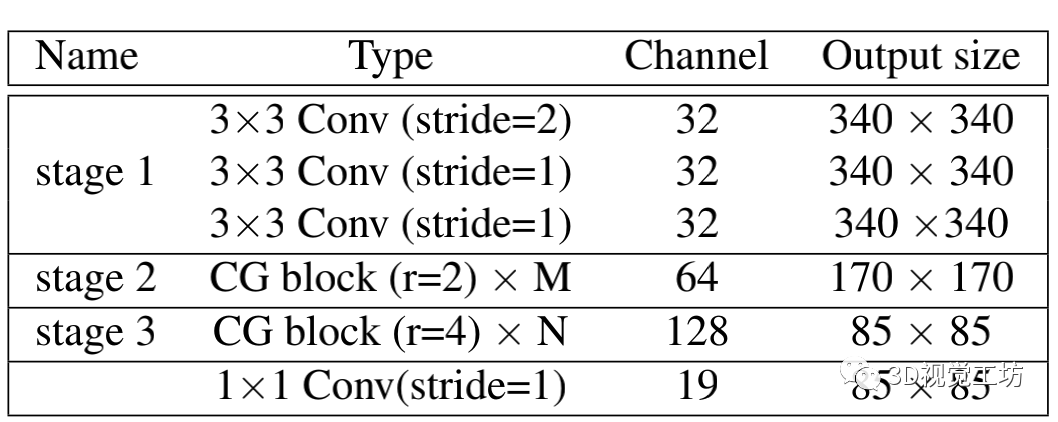
DSNet详细结构如下表:
参考ShuffleNet V2总结了轻量框架指导准则如下:
准则1:等信道宽度最小化内存访问成本(MAC)
准则2:过多的组卷积增加MAC
准则3:网络碎片化降低并行度
准则4:Element-wise操作不可忽略
DSNet单元模块:
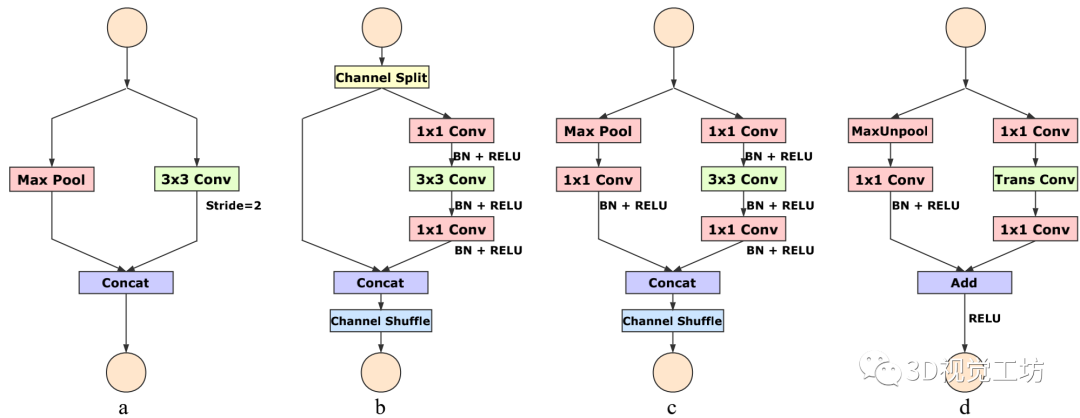
采用ENet的初始单元,使用最大池和步长2的卷积对输入进行下采样。深度可分卷积替换为扩张型卷积,以扩大接收域,这对语义分割至关重要。
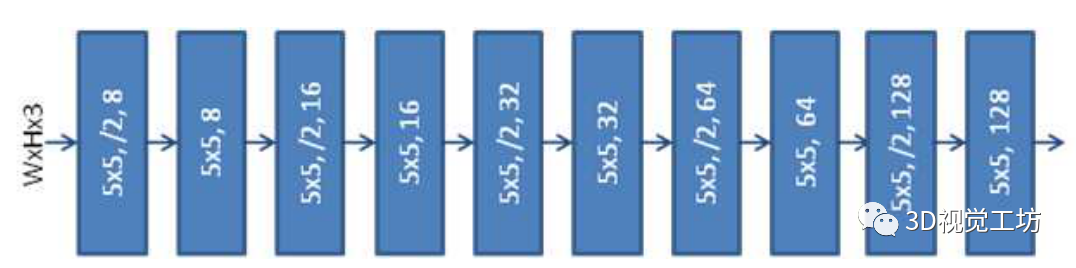
【23】Fast-SCNN:快速语义分割网络
《Fast-SCNN: Fast Semantic Segmentation Network》
链接:https://arxiv.org/pdf/1902.04502.pdf
