
浅谈深度学习混合精度训练

极市导读
在学习实践混合精度训练的过程中,作者写下了这篇笔记。从基础理论到项目应用,这篇文章都有很详细的心得。>>加入极市CV技术交流群,走在计算机视觉的最前沿
本文主要记录下在学习和实际试用混合精度过程中的一些心得总结和建议。
01. 前言
以前一直看到不少混合精度加速模型训练的工作,受限于手上没有 Volta 架构的GPU。体验工作也就只能作罢。但是最近成功申请下来V100机器,除了激动之外,当时心里最大的想法,就是要尝试下这心心念念已久的混合精度加速功能。
02. 基础理论
在日常中深度学习的系统,一般使用的是单精度 float(Single-Precision)浮点表示。在了解混合精度训练之前,我们需要先对其中的主角半精度『float16』进行一定的理论知识学习。

float vs float16 的组成bitmap
在上图可以看到,与单精度float(32bit,4个字节)相比,半进度float16仅有16bit,2个字节组成。天然的存储空间是float的一半。其中,float16的组成分为了三个部分:
最高位表示符号位; 有5位表示exponent位; 有10位表示fraction位;
根据wikipedia上的介绍,我总结下float16的这几个位置的使用,以及如何从其bitmap计算出表示的数字:
如果 Exponent 位全部为0:
如果 fraction 位 全部为0,则表示数字 0 如果 fraction 位 不为0,则表示一个非常小的数字(subnormal numbers),其计算方式: 如果 Exponent 位全部位1:
如果 fraction 位 全部为0,则表示 ±inf 如果 fraction 位 不为0,则表示 NAN Exponent 位的其他情况:
计算方式:
结合上面的讲解,那么就可以顺利的理解下面的这些半精度例子:

wikipedia: float16 半精度例子
在上面的例子中,我们可以对 float16 有一个感性的认识,对这个范围有一个大概的印象,后面会用到:
float16 最大范围是 [-65504 - 66504] float16 能表示的精度范围是 ,超过这个数值的数字会被直接置0;
03. 混合精度训练
在这里的混合精度训练,指代的是单精度 float和半精度 float16 混合。比较经典的就是这篇ICLR2018,百度和Nvidia联合推出的论文 MIXED PRECISION TRAINING。因此,这里也以这篇论文作为引子,对混合精度进行讲解。
3.1 为什么需要半精度:
float16和float相比恰里,总结下来就是两个原因:内存占用更少,计算更快。
内存占用更少:这个是显然可见的,通用的模型 fp16 占用的内存只需原来的一半。memory-bandwidth 减半所带来的好处:
模型占用的内存更小,训练的时候可以用更大的batchsize。 模型训练时,通信量(特别是多卡,或者多机多卡)大幅减少,大幅减少等待时间,加快数据的流通。 计算更快:
目前的不少GPU都有针对 fp16 的计算进行优化。论文指出:在近期的GPU中,半精度的计算吞吐量可以是单精度的 2-8 倍;
3.2 Float16的问题:
PS: 下面针对 fp16 的问题描述,由于别人阐述的更加简单到位,所以部分引用自《唯快不破:基于Apex的混合精度加速》。
那既然fp16像上面说的那么好,那么是否全部都使用 fp16 即可了呢?当然不是,如果fp16那么好,那又何来 『混合精度』这么一说呢。
3.2.1 数据溢出问题:Overflow / Underflow
在第一节中,我们提到了 fp16 的有效的动态范围约为 ( ),比单精度的float要狭窄很多。对于深度学习而言,最大的问题在于 Underflow(下溢出),在训练后期,例如激活函数的梯度会非常小, 甚至在梯度乘以学习率后,值会更加小。
3.2.2 舍入误差(Rounding Error)
何为舍入误差,引用[2]中的一张图说的比较透彻:

半精度FP16舍入误差的例子,来自引用[2]
这个例子非常直观的阐述了『舍入误差』这个说法。而至于上面提到的,FP16的最小间隔是一个比较玄乎的事,在wikipedia的引用上有这么一张图:描述了 fp16 各个区间的最小gap。

半精度FP16不同区间的最小间隔
3.3 解决办法:
3.3.1 FP32 权重备份
这种方法主要是用于解决舍入误差的问题。其主要思路,可以概括为:weights, activations, gradients 等数据在训练中都利用FP16来存储,同时拷贝一份FP32的weights,用于更新。在这里,我直接贴一张论文[1]的图片来阐述:
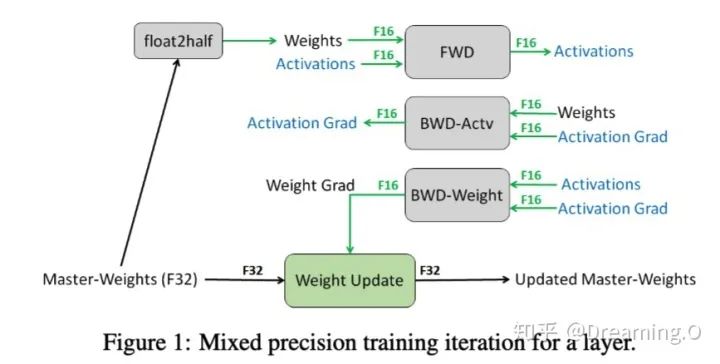
权重fp32备份策略
可以看到,其他所有值(weights,activations, gradients)均使用 fp16 来存储,而唯独权重weights需要用 fp32 的格式额外备份一次。这主要是因为,在更新权重的时候,往往公式: 权重 = 旧权重 + lr * 梯度,而在深度模型中,lr * 梯度 这个值往往是非常小的,如果利用 fp16 来进行相加的话, 则很可能会出现上面所说的『舍入误差』的这个问题,导致更新无效。因此上图中,通过将weights拷贝成 fp32 格式,并且确保整个更新(update)过程是在 fp32 格式下进行的。
看到这里,可能有人提出这种 fp32 拷贝weight的方式,那岂不是使得内存占用反而更高了呢?是的, fp32 额外拷贝一份 weight 的确新增加了训练时候存储的占用。但是实际上,在训练过程中,内存中占据大部分的基本都是 activations 的值。特别是在batchsize 很大的情况下, activations 更是特别占据空间。保存 activiations 主要是为了在 back-propogation 的时候进行计算。因此,只要 activation 的值基本都是使用 fp16 来进行存储的话,则最终模型与 fp32 相比起来, 内存占用也基本能够减半。
3.3.2 Loss Scale
Loss Scale 主要是为了解决 fp16 underflow 的问题。刚才提到,训练到了后期,梯度(特别是激活函数平滑段的梯度)会特别小,fp16 表示容易产生 underflow 现象。下图展示了 SSD 模型在训练过程中,激活函数梯度的分布情况:可以看到,有67%的梯度小于 ,如果用 fp16 来表示,则这些梯度都会变成0。
