
手把手教你实现Android编译期注解
共 4109字,需浏览 9分钟
·
2021-10-15 16:31
作者:vivo互联网客户端团队-Wu Yue
一、编译期注解在开发中的重要性
从早期令人惊艳的ButterKnife,到后来的以ARouter为首的各种路由框架,再到现在谷歌大力推行的Jetpack组件,越来越多的第三方框架都在使用编译期注解这门技术,可以说不管你是想要深入研究这些第三方框架的原理 还是要成为一个Android高级开发工程师,编译期注解都是你不得不好好掌握的一门基础技术。
本文从基础的运行期注解用法开始,逐步演进到编译期注解的用法,让你真正明白编译期注解到底应该在什么场景下使用,怎么用,用了有哪些好处。
二、手写运行期注解
类似下面这种写法,当View一多得不停的findViewById 写很多行,手写起来很麻烦,我们首先尝试用运行期注解来解决这个问题,看看能不能自动处理这些findViewById的操作。

首先是工程结构,肯定要定义一个lib module。

其次定义我们的注解类:

有了这个注解的类,我们就可以在我们的MainAcitivity先用起来,虽然此时这个注解还并未起到什么作用。

到这里要稍微想一下,此时我们要做的是 通过注解来将R.id.xx 赋值给对应的field,也就是你定义的那些view对象(例如红框中的tv),对于我们的lib工程来说,因为是MainActivity 要依赖lib,自然你lib不可以依赖Main所属的app工程了,这里有2个原因:
A依赖B ,B依赖A的循环依赖是肯定会报错的;
既然你要做一个lib 那你肯定不能依赖使用者的宿主 否则怎么能叫lib呢?
所以这个问题就变成了,lib工程 只能拿到Acitivty,拿不到宿主的MainActivity , 既然拿不到宿主的MainActivity,那我怎么知道这个activity有多少个field?这里就要用到反射了。
public class BindingView {public static void init(Activity activity) {Field[] fields = activity.getClass().getDeclaredFields();for (Field field : fields) {//获取 被注解BindView annotation = field.getAnnotation(BindView.class);if (annotation != null) {int viewId = annotation.value();field.setAccessible(true);try {field.set(activity, activity.findViewById(viewId));} catch (IllegalAccessException e) {e.printStackTrace();}}}}}
最后我们在宿主的MainActivity中调用一下这个方法 即可:
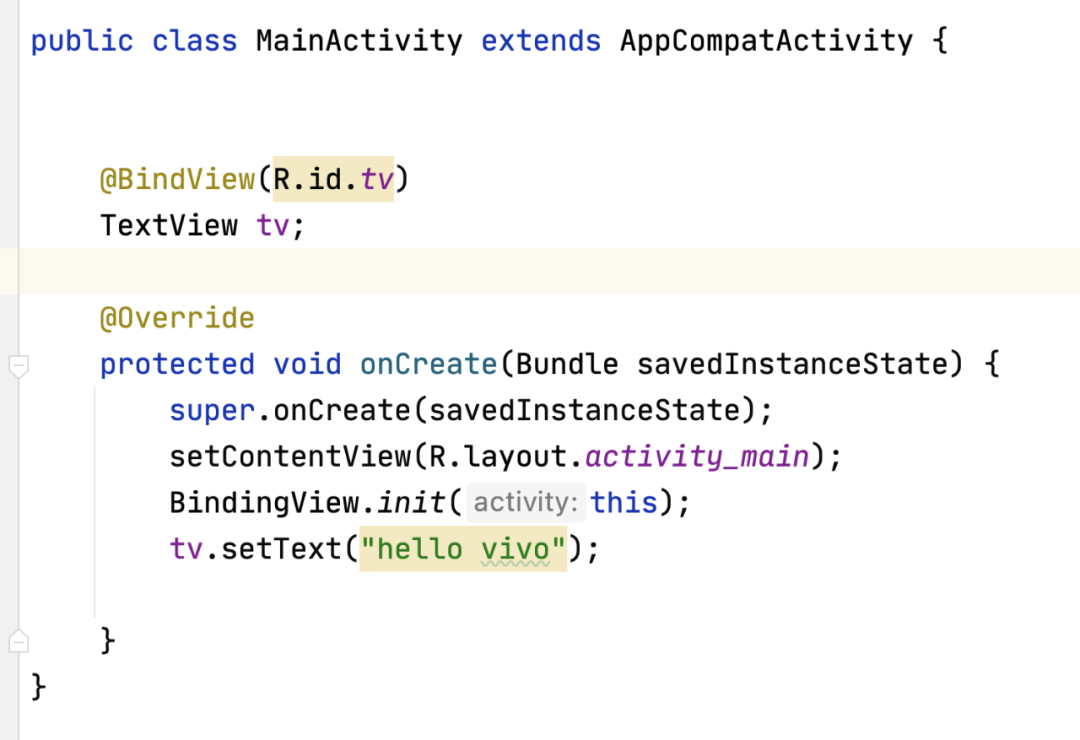
到这里其实有人就要问了,这个运行时注解看起来也不难啊,为啥好像用的人不是很多?问题就出在刚才反射的那堆方法里,反射大家都知道 会对Android运行时带来一些性能损耗,而这里的代码是一段循环, 也就是说这里的代码会随着你使用lib的Activity的界面复杂程度的提高 而变得越来越慢,这是一个会随着你界面复杂度提高而逐步劣化的过程, 单次反射对于今天的手机来说几乎已经不存在什么性能消耗了,但是这种for循环中使用反射还是尽量少用。
三、手写编译期注解