我们知道在语义分割中较大的接受野对于学习目标类之间的复杂关联(即全局上下文)很重要,图像中的空间细节对于保持目标边界是必要的,需要特定的设计来平衡速度和准确性(而不是重新定位分类DCNNs)。
模型框架:
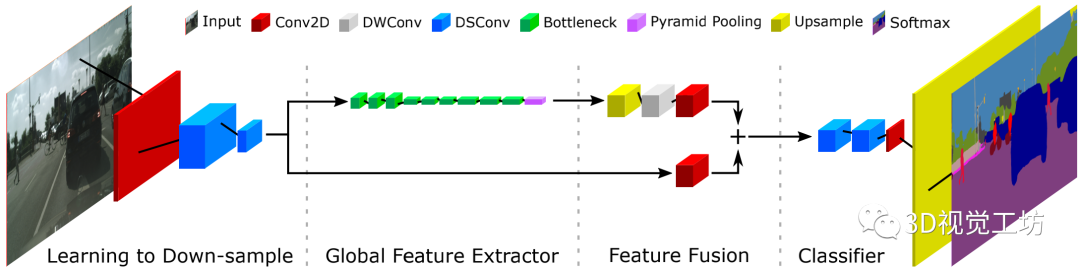
two-branch 网络,它在低分辨率位置使用一个较深的 branch 来捕捉环境信息,在高分辨率位置使用一个较浅的 branch 来学习细节信息。然后,将这二者融合起来,形成最终的语义分割结果。
本文的主要贡献:
1)提出了一个实时语义分割算法 Fast-SCNN,在高清图像上准确率为68%,速度为123.5帧每秒;
2)调整了 skip connection,提出了一个浅层的 learning to downsample 模块,可以快速而高效地通过 multi-branch 来提取低层次特征;
3)设计了low capacity Fast-SCNN,对于small capacity网络而言,多训练几个 epoch的效果和在ImageNet上进行预训练是一样的。
