
为 ModelArts JupyterLab 撸一个汉化插件
❝如何持续输出?是一直困扰着我的难题。想来想去,原来是因为没有输入,对,就是每天没有学习新的知识;造成的后果也不言而喻--工作七年了经验值接近零!今天偶然看到一个小工具的源码,打开了我的思路,因此,我想为 ModelArts JupyterLab 打造一款专属 Chrome 插件!当然此方法理论上适合任何定制化汉化(或多语言)插件,请看 Copy 攻城狮如何 Copy !
❞
背景概要
什么是 ModelArts?
ModelArts 是华为云一站式 AI 开发平台,涵盖了 AI 应用开发中数据准备、训练、评估、部署全流程和端、边、云全场景;小白开发者可以借助 ModelArts 轻轻松松从零到一开发属于自己的 AI 应用,像 Copy 攻城狮本大狮使用 ModelArts 不费吹灰之力就完成了“蚂蚁牙黑”的视频合成[1];大神工程师使用 ModelArts 能“炼丹好好炼丹炼好丹”,也不乏一些高端应用,比如 @Tianyi_Li 实现的“自动驾驶[2]”。当然,借力 ModelArts,AI 在各行各业实现了赋能,比如通过 ModelArts 自动学习能力构建并完善声音模型实现雨林的盗伐监听,实现了保护雨林的 AI 应用;借助 ModelArts 的海量数据预处理及智能标注、大规模分布式训练及深度学习,实现优质的个性化内容精准触达……如果您想初步了解 ModelArts,希望我的历史博文发挥作用--云享 MindTalks 第十三期:ModelArts 让 AI 应用开发更简单[3]。什么是 JupyterLab?
JupyterLab 是Project Jupyter[4]的下一代基于 Web 的用户界面,用于 Jupyter Notebook、代码和数据的基于 Web 的交互式开发环境,而Project Jupyter[5]的存在是为了开发跨多种编程语言的交互式计算的开源软件,开放标准和服务。常常用在数据科学、科学计算和机器学习中的各种工作流程,因此也经常被用作 AI 应用开发及数据分析的辅助工具。而 ModelArts JupyterLab 是常用的开发环境,您可以用来学习机器学习中的数学[6](PS:本大狮计划跟老齐前辈学习学习),可以玩玩爬虫[7]或者数据可视化……不过对于“English is very pool”的我,面对 JupyterLab 全英文的操作界面,尤其是我开了 Google 翻译插件之后,我彻底懵圈了!看法?跑?吉特?神翻译啊!怎么办?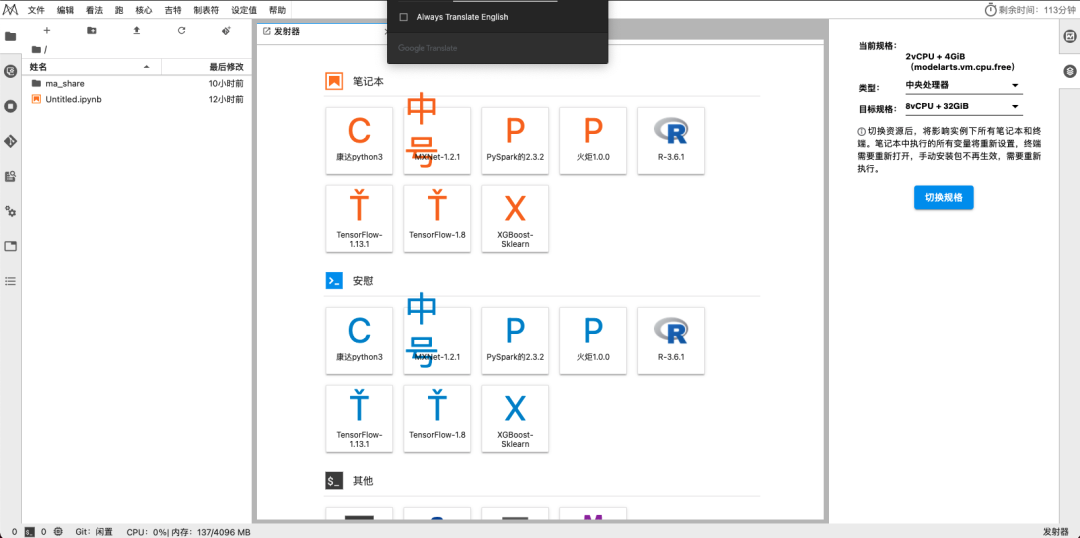
机缘巧合
有时候灵感就来源于“跨界”。最近计划实现一个野生动物保护的公益小程序,需要自己画原型并设计 UI,了解到目前最流行最推荐的工具是 「Figma[8]」(是念费伽马吗?),当然,同样是全英文,不过国内硬核玩家已经编写了汉化小插件--FigmaCN[9],这是中文 Figma 插件,由设计师人工翻译校验。通过下载查看 FigmaCN 的源码,我了解到原来“开发”汉化的 Chrome 插件这么简单,于是就有了汉化 ModelArts JupyterLab 的想法,刚好也查了资料,了解到目前 JupyterLab 3.0+已经有中文插件可以使用,是由一位热心老外贡献的--jupyterlab-language-pack-zh-CN[10],不过似乎体验还有待优化。不过,ModelArts 上的 JupyterLab 暂时是 2.0 的版本,因此我萌生了自己制作汉化插件的想法,希望通过汉化之后的 JupyterLab 学习更多的技巧。Just Do IT!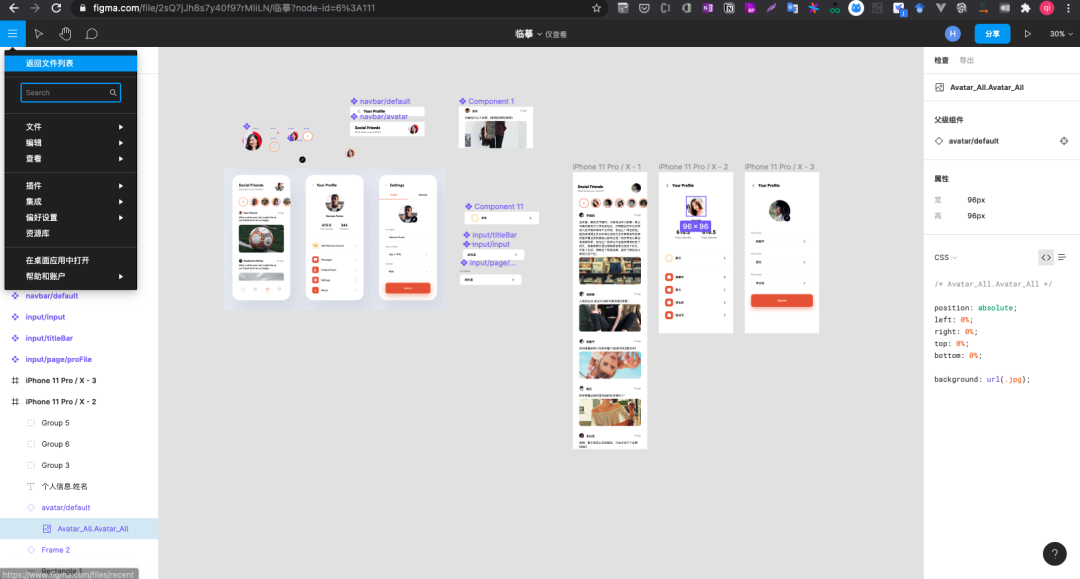