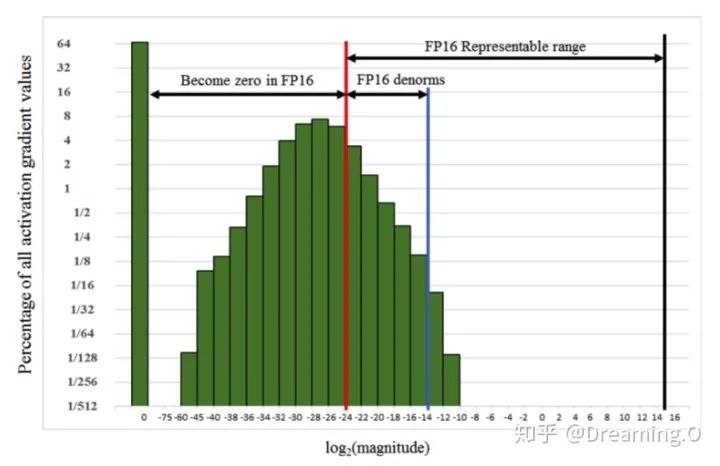
为了解决梯度过小的问题,论文中对计算出来的loss值进行scale,由于链式法则的存在,loss上的scale会作用也会作用在梯度上。这样比起对每个梯度进行scale更加划算。scaled 过后的梯度,就会平移到 fp16 有效的展示范围内。
这样,scaled-gradient 就可以一直使用 fp16 进行存储了。只有在进行更新的时候,才会将 scaled-gradient 转化为 fp32,同时将scale抹去。论文指出, scale 并非对于所有网络而言都是必须的。而scale的取值为也会特别大,论文给出在 8 - 32k 之间皆可。
3.3.3 提高算数精度
在论文中还提到一个『计算精度』的问题:在某些模型中,fp16矩阵乘法的过程中,需要利用 fp32 来进行矩阵乘法中间的累加(accumulated),然后再将 fp32 的值转化为 fp16 进行存储。换句不太严谨的话来说,也就是利用 利用fp16进行乘法和存储,利用fp32来进行加法计算。这么做的原因主要是为了减少加法过程中的舍入误差,保证精度不损失。
在这里也就引出了,为什么网上大家都说,只有 Nvidia Volta 结构的 拥有 TensorCore 的CPU(例如V100),才能利用 fp16 混合精度来进行加速。那是因为 TensorCore 能够保证 fp16 的矩阵相乘,利用 fp16 or fp32 来进行累加。在累加阶段能够使用 FP32 大幅减少混合精度训练的精度损失。而其他的GPU 只能支持 fp16 的 multiply-add operation。这里直接贴出原文句子:
Whereas previous GPUs supported only FP16 multiply-add operation, NVIDIA Volta GPUs introduce Tensor Cores that multiply FP16 input matrices andaccumulate products into either FP16 or FP32 outputs
04. 实际使用体验
4.1 需要什么GPU:
在上面讲述了为什么利用混合精度加速,需要用到 Volta 结构的GPU。在这里,我直接贴出 Nvidia 家各主流GPU的一些参数。以及拥有 TensorCore 的GPU列表:就目前而言,基本就只有V100 和 TITAN V 系列是支持 TensorCore 计算的。
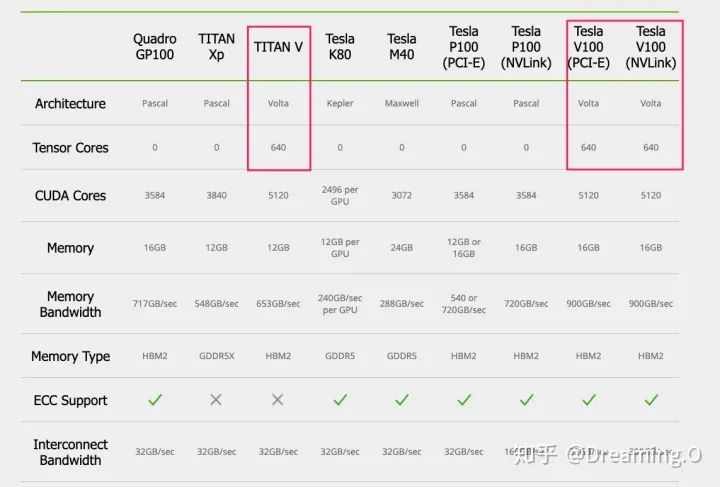
Nvidia各家显卡的参数简述,来自引用[3]
4.2 项目应用:
TensorFlow 在1.14版本后也支持了自动混合精度加速(Automatic Mixed Precision),具体参考链接, 具体使用起来,其实也就是指定一个环境变量(更具体的调节可以参考官方链接)
export TF_ENABLE_AUTO_MIXED_PRECISION=1