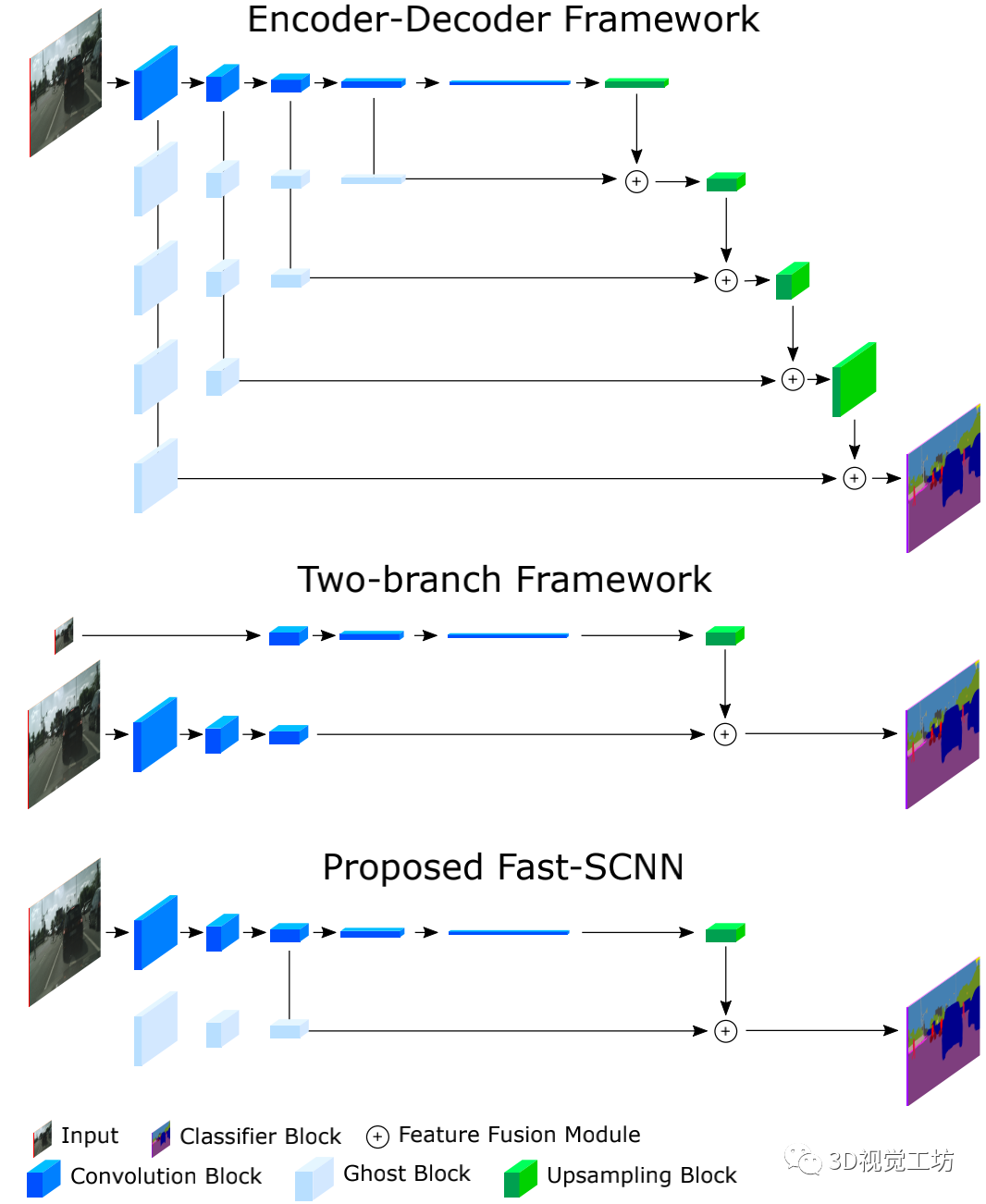
之前的PSPNet 中的金字塔池化模块和DeepLab中的 atrous 空间金字塔池化(ASPP)用于 encode 和利用全局信息。与目标检测类似,速度是语义分割系统设计中的一个重要因素。基于FCN,SegNet 引入了一个联合 encoder-decoder 模型,是最早的高效率分割模型之一。延续SegNet,ENet 也设计了 encoder-decoder ,层数较少,降低计算成本。然后,two-branch 和 multi-branch 系统出现了。ICNet, ContextNet, BiSeNet, GUN 通过一个较深的 branch 在低分辨率输入上学习全局信息,通过一个较浅的 branch 在高分辨率图像上学习细节信息。但是,SOTA 的语义分割仍具挑战,通常需要高性能GPU。受 two-branch 启发,Fast-SCNN 加入了一个共享的浅层网络来编码细节信息,在低分辨率输入上高效地学习全局信息。
