
网易二面:Kafka为什么吞吐量大、速度快?
来源:cnblogs.com/starluke/p/12558952.html
Kafka是大数据领域无处不在的消息中间件,目前广泛使用在企业内部的实时数据管道,并帮助企业构建自己的流计算应用程序。
Kafka虽然是基于磁盘做的数据存储,但却具有高性能、高吞吐、低延时的特点,其吞吐量动辄几万、几十上百万。
但是很多使用过Kafka的人,经常会被问到这样一个问题,Kafka为什么速度快,吞吐量大;大部分被问的人都是一下子就懵了,或者是只知道一些简单的点,本文就简单的介绍一下Kafka为什么吞吐量大,速度快。
一、顺序读写
这里给出著名学术期刊 ACM Queue 上的性能对比图:
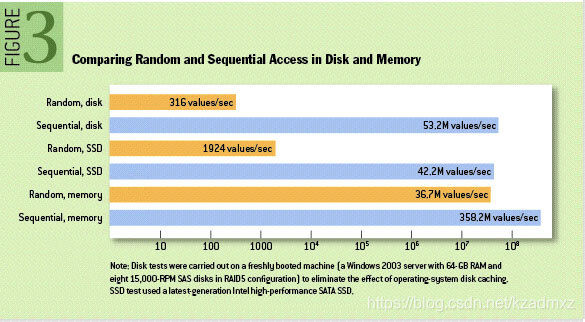
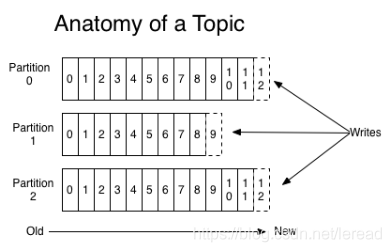
上图就展示了Kafka是如何写入数据的, 每一个Partition其实都是一个文件 ,收到消息后Kafka会把数据插入到文件末尾(虚框部分)。
这种方法有一个缺陷—— 没有办法删除数据 ,所以Kafka是不会删除数据的,它会把所有的数据都保留下来,每个消费者(Consumer)对每个Topic都有一个offset用来表示 读取到了第几条数据 。
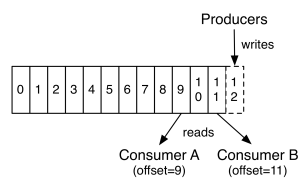
如果不删除硬盘肯定会被撑满,所以Kakfa提供了两种策略来删除数据。一是基于时间,二是基于partition文件大小。具体配置可以参看它的配置文档。
二、Page Cache
为了优化读写性能,Kafka利用了操作系统本身的Page Cache,就是利用操作系统自身的内存而不是JVM空间内存。这样做的好处有:
相比于使用JVM或in-memory cache等数据结构,利用操作系统的Page Cache更加简单可靠。
首先,操作系统层面的缓存利用率会更高,因为存储的都是紧凑的字节结构而不是独立的对象。