文档先行
套用一句老话:“道路千万条,文档第一条”。开发不看文档,那是真的牛;开发不写文档,也是真的牛!当我想开发 Chrome 插件的时候,第一条路可能最合适的就是看官方的开发文档了--扩展程序开发文档[11]。据我多年的 HW 开发经验,阅读文档时,您可能就会看到一个“Hello World”;当然,Chrome 插件开发也不例外。开发 Chrome 插件您可能需要掌握 WEB 开发的三大剑--HTML、CSS、JavaScript,根据文档,并参考开源库GoogleChrome/chrome-extensions-samples[12],开始我们的 Chrome 插件“Hello World 之旅"(顺便给官方文档提了一个**PR[13]**)。
目前 Chrome 插件的主程序已经更新到 V3 版本了,使用 MV3 的扩展将在安全性,隐私性和性能方面得到增强;此外还可以使用 MV3 中采用的更多现代开放式 Web 技术,例如 Service Workers 和 Promise。因此,我们基于第三代 Chrome 插件开发。
先新建一个目录,取名为Hello World,包含三个文件--background.js、hello.html、manifest.json,从后缀名可以看出一些端倪,.json是配置文件也是插件的描述文件,.js是逻辑代码文件,.html是页面文件;这是一个简单的插件雏形。具体代码如下:
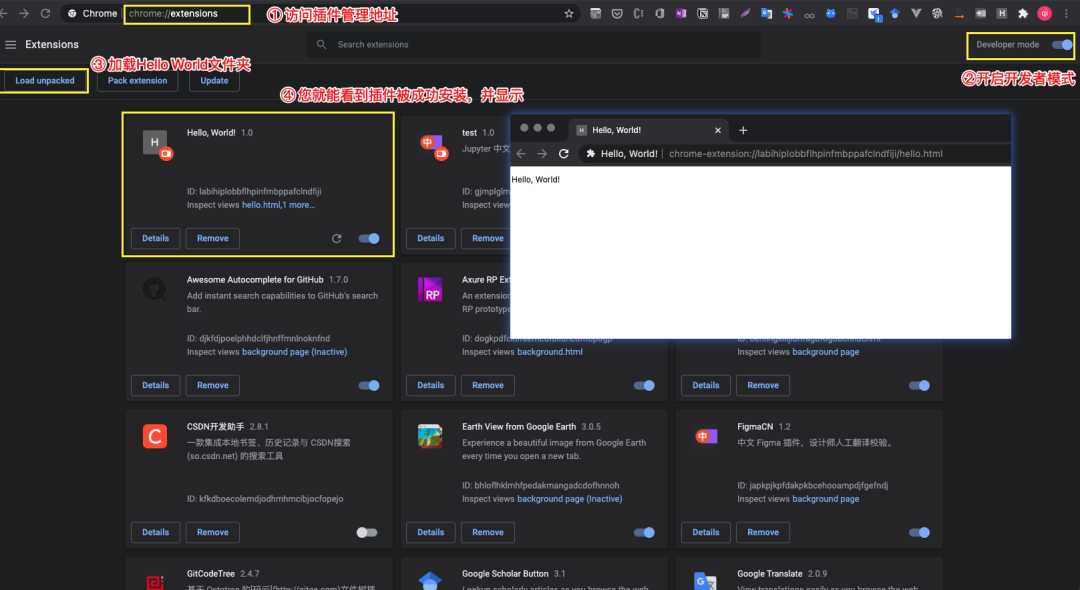
简单的代码,实现的功能就是安装完插件就打开 hello.html ,要想预览效果需要将本地浏览器的插件应用开启开发者模式。官方文档给出的步骤如下:
① chrome://extensions 在浏览器中导航到。您还可以通过点击多功能框右上角的 Chrome 菜单,将鼠标悬停在“更多工具”上,然后选择扩展程序来访问此页面。
② 选中“开发人员模式”旁边的框。
③ 单击“加载解压缩的扩展名”,然后为“ Hello 扩展名”扩展名选择目录。
编写插件
我们先来看看 MV3 规定的 manifest.json 改如何编写,打开文档mv3/manifest[14],您就能看到一份 json,必填的字段:
"manifest_version": 3, // 使用MV3必填 3
"name": "My Extension", // 插件名称
"version": "versionString", // 插件版本
其他的参数按需填写,其中我比较关心的是图标及其他文件加载,了解到 icons 字段可以定义图标,content_scripts可以注入内容脚本,background可注入后台脚本,值得注意的是 MV3 相比 MV2,不再无法加载 JavaScript 或 Wasm 文件之类的远程代码,也就是说我们所有的逻辑必须在本地完成(暂时这么理解)。因此,我的配置文件如下:
{
"name": "StartAI",
"version": "0.1",
"manifest_version": 3,
"short_name": "StartAI",
"description": "ModelArts 工具集,JupyterLab 汉化插件,学AI就用 ModelArts,学AI就上 huaweicloud.ai。",
"homepage_url": "http://huaweicloud.ai",