为了解决这个问题,就要使用编译期注解。现在我们来尝试用编译期注解来解决上述的问题。前面我们说过,运行期注解可以用反射来拿到宿主的field 从而完成需求,为了解决反射的性能问题,我们其实想要的代码是这样的:
我们可以在app 的module 中新建一个MainActivityViewBinding的类:

然后在我们的BindingView(注意我们的BindingView是在lib module下的)中来调用这个方法不就解决这个反射的问题了吗?

但是这里会有个问题 就是你既然是一个lib 你不能依赖宿主 ,所以在lib Module 中你其实拿不到 MainActivityViewBinding 这个类的,还是得利用反射。

可以看一下上面注释掉的代码,为啥不直接字符串写死?因为你是lib库你当然得是动态的,不然怎么给别人用?其实就是获取宿主的class名称然后加上一个固定的后缀ViewBinding 即可。这个时候 我们就拿到这个Binding的class了,对吧,剩下就是调用构造方法即可。
public class BindingView {public static void init(Activity activity) {try {Class bindingClass = Class.forName(activity.getClass().getCanonicalName() + "ViewBinding");Constructor constructor = bindingClass.getDeclaredConstructor(activity.getClass());constructor.newInstance(activity);} catch (ClassNotFoundException | NoSuchMethodException e) {e.printStackTrace();} catch (IllegalAccessException e) {e.printStackTrace();} catch (InstantiationException e) {e.printStackTrace();} catch (InvocationTargetException e) {e.printStackTrace();}}}
看下此时的代码结构:
有人这里要问,这里你不还是用了反射么,对! 这里虽然用了反射,但是我这里的反射只会调用一次,不管你的activity有都少field,在我这里反射方法都只会执行一次。所以性能肯定是比之前的方案要快很多倍的。接着看,虽然此刻代码可以正常运行,但是还有一个问题, 虽然我可以在lib中调用到我们app宿主的类的构造方法,但是,宿主的这个类依旧是我们手写的啊?那你这个lib库 还是没有起到任何可以让我们少写代码的作用。
这个时候就需要我们的apt 出场了,也就是编译期注解的核心部分了。我们创建一个Java Library,注意是Java lib不是android lib,然后在app module中引入他。
注意 引入的方式 不是imp了,是annotation processor ;
然后我们来修改一下lib_processor,首先创建一个 注解处理类:
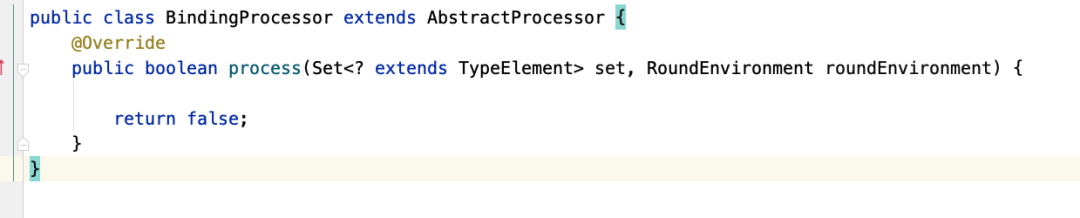
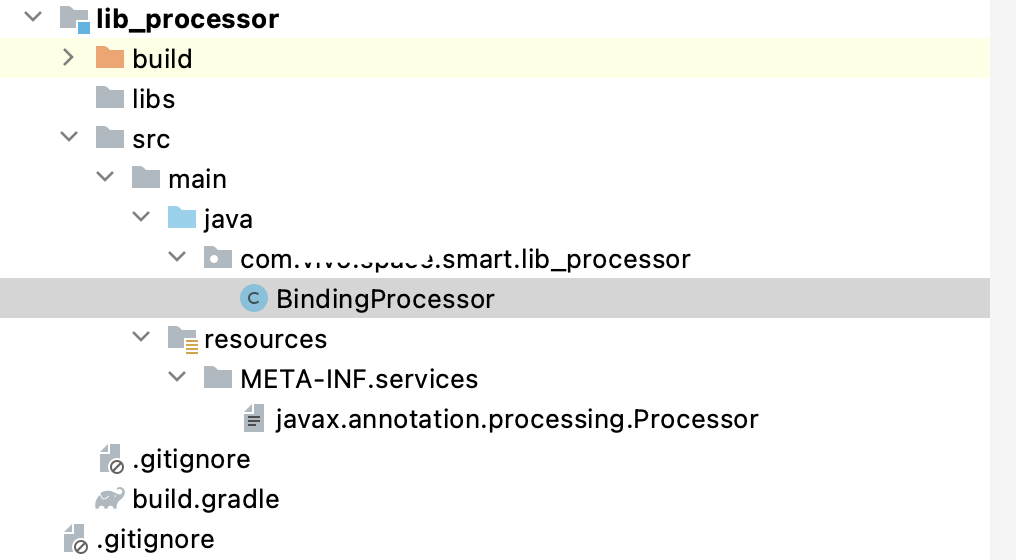
再创建文件resources/META-INF/
services/javax.annotation.processing.Processor ,这里要注意 文件夹创建不要写错了。
然后再这个Processor指定 一下我们的注解处理器即可:
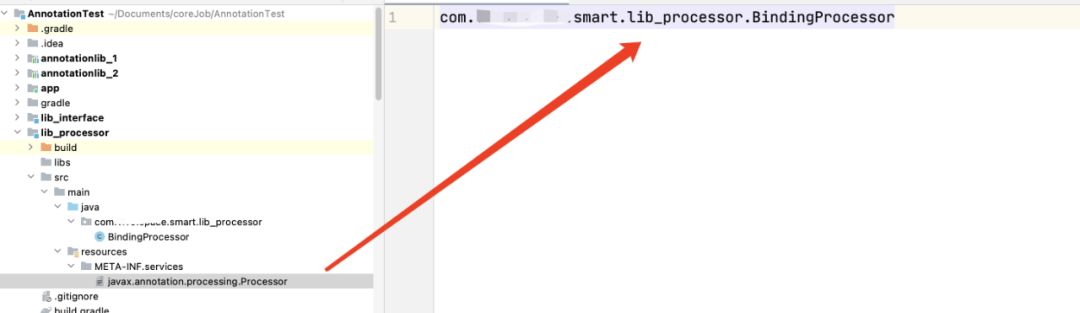