其次,操作系统本身也对于Page Cache做了大量优化,提供了 write-behind、read-ahead以及flush等多种机制。
再者,即使服务进程重启,系统缓存依然不会消失,避免了in-process cache重建缓存的过程。
通过操作系统的Page Cache,Kafka的读写操作基本上是基于内存的,读写速度得到了极大的提升。
三、零拷贝
linux操作系统 “零拷贝” 机制使用了sendfile方法, 允许操作系统将数据从Page Cache 直接发送到网络,只需要最后一步的copy操作将数据复制到 NIC 缓冲区, 这样避免重新复制数据 。示意图如下:
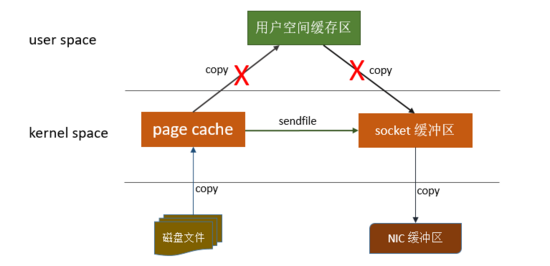
当Kafka客户端从服务器读取数据时,如果不使用零拷贝技术,那么大致需要经历这样的一个过程:
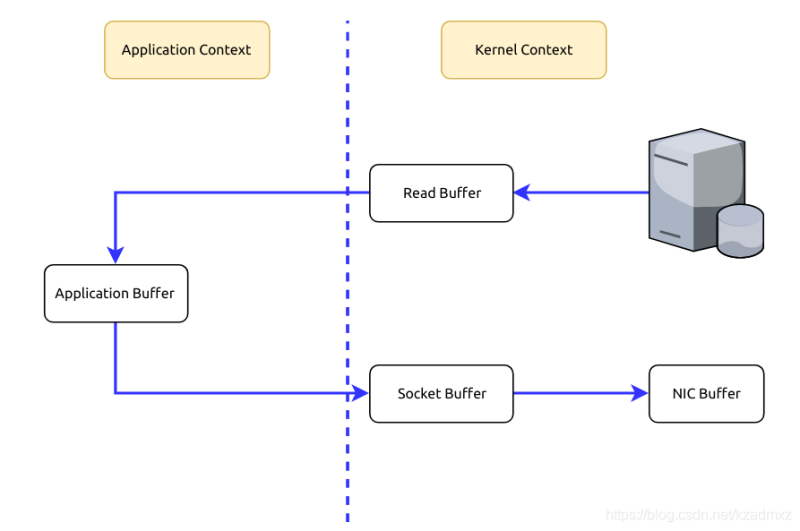
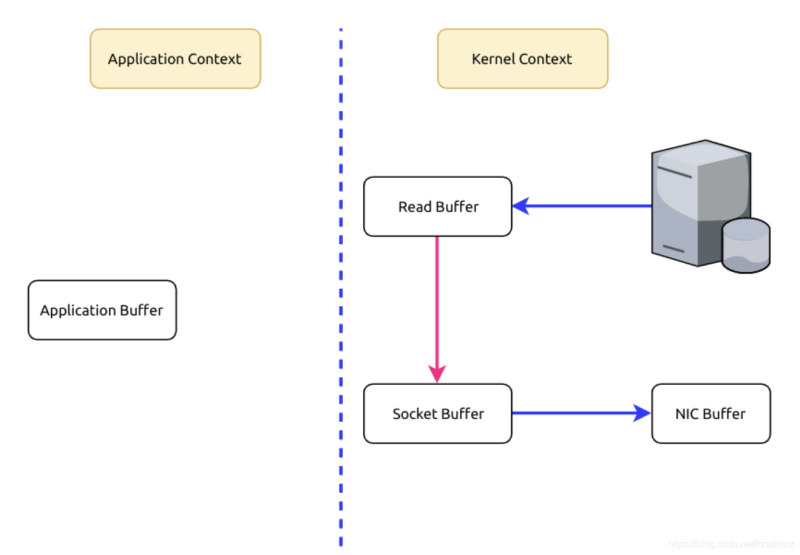
可见,这里的零拷贝并非指一次拷贝都没有,而是避免了在内核空间和用户空间之间的拷贝。如果真是一次拷贝都没有,那么数据发给客户端就没了不是?不过,光是省下了这一步就可以带来性能上的极大提升。
四、分区分段+索引
五、批量读写
Kafka数据读写也是批量的而不是单条的。
除了利用底层的技术外,Kafka还在应用程序层面提供了一些手段来提升性能。最明显的就是使用批次。在向Kafka写入数据时,可以启用批次写入,这样可以避免在网络上频繁传输单个消息带来的延迟和带宽开销。假设网络带宽为10MB/S,一次性传输10MB的消息比传输1KB的消息10000万次显然要快得多。
六、批量压缩
在很多情况下,系统的瓶颈不是CPU或磁盘,而是网络IO,对于需要在广域网上的数据中心之间发送消息的数据流水线尤其如此。进行数据压缩会消耗少量的CPU资源,不过对于kafka而言,网络IO更应该需要考虑。
5、37岁程序员被裁,120天没找到工作,无奈去小公司,结果懵了...