
可能是全网写特征工程最通透的...
共 3273字,需浏览 7分钟
·
2022-01-01 19:56
特征工程到底是什么?今天是包大人出租车原创日更,因为正在出差去机场的路上...
前言
现在这个知乎上的回答,包大人那个还是处于排序第一的位置,在知乎上有158万 浏览, 2K+赞, 6K+收藏,2专业认可。
这在一个专业的问题上,这个数据其实还是不容易的。类比知乎上的一个问题,是明白了什么让你编程水平突飞猛进的。从我个人来讲的话,理解了特征工程的精髓,让我机器学习水平突飞猛进。今天旧瓶装新酒,再重答一下,用最白话的讲最深刻的道理。

从一道题讲起
当时很多回答的毛病在于侧重于"术",而忽略了"道"。讲了很多非常细节的操作方法,甚至把特征工程狭义理解成了数据的变换方法。
这里毛病很大的。
上来先出一道题目。
题目:请使用一个逻辑回归的模型,建模一个身材分类器,身材分偏胖和偏瘦两种,输入的特征有身高和体重。
这时候你发现,这个问题不是那么好“线性“解决的,线性解决的意思就是我拍两个系数加权,使用 sigmoid(ax+by+c)就搞定了。
事实上,我们很难单纯地从身高和体重决策出一个人的身材,你说姚明体重280斤,他真的一定就胖吗??别忘了他身高有226公分的。
这组数据可能超出了你的认知,只看数据不看照片,一下子不好说他是胖还是瘦。(其实挺胖的哈哈)
嗯,这个你看到那组数据,不好一下子说出来的感觉,就是机器学习里面非常关键的概念,“非线性”。
那么我们怎么解答这个问题呢?
方法有两个:
1.升级模型,把线性的逻辑回归加上kernel来增加非线性的能力。我们使用这个模型 sigmoid(ax+by+kx*y^(-2)+c),这个模型通过多项式核方法的升级,解决了低维空间线性模型不太好解决的问题。
2.特征工程,掏出体检报告上的BMI指数,BMI=体重/(身高^2)。这样,通过BMI指数,就能非常显然地帮助我们,刻画一个人身材如何。甚至,你可以抛弃原始的体重和身高数据。
好了,现在你大概对特征工程有点眉目了。
方式一在理论上对应的东西就是提升VC维,方式二就是让你dirty hand的特征工程。
在机器学习流程中的视角
我们再回头讲一下这个东西的重要性,特征工程是机器学习,甚至是深度学习中最为重要的一部分,也是课本上最不愿意讲的一部分,特征工程往往是打开数据密码的钥匙,是数据科学中最有创造力的一部分。因为往往和具体的数据相结合,很难优雅地系统地讲好。所以课本上会讲一下理论知识比较扎实的归一化,降维等部分,而忽略一些很dirty hand的特征工程技巧,和case by case的数据理解。