到这里还没完,我们得告诉这个注解处理器 只处理我们的BindView注解即可,否则这个注解处理器默认处理全部注解 速度就太慢了,但是此时 我们的BindView这个注解类还在lib仓里面,显然我们要调整一下我们的工程结构:

我们再新建一个Javalib,只放BindView即可,然后让我们的lib_processor和app 都依赖这个lib_interface即可。再稍微修改一下代码,此时我们是编译期处理,所Policy不用是runtime了。
(RetentionPolicy.SOURCE)(ElementType.FIELD)public BindView {int value();}
public class BindingProcessor extends AbstractProcessor {Messager messager;public synchronized void init(ProcessingEnvironment processingEnvironment) {messager = processingEnvironment.getMessager();messager.printMessage(Diagnostic.Kind.NOTE, " BindingProcessor init");super.init(processingEnvironment);}public boolean process(Set set, RoundEnvironment roundEnvironment) {return false;}//要支持哪些注解public SetgetSupportedAnnotationTypes() {return Collections.singleton(BindView.class.getCanonicalName());}}
到此我们的大部分工作就处理完毕了。再看一下代码结构(这里的代码结构一定要理解清楚为什么这样设计,否则你是学不会编译期注解的)。
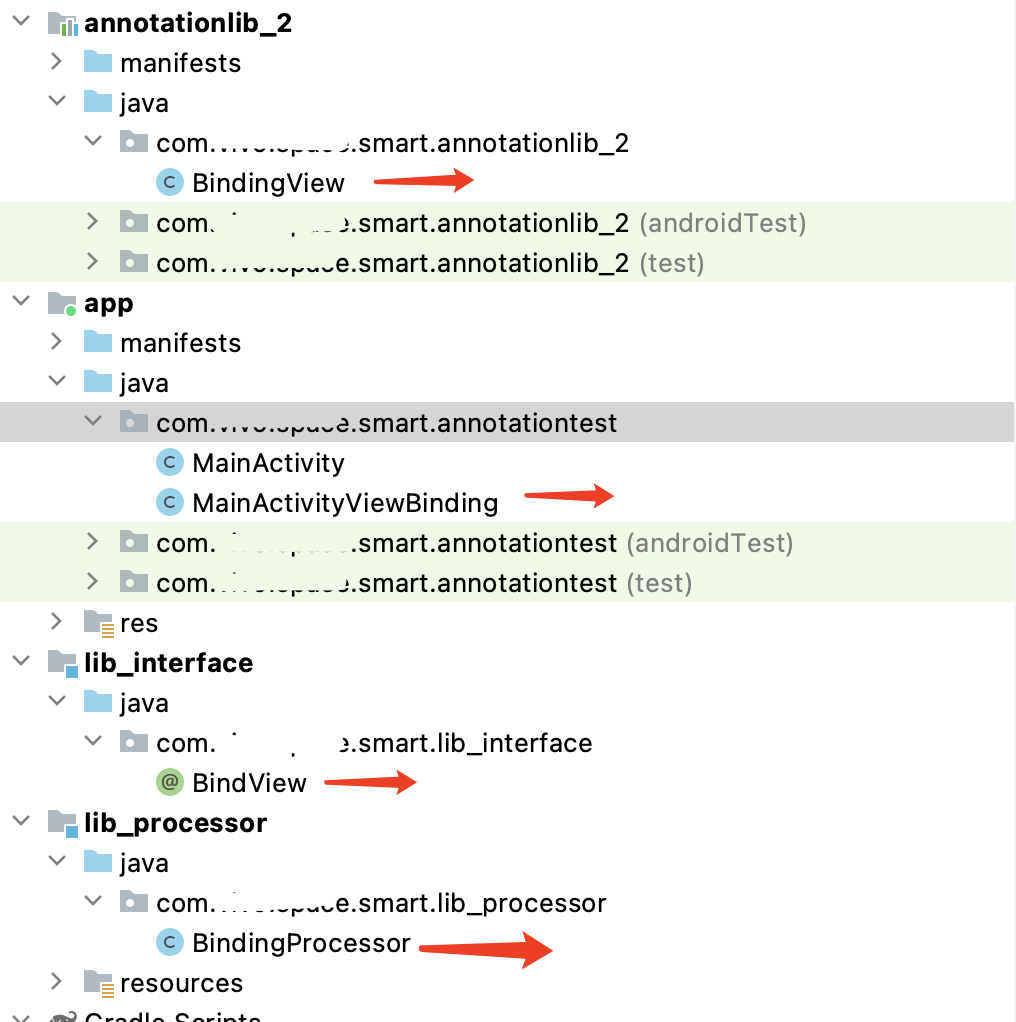
我们现在已经能够做到 通过 lib 这个sdk 调用到MainActivityViewBinding这个里面的方法,但是他 还在app仓是我们手写的,不太智能,还没办法用。我们需要在注解处理器里面 ,动态的生成这个类,只要能完成这个步骤,那我们的SDK也就基本完成了。
这里要提一下,很多人注解始终学不会就是卡在这里,因为太多的文章或者教程上来就是Javapoet 那一套代码,压根学不会,或者只能复制粘贴别人的东西,稍微变动一下就不会了,其实这里最佳的学习方式是先用StringBuffer 字符串拼接的方式 拼出我们想要的代码就可以了,通过这个字符串拼接的过程 来理解对应的api以及生成java代码的思路,然后最后再用JavaPoet来优化代码即可。
我们可以先思考一下, 如果用字符串拼接的方式来做这个生成类的操作要完成哪些步骤。
首先要获取哪些类使用了我们的BindView注解;
获取这些类中使用了BindView注解的field以及他们对应的值;
拿到这些类的类名称以便我们生成诸如MainActivityViewBinding这样的类名;
拿到这些类的包名,因为我们生成的类要和注解所属的类属于同一个package 才不会出现field 访问权限的问题;
上述条件都具备以后 就用字符串拼接的方式 拼接出我们想要的java代码 即可。
这里就直接上代码了,重要部分 直接看注释即可,有了上面的步骤分析再看代码注释应该不难理解。