"icons": {
"16": "images/icon16.png",
"24": "images/icon24.png",
"32": "images/icon32.png",
"48": "images/icon48.png",
"128": "images/icon128.png"
},
"background": {
"service_worker": "background.js"
},
"content_scripts": [
{
"matches": ["*://notebook01-modelarts-cnnorth4.huaweicloud.com/*"],
"js": ["js/content.js"],
"run_at": "document_end",
"all_frames": true
}
]
}
重点介绍一下content_scripts,这里配置的是我们的核心逻辑,这段配置的大概含义是:当浏览器访问的 url 匹配到 matches 字段中的网站时,等待页面加载完成,执行我们的核心逻辑。通过上面的配置文件,也大概猜的出我们这个插件的目录结构:
hello-world
├─ images
│ ├─ icon128.png
│ ├─ icon16.png
│ ├─ icon24.png
│ ├─ icon32.png
│ └─ icon48.png
├─ js
│ └─ content.js
├─ background.js
└─ manifest.json
background.js中写的是安装插件成功时打开一个新的 tab,显示我们想要显示的内容,如引导页:
chrome.runtime.onInstalled.addListener(async () => {
// 此处可打开本地页面
// let url = chrome.runtime.getURL("hello.html");
// let tab = await chrome.tabs.create({ url });
// console.log(`Created tab ${tab.id}`);
chrome.tabs.create({
url: "http://huaweicloud.ai",
});
});
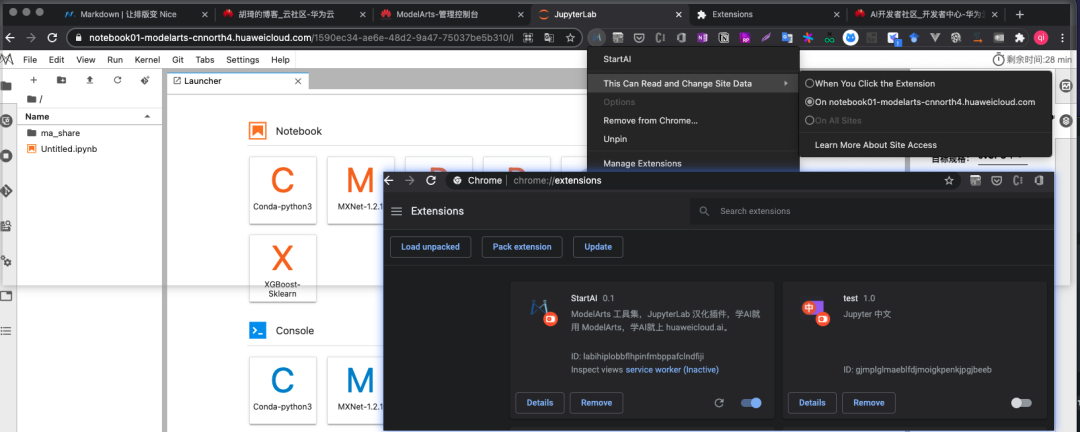
点击插件中心 Update 按钮之后,就会打开我们设置的网页,当匹配到我们预设的网站时,插件就被激活,明显会看到图标被点亮。看了半天,似乎发现原来 Chrome 插件开发这么简单!
接着就是核心逻辑--汉化,思路是通过MutationObserver[15]监听 DOM 何时更改,DOM 的任何变动,比如节点的增减、属性的变动、文本内容的变动,这个 API 都可以捕获到,因此当我们在页面上进行操作时,都能实时动态翻译我们匹配好的内容。代码实现如下:
// contant.js
// 定义临时空数组
let allData = [];
// 中英文匹配
const jsonData = {
// "": {
// "domain": "jupyterlab",
// "language": "zh-CN",
// "plural_forms": "nplurals=1; plural=0;",
// "version": "3.0.0b4"
// },
"\nConnected: %1": [
"\n\u5df2\u8fde\u63a5: %1"
],
"\nCreated: %1": [
"\n\u521b\u5efa\u65f6\u95f4\uff1a%1"
],
// …… 此处省略 2400 行,详见 https://github.com/jupyterlab/language-packs
}
// 处理数据,形如:[["File", "文件"],["Edit","编辑"]]
allData = Object.keys(jsonData).map(item=>([item,jsonData[item][0]]))
// 引入观察器 MutationObserver
let MutationObserver = window.MutationObserver || window.WebKitMutationObserver;
// 观察器的配置(需要观察什么变动)
let MutationObserverConfig = {
childList: true,
subtree: true,
attributeFilter: ["data-label"],
characterData: true,
};
// 创建一个观察器实例并传入回调函数
let observer = new MutationObserver(function (mutations) {
let treeWalker = document.createTreeWalker(
document.body,
NodeFilter.SHOW_ALL,
{
acceptNode: function (node) {
if (node.nodeType === 3 || node.hasAttribute("data-label")) {
return NodeFilter.FILTER_ACCEPT;
} else {
return NodeFilter.FILTER_SKIP;
}
},
},
false
);
// 映射中文
let dataMap = new Map();
for (i in jsonData) {
if (i && !dataMap.has(i)) {
dataMap.set(i, jsonData[i][0]);
}
}
allData.forEach(([key, val]) => {
if (key && !dataMap.has(key)) {
dataMap.set(key, val);
}
});
let currentNode = treeWalker.currentNode;
// 替换
while (currentNode) {
if (currentNode.nodeType === 3) {
let key1 = currentNode.textContent;
if (dataMap.has(key1)) currentNode.textContent = dataMap.get(key1);
} else {
let key2 = currentNode.getAttribute("data-label");
if (dataMap.has(key2))
currentNode.setAttribute("data-label", dataMap.get(key2));
}
currentNode = treeWalker.nextNode();
}
});
// 开始观察目标节点
observer.observe(document.body, MutationObserverConfig);