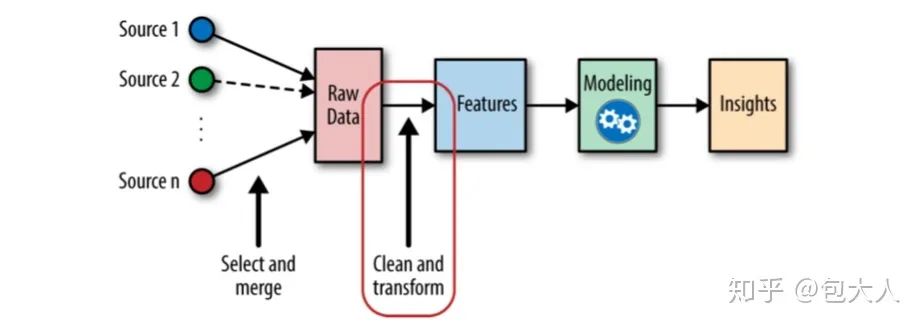
不妨我们再讲透一点,下面是一个经典的特征机器学习流程,输入的原始数据经过一步clean and transformer转化为建模的特征输入,最终得到模型。
建模就是从数据中学习到insights(洞见)过程,这个过程其实是很曲折的,他要经过数据的表达,模型的学习两步。
数据的表达就是原始数据经过clean and transformer得到features的过程,即为特征工程。
还是以具体的例子来讲。
我们回到刚才的身材分类器的例子上,在方式一我们使用了核方法给逻辑回归升维,方式二使用了特征方法。
要知道天下没有免费的午餐,在你使用核方法升维的时候,实际很难精炼出恰好是x*y^(-2)这样的多项式表达,你肯定是一股脑地把x*y,x^2*y, x*y^2 这些项都扔进去了。
这么暴力的操作,有两个问题,一是共线性,二是噪声。
第一、共线性的意思是几个项表达的含义是趋同的,保持了很强的线性关系,对于逻辑回归是致命的问题,因为他带来了权重的不稳定,要知道逻辑回归权重可是暗示了特征重要性的。
(要是你对这段话,不好理解的话,仔细学习下逻辑回归模型和共线性的理论,此处不单独展开)
第二、噪声让你的分类器学习到了一些不好的东西,对你的决策没有产生泛化的贡献,反而带跑偏你的模型,学习到了一些不是知识的边边角角。
特征工程类似于炼丹术士的精炼过程。
他的作用就是把人的知识融入到数据表达中,减轻模型的负担,让模型更容易学习到本质的知识。
从NN与GBDT讨论的视角
之间写过一篇文章,为什么GBDT可以超越深度学习,有读者说我是标题党,我结合这篇推文,继续把他翻出来。
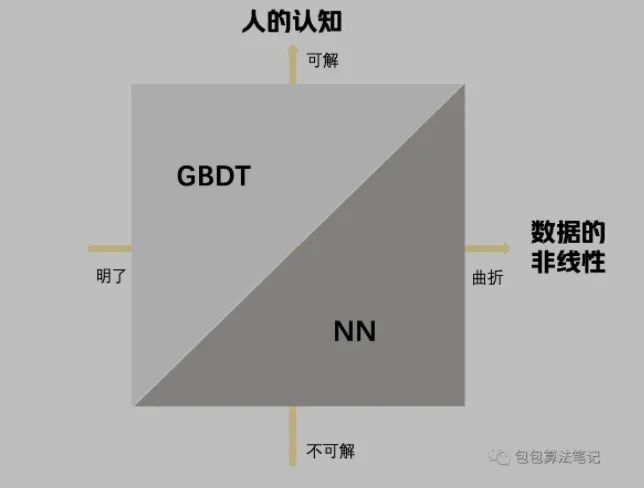
那篇文档里有个很重要的观点是这张图。
这个图表达意思是,在人的认知可解的时候,乃至超越数据的非线性,就是y>x那根斜对角线的上方,是GBDT可以超越神经网络的时候。
人的认知可解,对应着就是特征工程的难度和可行性。
还是不好理解,看下面这样一个具体的例子。
如果你对speech稍有了解,或者做过说话人验证/声纹识别(SVR)任务,你会知道,有一种特征工程叫做MFCC 特征,现在解决说话人本身特性的问题,前端还是无法离开MFCC,而我认为MFCC是一种非常有代表性的饱含了专家知识的特征工程,感兴趣的同学可以了解一下相关的知识。
如果你有了MFCC这样的工具,你用不太复杂的浅层NN(TDNN),都能取得超越输入原始语音采样序列,放到复杂transformer中的效果。
