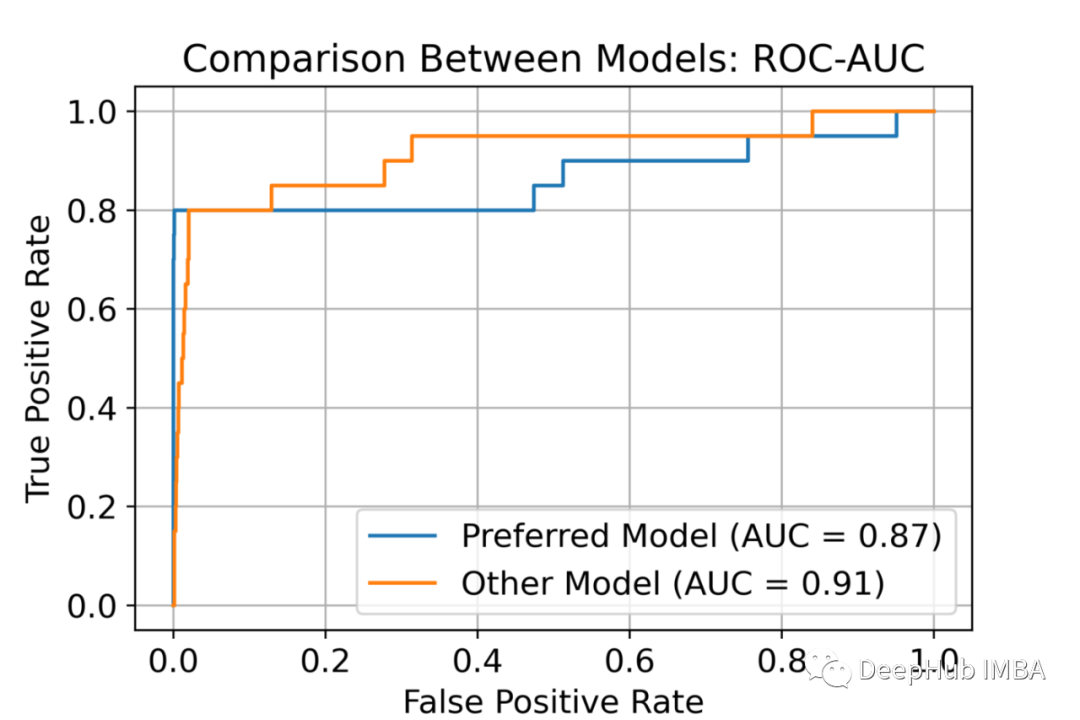
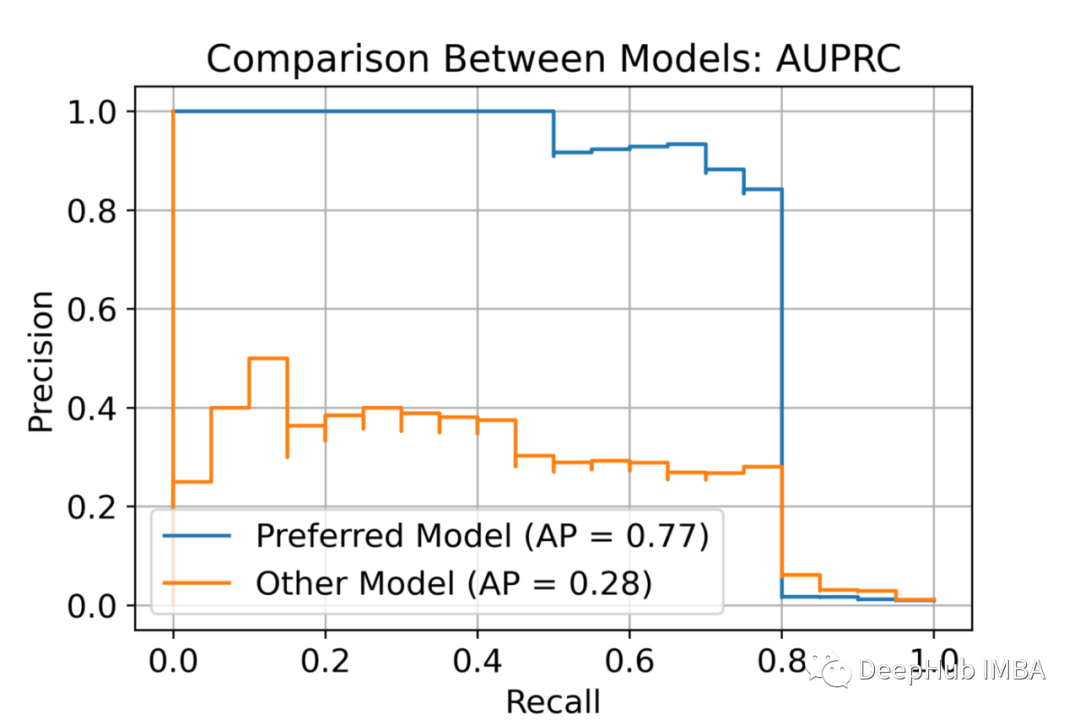
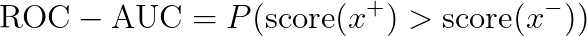尽管 ROC-AUC 包含了许多有用的评估信息,但它并不是一个万能的衡量标准。我们使用 ROC-AUC 的概率解释进行了实验来支持这一主张并提供了理论依据。AUPRC 在处理数据不平衡时可以为我们提供更多信息。 总体而言,ROC 在评估通用分类时很有用,而 AUPRC 在对罕见事件进行分类时是更好的方法。 如果你对本文的计算感兴趣,请看作者提供的源代码:https://github.com/1danielr/rocauc-auprc 引用:Davis, Jesse, and Mark Goadrich. “The relationship between Precision-Recall and ROC curves.” ICML. 2006.https://stats.stackexchange.com/questions/132777/what-does-auc-stand-for-and-what-is-itBuckley, Chris, and Ellen M. Voorhees. “Evaluating evaluation measure stability.” ACM SIGIR Forum. 2017.https://stats.stackexchange.com/questions/180638/how-to-derive-the-probabilistic-interpretation-of-the-auchttps://stats.stackexchange.com/questions/190216/why-is-roc-auc-equivalent-to-the-probability-that-two-randomly-selected-samples 作者:Daniel Rosenberg