最终的效果还算满意,基本能够使用全部已有的翻译数据,当然,源数据中存在未翻译项,比如["Notebook":["NoteBook"]],这样的数据会导致插件异常,从而使页面卡死,具体什么原因还没排查到,大概是因为死循环了,无意中踩过了这个坑。
发布
最后的发布,我不太愿意谈太多,主要不想给 Google 打广告,因为发布需要象征性的收取 5 刀,因此您可能需要全球信用卡。具体步骤如下:上传应用程序的过程很简单:
将应用程序的根目录(包含 manifest.json 文件的文件夹)压缩为.zip 文件。 交钱开通资格。 去到控制台单击添加新项目。 接受条款和服务协议。 使用“选择文件”对话框在系统中查找.zip 文件并选择。 其他信息维护及测试。
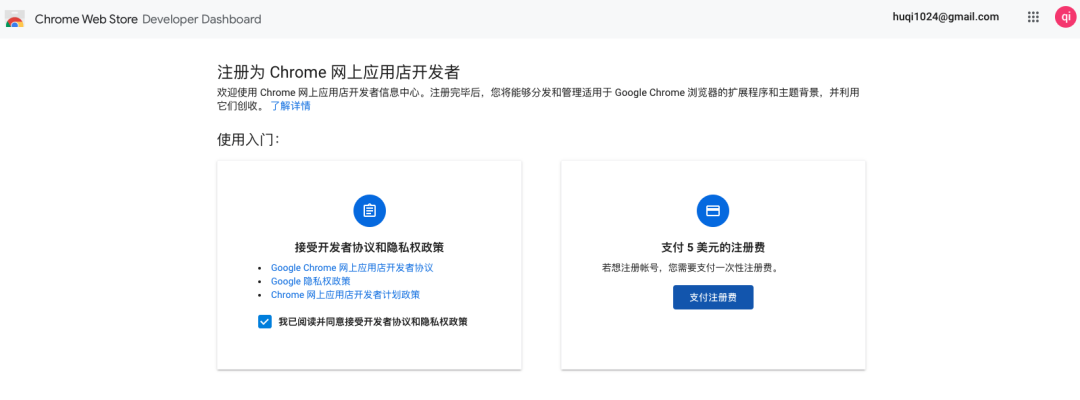
截止发稿,Copy 攻城狮翻箱倒柜还没找着信用卡,就先到这,待 Notebook 一键分享功能开发完毕之后再注册发布。
小结
总得来说,收获不少。一是解决了当前的需求,二是产出了一篇“水文”,三是贡献了一个 PR(Markdown 特供)。
源码地址:hu-qi/StartAI[16] (https://github.com/hu-qi/StartAI[17])
Reference
“蚂蚁牙黑”的视频合成: https://bbs.huaweicloud.com/blogs/245794
[2]自动驾驶: https://bbs.huaweicloud.com/blogs/226039
[3]云享 MindTalks 第十三期:ModelArts 让 AI 应用开发更简单: https://bbs.huaweicloud.com/blogs/246212
[4]Project Jupyter: https://jupyter.org/
[5]Project Jupyter: https://jupyter.org/
[6]机器学习中的数学: http://www.itdiffer.com/
[7]玩玩爬虫: https://bbs.huaweicloud.com/blogs/174634
[8]Figma: https://figma.com/
[9]FigmaCN: https://cn.figma.cool/
[10]jupyterlab-language-pack-zh-CN: https://github.com/jupyterlab/language-packs
[11]扩展程序开发文档: https://developer.chrome.com/docs/extensions/
[12]GoogleChrome/chrome-extensions-samples: https://github.com/GoogleChrome/chrome-extensions-samples
[13]PR: https://github.com/GoogleChrome/developer.chrome.com/pull/521
[14]mv3/manifest: https://developer.chrome.com/docs/extensions/mv3/manifest/
[15]MutationObserver: https://developer.mozilla.org/zh-CN/docs/Web/API/MutationObserver
[16]hu-qi/StartAI: https://github.com/hu-qi/StartAI
[17]https://github.com/hu-qi/StartAI: https://github.com/hu-qi/StartAI