public class BindingProcessor extends AbstractProcessor {Messager messager;Filer filer;Elements elementUtils;public synchronized void init(ProcessingEnvironment processingEnvironment) {//主要是输出一些重要的日志使用messager = processingEnvironment.getMessager();//你就理解成最终我们写java文件 要用到的重要 输出参数即可filer = processingEnvironment.getFiler();//一些方便的utils方法elementUtils = processingEnvironment.getElementUtils();//这里要注意的是Diagnostic.Kind.ERROR 是可以让编译失败的 一些重要的参数校验可以用这个来提示用户你哪里写的不对messager.printMessage(Diagnostic.Kind.NOTE, " BindingProcessor init");super.init(processingEnvironment);}private void generateCodeByStringBuffer(String className, Listelements) throws IOException { //你要生成的类 要和 注解的类 同属一个package 所以还要取 package的名称String packageName = elementUtils.getPackageOf(elements.get(0)).getQualifiedName().toString();StringBuffer sb = new StringBuffer();// 每个java类 的开头都是package sth...sb.append("package ");sb.append(packageName);sb.append(";\n");// public class XXXActivityViewBinding {final String classDefine = "public class " + className + "ViewBinding { \n";sb.append(classDefine);//定义构造函数的开头String constructorName = "public " + className + "ViewBinding(" + className + " activity){ \n";sb.append(constructorName);//遍历所有element 生成诸如 activity.tv=activity.findViewById(R.id.xxx) 之类的语句for (Element e : elements) {sb.append("activity." + e.getSimpleName() + "=activity.findViewById(" + e.getAnnotation(BindView.class).value() + ");\n");}sb.append("\n}");sb.append("\n }");//文件内容确定以后 直接生成即可JavaFileObject sourceFile = filer.createSourceFile(className + "ViewBinding");Writer writer = sourceFile.openWriter();writer.write(sb.toString());writer.close();}public boolean process(Setextends TypeElement> set, RoundEnvironment