5 月30日,第 59 届 ISC 2022(国际超算大会)发布最新 Top500 榜单,美国田纳西州橡树岭国家实验室(ORNL)的 Frontier 成为第一个真正突破 Exascale 大关的超算,性能达到 1.102 exaflops,该榜单正式标志着超级计算新时代的到来。
Frontier 由 74 个 Cray EX 机柜组成,可容纳 9408 个节点,每个节点配备一个 AMD Milan「Trento」7A53 Epyc CPU 和四个 AMD Instinct MI250X GPU,GPU 总数为 37632。节点通过 HPE 的 Slingshot-11 互连连接。每个节点 CPU 支持 512GiB DDR4 内存,跨节点支持 512GiB HMB2e(每 GPU 128GiB)内存。Frontier 的 Linpack 性能为 1.102 exaflops,比 Top500 中的排名靠前的 7 个系统加起来还要快。来自田纳西州橡树岭国家实验室的 Thomas Zacharia 表示:「我们不能低估 0.1 的差距,一个 0.1 代表 100petaflops,0.1 看起来很小,很容易被四舍五入。但每个小数点都代表着一种巨大的能力。」Frontier 在 OLCF(美国橡树岭国家实验室领先运算机构)占地 372 平方米,聚合了 9.2 PB 的内存(4.6 PB 的 DDR4 和 4.6 PB 的 HBM2e),有 37 PB 的节点本地存储,并可访问 716 PB 的中心范围存储。四次登顶的日本超算富岳本次排在第二位,性能 442 petaflops,其采用 Arm A64FX 系统。部署在芬兰国家超算中心的 LUMI 排名第三,使其成为欧洲最强大超算系统。LUMI 实现了 151.90 Linpack petaflops,理论峰值可达到 214.3 petaflops,这个数字大约为 71% 的 Linpack 效率。IBM 的 Summit 排名第四、Sierra 排名第五;中国的神威太湖之光排名第六;美国劳伦斯伯克利实验室的国家能源研究科学计算中心(NERSC) 的 Perlmutter HPE Cray EX 排名第七;紧随其后的是英伟达 Selene 排在第八位;中国的天河 2A 排名第九。部署在法国国家大型计算中心的 Adastra 系统排名第十,其 Linpack 实现 46.1 Linpack petaflops,理论峰值为 61.6 千万亿次,Linpack 效率为 75%。值得一提的是,Top10 中新上榜的 3 台新系统(美国的 Frontier、芬兰的 LUMI 和 法国的 Adastra)都是采用了 HPE Cray EX235a 架构。仅仅在四年前,也就是 2018 年 6 月,整个 Top500 榜单首次以 1.22 exaflops 的总和超过 exaflops 大关。现在 Frontier 的单个系统算力就达到了 1.102 Exaflops。本次 Top500 榜单共迎来 39 个新系统,地域分布广泛。美国最多,有 9 个,其次是德国的 5 个。近十年来,中国首次没有新系统上榜,尽管如此,中国仍然拥有列表中最多的系统:173 个,而美国系统数量为 127 个,就系统数量而言,美国位居第二。然而,美国由于 Frontier 的性能显着拉长了领先优势。在国内的超级计算机计划中已有三个 E 级超算上马,这些系统本质上不是由 Top500 或 HPL 基准验证的,而是由戈登贝尔奖。其中一个是无锡超级计算中心运营的神威太湖之光(新机位于青岛)。另一个系统天河三号位于天津市。Tianhe-3 基于 Phytium 2000+ FTP Arm 芯片和 Matrix 2000+ MTP 加速器。该系统据报道已于去年秋天完成,估计可以提供 1.7 exaflops 的峰值性能,在 Linpack 上提供了略高于 1.3 exaflops 的性能。在汉堡举行的 ISC 2022 之前,有消息人士表示,中国正计划在 2025-2026 年的时间范围内制造一台 10 exaflops 的机器。另有消息人士称,有两台目标 2025 年上线的 10 exaflops 系统正在开发中,但现在更大的可能是在 2026 年只推出一台 10 exaflops 系统。与太湖之光一样,它将是神威架构,即基于 Alpha 核心。上海交通大学网络信息中心副主任,HPC 专家林新华表示,Top500 已成为事实上的实体名单。「中国顶级超级计算机的供应商和主机中心都在名单上,」他表示。「进入 Top500 是为了促进国际合作,但结果却适得其反。我们提交 Top500 并不是为了维持联系。」近年来,在 Top500 基准上的几家中国系统的支持实体和供应商确实被列入了美国实体名单。联想是 Top500 榜单上的常客,其参与基准测试的新系统数量最多(17 个),在 14 个新系统中,HPE 的数量位居第二(其中 7 个采用 AMD+AMD 节点,通过 Slingshot-11 连接,包括 三个 NNSA/LLNL 系统)。在所有 500 个系统中,按纯系统数量计算的阵容是联想(180 个)、HPE(84 个)和浪潮(50 个)。按性能份额比较的话,排名依次为:HPE(18.6%)、富士通(18.1%)和联想(15.1%)。 名单上没有新的英伟达系统。其自用的 Eos 超算将会展示它的最新实力,但为 Eos 提供算力的 DGX H100 节点预计直到下个季度才会发货。英伟达是该列表中 19 个系统的制造商,并且它合作参与了另外 5 个系统的构建,包括第五位的 Sierra、第 22 位的 Chervonenkis 、第 30 位的 Lassen、第 40 位的 Galushkin 和第 43 位的 Lyapunov。英特尔声称在 Top500 排行榜中占有 77.40% 的份额,这个数字低于六个月前的 81.60%。AMD 共有 94 个系统,在该列表中的份额已从六个月前的 14.60% 增长到 18.80%。IBM 的超算数量仍然未变是 9 个:第 4 名的 Summit、第 5 名的 Sierra、第 21 名的 Marconi-100、第 30 名的 Lassen、第 33 名的 PANGEA II、第 24 名的 AiMOS、第 160 名的 HPC2 第 205 名的 SuperMUC Phase2(与联想合作)和第 303 名的 Longhorn。参考内容:https://www.top500.org/news/ornls-frontier-first-to-break-the-exaflop-ceiling/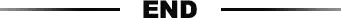
转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
推荐阅读
更多架构相关技术知识总结请参考“架构师全店铺技术资料打包”相关电子书(37本技术资料打包汇总详情可通过“阅读原文”获取)。
全店内容持续更新,现下单“全店铺技术资料打包(全)”,后续可享全店内容更新“免费”赠阅,价格仅收198元(原总价350元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。