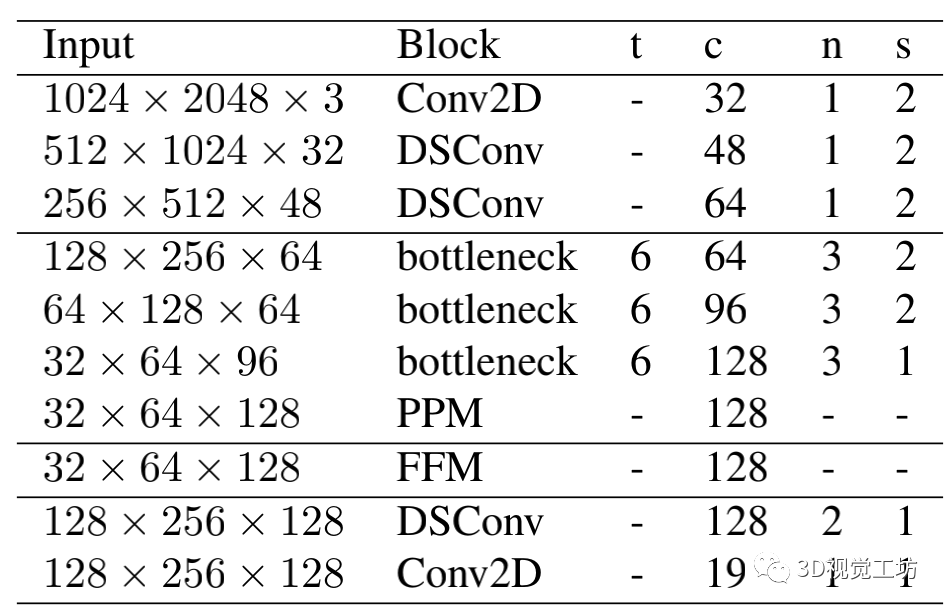
详细网络如下表:
【24】ShuffleNet V2:语义分割的一个有效解决方案:具有可分卷积
《An efficient solution for semantic segmentation: ShuffleNet V2 with atrous separ:able convolutions》
链接:https://arxiv.org/pdf/1902.07476v1.pdf
本文设计的4个出发点:
当通道宽度不相等时,内存访问成本(MAC)就会增加,因此通道宽度应该保持相等。
在提升MAC时,应该避免过度使用组卷积。
为了保持较高的并行度,应该避免网络碎片化。
诸如ReLU、Add、AddBias等元素明智操作是不可忽略的,应该减少。
本文贡献:
在语义分割任务上使用ShuffleNetV2、DPC编码器以及一个全新的解码模块实现了SOT的计算效率,在Cityscapes测试数据集上达到了70.33%的mIoU;