roundEnvironment) {// key 就是使用注解的class的类名 element就是使用注解本身的元素 一个class 可以有多个使用注解的fieldMap<String, List> fieldMap = new HashMap<>(); // 这里 获取到 所有使用了 BindView 注解的 elementfor (Element element : roundEnvironment.getElementsAnnotatedWith(BindView.class)) {//取到 这个注解所属的class的NameString className = element.getEnclosingElement().getSimpleName().toString();//取到值以后 判断map中 有没有 如果没有就直接put 有的话 就直接在这个value中增加一个elementif (fieldMap.get(className) != null) {ListelementList = fieldMap.get(className); elementList.add(element);} else {Listelements = new ArrayList<>(); elements.add(element);fieldMap.put(className, elements);}}//遍历map,开始生成辅助类for (Map.Entry<String, List> entry : fieldMap.entrySet()) { try {generateCodeByStringBuffer(entry.getKey(), entry.getValue());} catch (IOException e) {e.printStackTrace();}}return false;}//要支持哪些注解public Set<String> getSupportedAnnotationTypes() {return Collections.singleton(BindView.class.getCanonicalName());}}
最后看下效果:
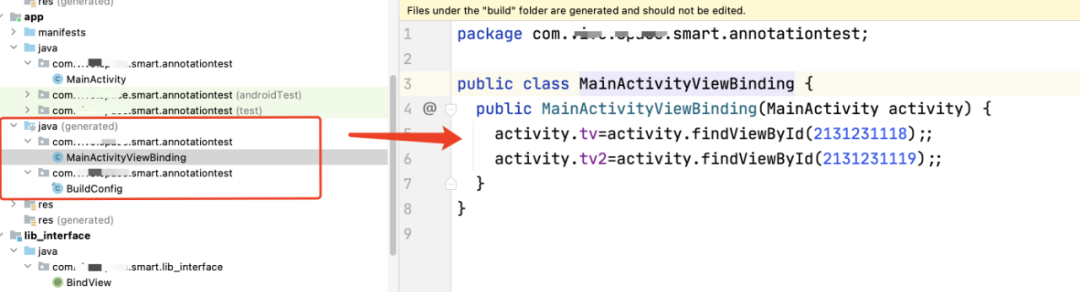
虽然生成的代码格式不太好看,但是运行起来是ok的。这里要注意一下Element 这个接口,实际上使用编译期注解的时候 如果能够理解了Element,那后续的工作就简单不少。

主要关注Element的这5个子类即可,举个例子:
package com.smart.annotationlib_2;//PackageElement |表示一个包程序元素// TypeElement 表示一个类或接口程序元素。public class VivoTest {//VariableElement |表示一个字段、enum 常量、方法或构造方法参数、局部变量或异常参数。int a;//VivoTest 这个方法 :ExecutableElement|表示某个类或接口的方法、构造方法或初始化程序(静态或实例),包括注释类型元素。//int b 这个函数参数: TypeParameterElement |表示一般类、接口、方法或构造方法元素的形式类型参数。public VivoTest(int b ) {this.a = b;}}
四、Javapoet生成代码
有了上面的基础 再用 Javapoet 写一遍字符串拼接来生成java代码的过程, 就不会难以理解了。