目前我正在利用 tensor2tensor 做机器翻译的相关工作,而tensor2tensor最近也支持了这个新的特性。通过在训练的时候指定 --gpu_automatic_mixed_precision=True 开启自动混合加速。除此之外,我还参考了论文:Scaling Neural Machine Translation 中的一些加速技巧。其中包括:
mixed-precision-train: fp16混合精度加速; 扩大batchsize:因为fp16混合精度加速,导致显存占用减少,因此可以启用更大的batchsize; cumulating gradients over multiple backwards (cumul):累积 cumul次的 back-propogation 操作后再更新一次模型,这样做的好处是减少多卡训练时,bp一次就update一次时的多卡等待时间。下面展示下具体的加速效果和一些备注:
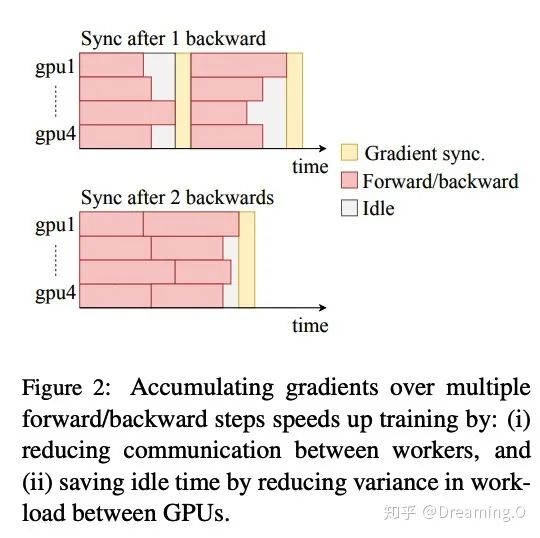
下面是我在利用 tensor2tensor 框架应用上述加速技巧的实验数据:
实验模型:Transformer-big 实验显卡:Tesla V100-SXM2-16GB

Tensor2tensor框架下,各项加速小技巧的加速比值
下面是实验(英语翻译到印地语机器翻译实验)对比,开启混合精度加速后,在校验集上的一些数据指标(loss,accuracy, approx_bleu_score)等均不受影响:
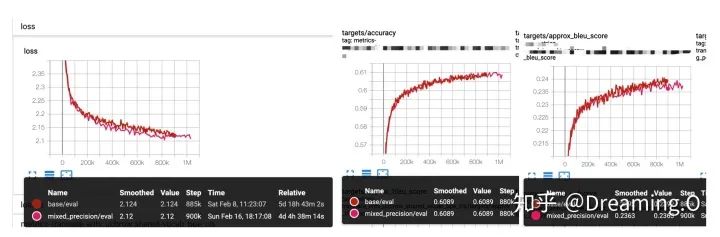
下面是对上述实验报告的一些备注:
开启XLA加速后,模型训练速度变慢了许多。原因不明。
根据 Nvidia 官方的建议,模型中权重的纬度是8的倍数时,效果最佳。我在实验中也证明了,如果Transofmer模型输入的词表大小不是8的倍数,则混合精度训练的加速比只有 1.22x
开启混合精度加速后,模型吞吐量约有 1.4x 倍的提升;
开启混合精度加速后,单卡的最大 batchsize 可以从 3584 提升到 4562;
开启混合精度加速后,Training 对 CPU 的利用率会变得很敏感。如果训练时候 CPU 大量被占用(利用利用空闲CPU进行decode)的话,会导致严重的减速。具体表现在:
CPU被大量占用后,GPU-kernel的利用率下降明显。估计是因为混合精度加速有大量的cast操作需要CPU参与,如果CPU拖了后腿,则会导致GPU的利用率也下降。 CPU被 decode 占用后,导致 steps/sec 从2.5+ 下降到 1.35+ T2T开启混合精度加速后,和论文 Scaling Neural Machine Translation 中的 fairseq 框架相比(t2t 官方中也有不少人指出这个问题),加速比不尽如人意。论文中指出,同样的模型 fairseq 开启混合精度加速后,加速比能到达 2.9x。
T2T中加速比不尽如人意,可能也有 Tensorflow 的锅。有一些工作指出,tensorflow 中的自动混合加速为了保证通用性,加速方式上做的比较保守,因此加速效果上不佳。有团队基于 Tensorflow 中的 LossScaleOptimizer 进行优化,实现更优的混合精度加速比。
参考资料
[1]MIXED PRECISION TRAINING
推荐阅读
ACCV 2020国际细粒度网络图像识别竞赛正式开赛!