所提出的模型和实现完全兼容TensorFlow Lite,能够在Android和iOS移动手机平台实时运行;
TensorFlow的网络实现以及训练模型都是开源的。
模型结构:
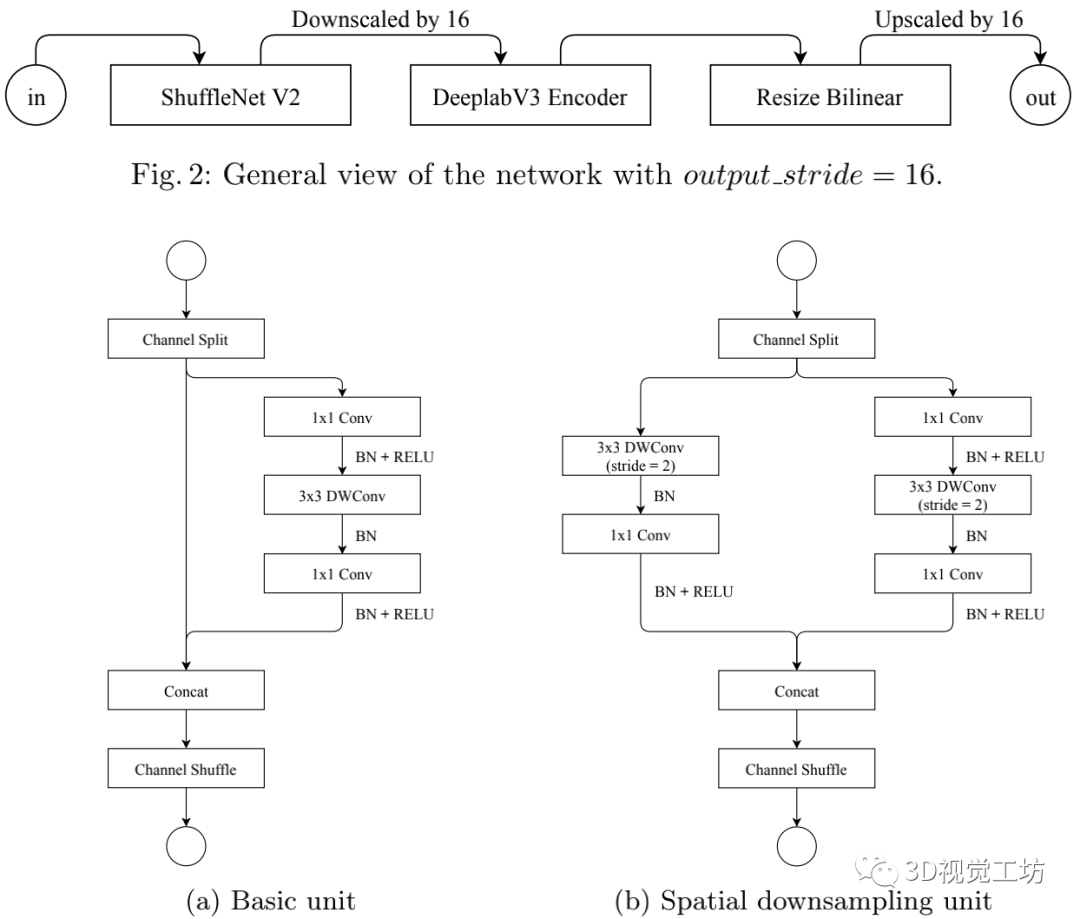
如上图所示,使用了ShufflenetV2框架来提取特征,然后接入DeepLabV3编码器,最后使用双线性缩放作为新的解码器来生成分割掩模。网络的设计与修改都是在ImageNet数据集上验证后作出的选择。
特征提取之后使用DPC编码器。文章提供了两种不同架构的DPC,一个是DPC基础模块,另一个是基于MobileNetV2的DPC模块,细节如下图所示:
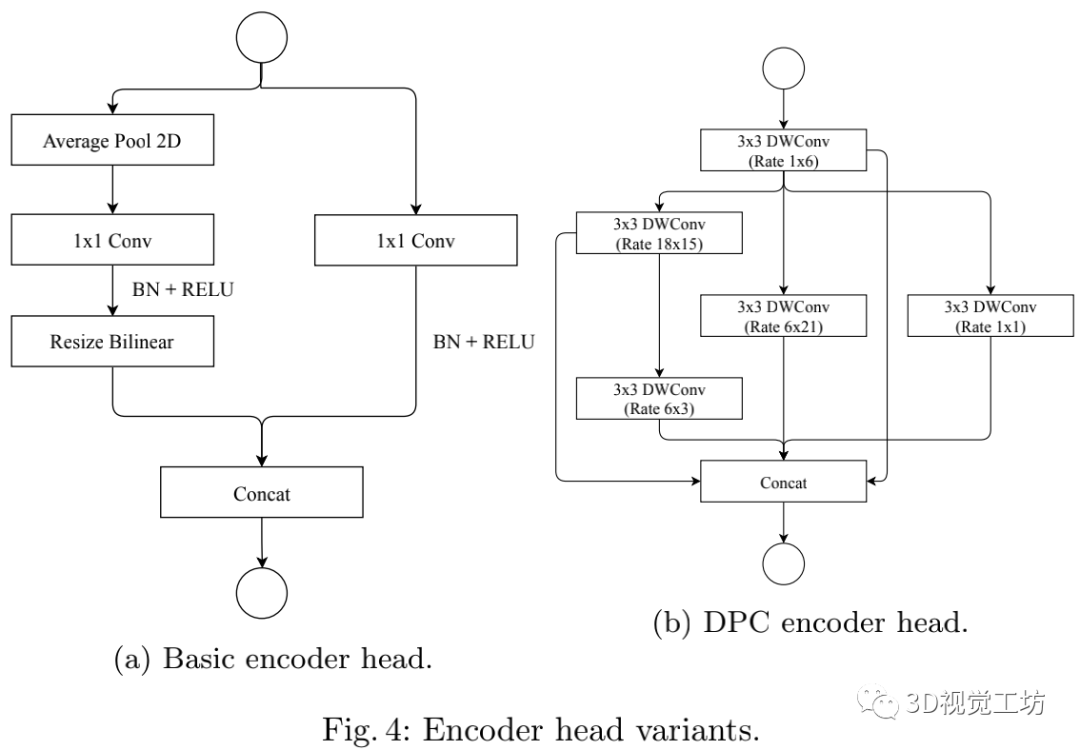
编码器输出之后会经过1×1卷积层降维,然后紧接着Dropout层、双线性缩放和最后的分类ArgMax。其中解码部分采用的简单的双线性缩放操作将特征图缩放到原图尺寸。
模型详细结构如下表所示:

推荐阅读