private void generateCodeByJavapoet(String className, Listelements ) throws IOException {//声明构造方法MethodSpec.Builder constructMethodBuilder =MethodSpec.constructorBuilder().addModifiers(Modifier.PUBLIC).addParameter(ClassName.bestGuess(className), "activity");//构造方法里面 增加语句for (Element e : elements) {constructMethodBuilder.addStatement("activity." + e.getSimpleName() + "=activity.findViewById(" + e.getAnnotation(BindView.class).value() + ");");}//声明类TypeSpec viewBindingClass =TypeSpec.classBuilder(className + "ViewBinding").addModifiers(Modifier.PUBLIC).addMethod(constructMethodBuilder.build()).build();String packageName = elementUtils.getPackageOf(elements.get(0)).getQualifiedName().toString();JavaFile build = JavaFile.builder(packageName, viewBindingClass).build();build.writeTo(filer);}
这里要提一下,现在越来越多的人使用Kotlin语言开发app,你甚至可以使用https://github.com/square/kotlinpoet 来直接生成Kotlin代码。有兴趣的可以尝试一下。
五、编译期注解的总结
首先是大家关注的性能方面,对于运行时注解来说,会产生大量的反射代码,而且反射调用的次数会随着项目复杂度的提高而变的越来越多,是一个逐步劣化的过程,而对于编译期注解来说,反射的调用次数是固定的,他并不会随着项目复杂度的提高而变的性能越来越差,实际上对于大多数运行时注解的项目都可以通过编译期注解来大幅提高框架的性能,比如著名的Dagger、EventBus 等等,他们的首个版本都是运行时注解,后续版本都统一替换成了编译期注解。
其次回顾一下前面我们编译期注解的开发流程以后,可以得出以下几点结论:
编译期注解只能生成代码,但是不能修改代码;
注解生成的代码 必须要手动被调用,他自己是不会被调用的;
对于SDK的编写者来说,即使是编译期注解,往往也免不了至少要走一次反射,而反射的作用主要就是调用你注解处理器生成的代码。
这里可能会有小伙伴问,既然编译期注解只能生成代码不能修改代码,那作用很有限啊,为啥不直接用类似于ASM 、Javassist 等字节码工具呢,这些工具不但可以生成代码而且还可以修改代码,功能更强劲。因为这些字节码工具生成的直接是class,且写法复杂容易出错,也不易于调试,小规模写一下类似于防止快速点击之类的东西还可以,大规模开发第三方框架其实也挺不方便的,远远不如编译期注解来的效率高。
此外,再仔细想想,我们前文中提到的编译期注解的写法做成第三方库给别人使用以后,还是需要使用者手动的在合适的时机调用一下 “init” 方法的,但是有些出色的第三方库可以做到连init方法都不需要使用者手动调用了,使用起来非常方便,这又是怎么做到的?其实也不难,多数情况都是这些第三方库用编译期注解生成了代码以后,再配合ASM等字节码工具直接帮你调用了init方法 ,从而让你免去手动调用的过程。核心仍旧是编译期注解,只不过是用字节码工具省略了一步而已。