另外,在某些类型的数据上,特种工程很难施展拳脚,类似于id序列,典型的任务如NLP,CTR等。
NLP是人类知识凝练的字节单元,CTR是大规模的稀疏id序列,这两种数据上,虽然人的认知是到位了,但是不可解。特征工程施展不开。
而特征工程最能施展拳脚的地方就是工业界的异质表格(Tabulr)数据,同质数据是各列数据的单元要素接近,如文本对应字符,图片对应像素,语音对应语音frame。
这个结论在Yandex团队2021年论文 《Revisiting Deep Learning Models for Tabular Data》里印证了。这也是为什么早些年一票Kaggle比赛,清一色的XGB和LGB屠榜。
一言以蔽之的话,就是我之前文章的配图,好风凭借力,助我上青云。(写着写着怎么越来越像炒冷饭)
好风:在知识学习上恰当的模型。既不太复杂引入过多噪声和其他的问题,也没有太简单不足支撑,内在的机理有利于知识的学习。
借力:机器学习中使用特征工程的过程,人脑把数据经过处理,精炼,得到更接近结果的表达,更直白的可以得到预测目标。
特征工程的道与术
前面都在讲特征工程的道,而特征工程具体的术的话,其实也没有必要讲的特别详细了,但是我还是给你准备了一些关于术方面的资料的。
其实这部分真的没必要展开讲了,很多是熟能生巧,case by case,结合具体的业务的事情。
比如你们用的滑动验证码,这里面其实就有很多特征工程的东西,对鼠标的移动行为的各种角度的刻画,比如速度,加速度,角度等。
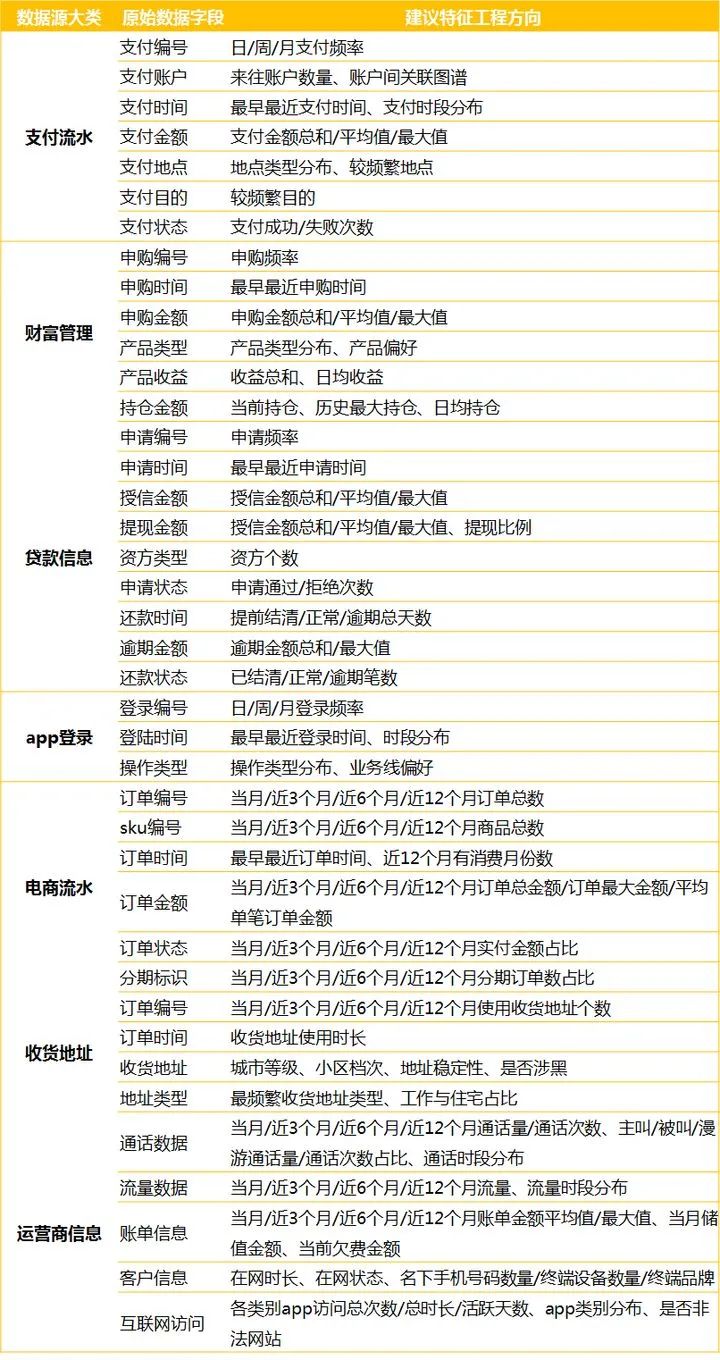
这里引用了知乎JovialCai的回答里的一张图。以风控场景为例,一些可能有用的数据如下(这里其实收集数据源的角度更大一些):
我帮他拍几个很有用的特征
1.支付金额为整数的占比(刻画支付金额是不是都是整数)
2.支付金额分布前10的占比(刻画支付金额是不是集中在几个数里)
3.支付商铺的id占比(刻画支付金额是不是集中在几个店铺里)
4.非运营时段夜间交易行为数量(高危支付行为数量)
其他如图所示(引用了知乎JovialCai):
一些收集的术的资料
很多资料下载需要翻墙,整理的一些能下载下来的,公众号里回复“特征工程”即可获取。
附带链接地址(知乎上不好放外链)
https://www.zhihu.com/question/29316149/answer/607394337

往期精彩回顾 本站qq群955171419,加入微信群请扫码: