
Python自动化办公-编写一个OCR识别程序
OCR 的全称是 Optical Character Recognition,即光学字符识别,通俗点讲就是文字识别。在办公领域,最常用的就是识别图片上的文字,比如识别图片中的发票信息、合同信息、Excel 或者 Word 截图,比如说你对着喜欢的几页书拍了照,想把里面的文字抠出来怎么办?
现在的手机可能都有这个功能,但还不够智能,无法进行训练,再说要是有一堆图片需要处理呢?还是自己动手,丰衣足食,今天来分享一下如何 Python 写一个 OCR 识别程序。授人以渔,本文的思路适用于编写任意一个日常小工具。
第一步,看看已有的轮子
软件开发忌重复造轮子,对普通程序员来讲,也很难造一个好用的轮子,拿来主义真香,万千牛逼的库,虽不是我所有,却为我所用。
浏览器打开 https://github.com,搜索OCR,选择编程语言 Python,可以看到如下结果:
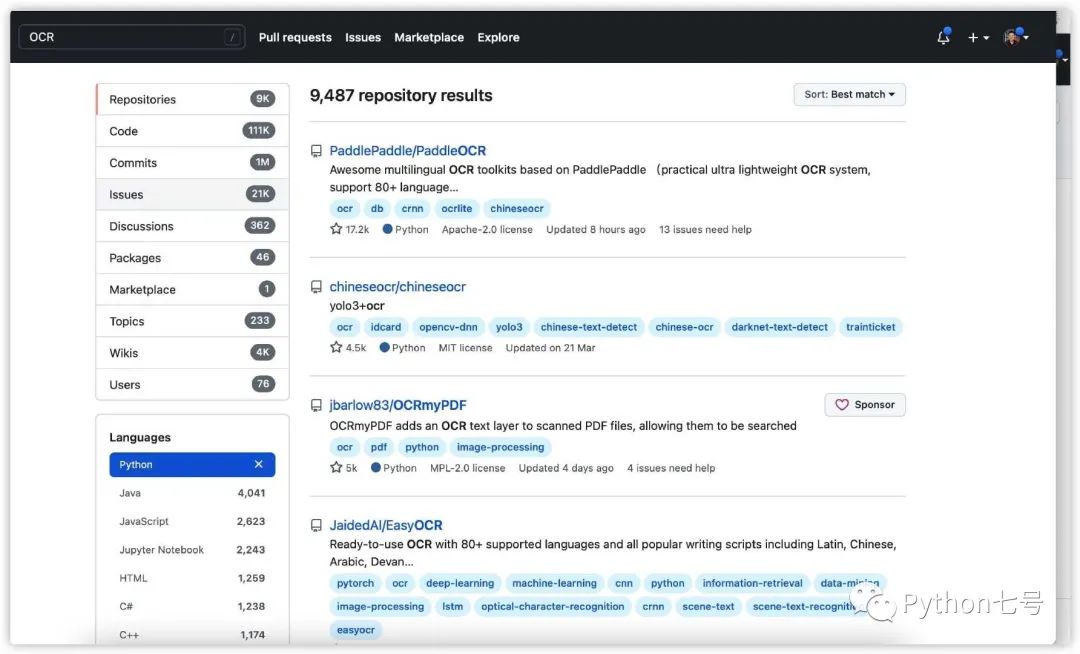
通常情况下,我会选择 star 数量最多的,因为我相信程序员都是在真诚的点赞。
看完轮子的基本介绍,你选择适合自己的就好。
第二步,简单学习下要用的轮子
一般情况下,仓库的 README 上都有安装方法和使用教程,不过大部分都是英文,所以平时多记些英文单词,对于学习技术是很有帮助的。
比如说这个https://github.com/PaddlePaddle/PaddleOCR,很幸运,它是有中文的:
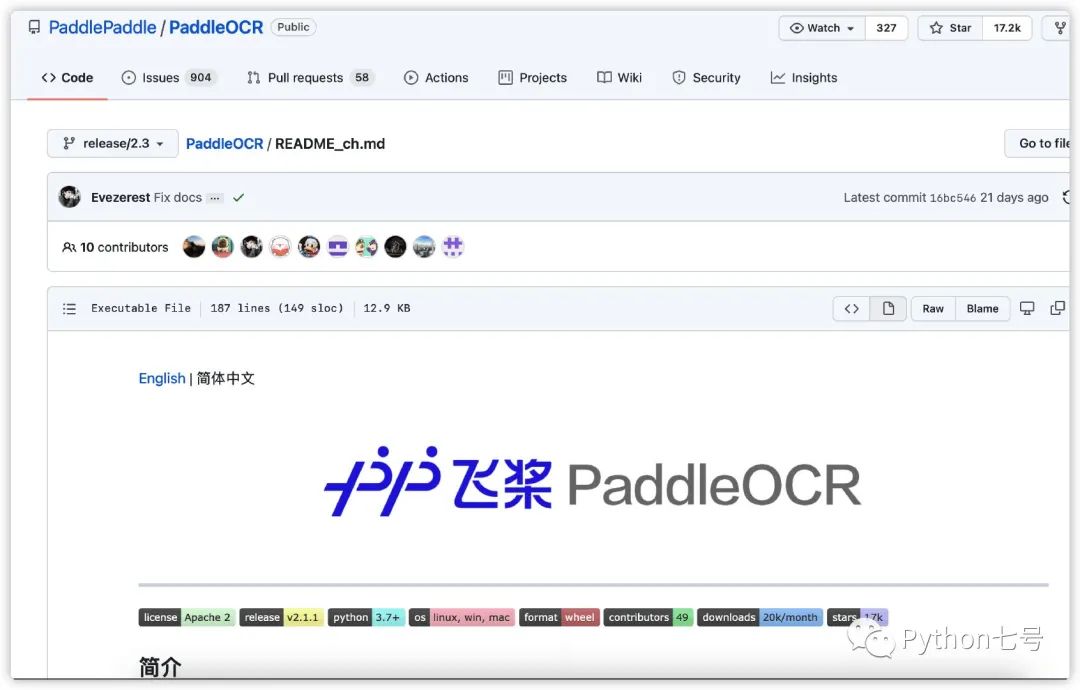

按照这个教程,自己实践一下:
安装
pip install "paddleocr>=2.0.1"
等待 pip 安装完成。
我在 Python 3.8.5 版本上使用 pip 安装顺利通过,而使用 pyenv 的 Python 就一直报编译失败的错误,因此不推荐 pyenv 来管理你的 Python 版本。我的做法是在本机上安装多个 Python 版本,要用哪个版本时启用对应的版本使用如下的命令创建一个虚拟环境:
python3.8 -m venv py38env
python3.9 -m venv py39env
假如要用 Python3.9 那就 source ~/py39env/bin/activate
如果安装过程报错了:
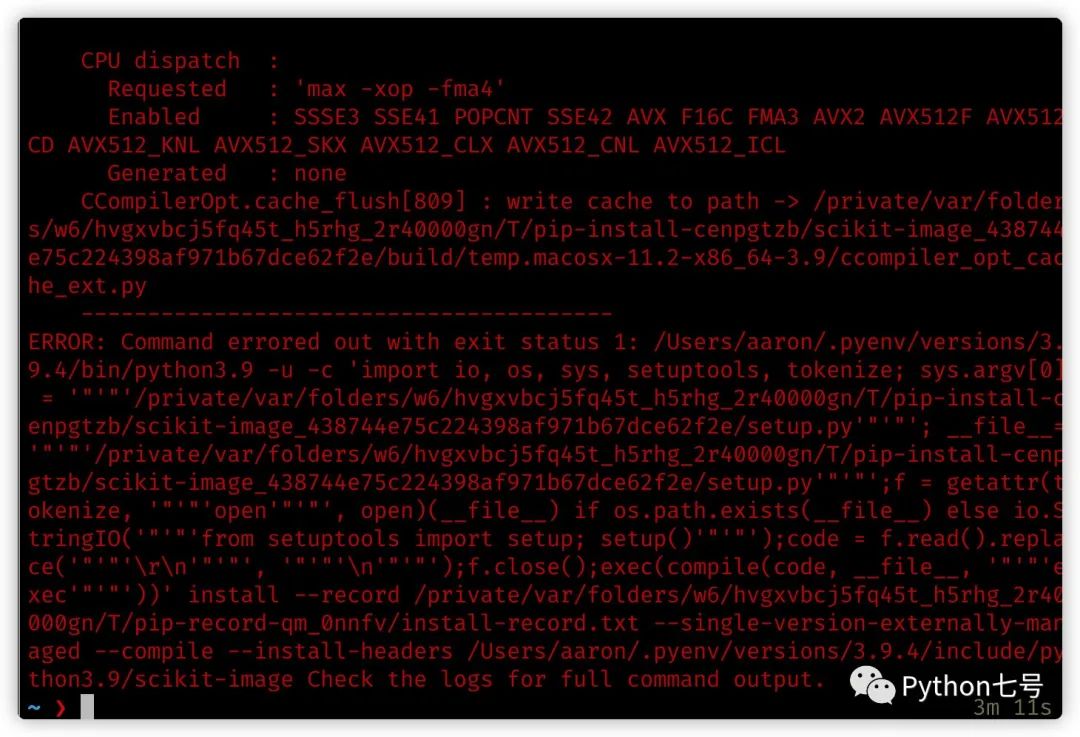
遇到报错,不要慌,只要思想不滑坡,办法总比困难多。
报错信息提示 pip 遇到了编译错误,这也是 Python 为人诟病的地方,第三方库源代码安装时经常遇到编译错误,你看人家 Java,一个 jar 包处处都能用。
毕竟没有完美的语言,理解一下,理解一下。
观察报错前的打印信息,pip 正在安装的是 scikit-image 0.17.2,只要我们找到 scikit-image 的二进制包(别人已经按照对应的平台编译好了),也就是 whl 文件,直接安装一下完事,这个 whl 文件,要去 pypi 上找。浏览器打开 pypi.org,搜索 scikit-image,找到 0.17.2 版本,点开看看,结果如下:
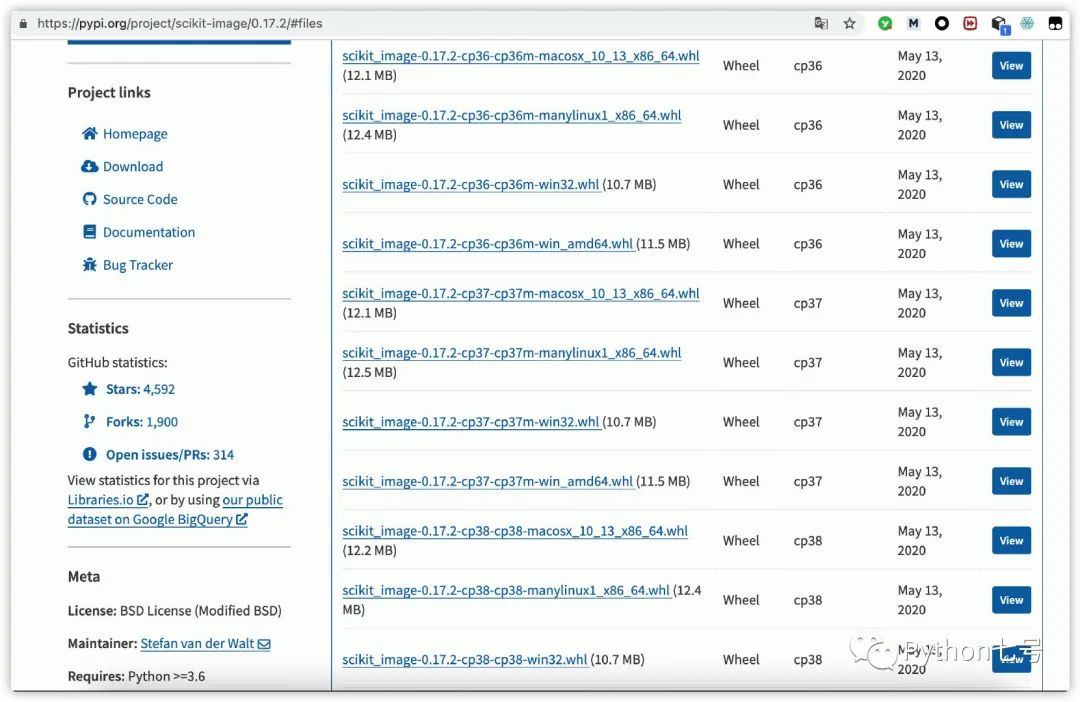
发现 0.17.2 版本最高支持 Python3.8,如果你的 Python 版本是 3.9,劝你降低版本后安装。
选择对应 Python 版本、操作系统进行下载(要是下载慢,请用迅雷下载),然后,pip install 即可。
使用
找个图片试用一下:
1.jpg

paddleocr --image_dir 1.jpg --use_angle_cls true --use_gpu false
结果报了错,提示"ModuleNotFoundError: No module named 'paddle'",在 Issues 里面搜索一下找到了解决方案:
pip install paddlepaddle
然后再次执行识别出结果:
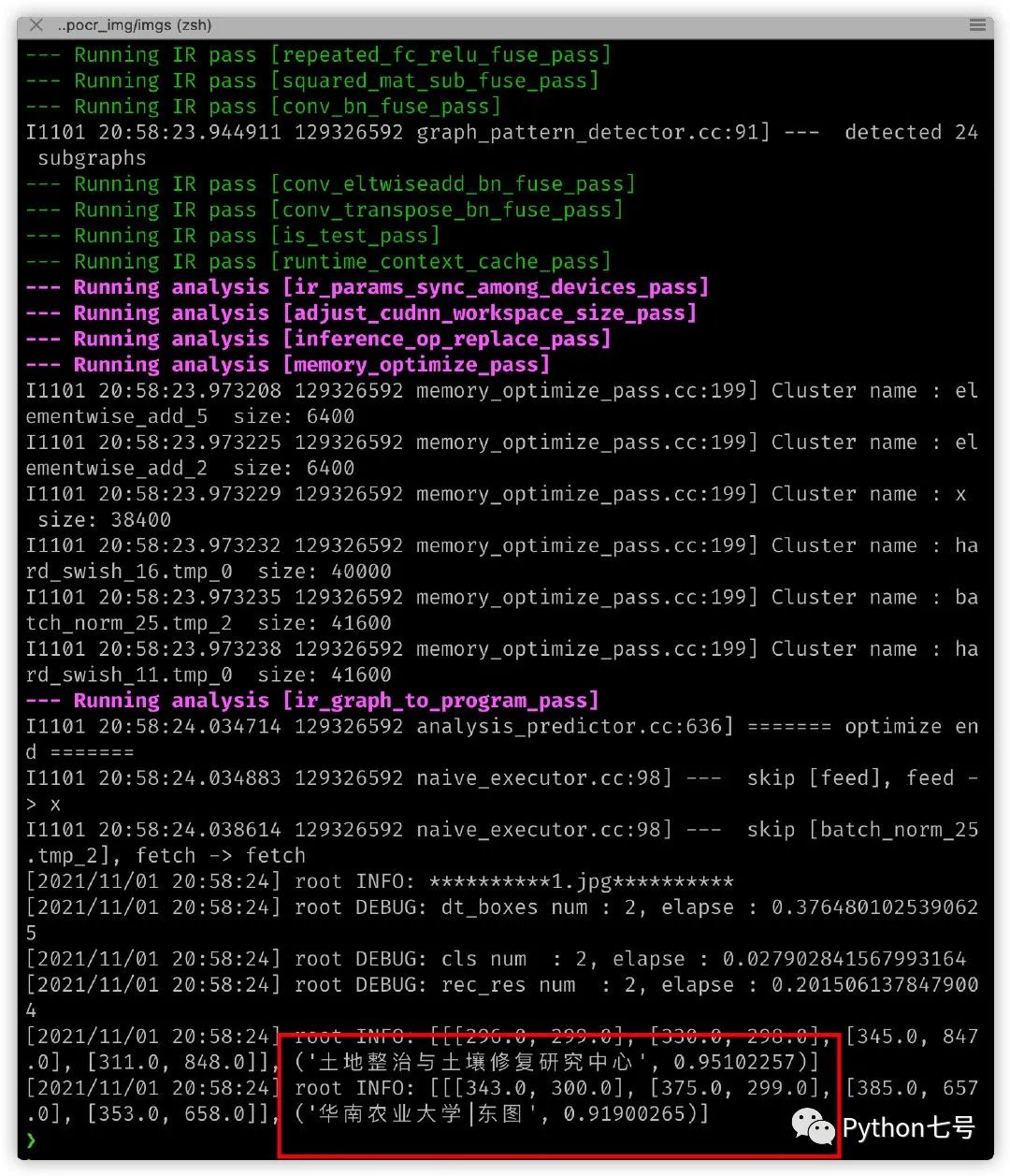
第三步,设计自己的程序。
工具虽然可以直接命令行使用,但结果不是很直观,我们可以写一个脚本,调用下它的接口,将图片路径作为参数输入,将识别出的文本内容作为输出,保存在相同路径下的文本文件中,文件名就是图片名+.txt。
参考官方的示例,可以很轻松写出如下代码:
import sys
from paddleocr import PaddleOCR,draw_ocr
def get_text_to_txt(img_path: str) ->None:
ocr = PaddleOCR(use_angle_cls=True, use_gpu = False, show_log = False, lang='ch') # need to run only once to download and load model into memory
result = ocr.ocr(img_path, cls=True)
with open(img_path+".txt", "w") as writer:
for line in result:
print(line)
writer.write(line[-1][0])
writer.write("\n")
if __name__ == '__main__':
get_text_to_txt(sys.argv[1])
保存为 ocr_demo.py 然后就可以在命令行调用:
❯ python ocr_demo.py /Users/aaron/Downloads/ppocr_img/imgs/1.jpg >> /dev/null
❯ cat /Users/aaron/Downloads/ppocr_img/imgs/1.jpg.txt
土地整治与土壤修复研究中心
华南农业大学|东图
至此脚本搞定。
最后
本文通过使用开源工具 paddleocr,分享了 Python OCR 程序的制作过程,paddleocr 支持 80 多种语言,支持用户自定义训练,还提供丰富的预测推理部署方案,更多技术细节还请参考官方仓库:https://github.com/PaddlePaddle/PaddleOCR
程序报错不可怕,可怕的是你看到错误就放弃了。
如果有帮助,请点赞、在看、关注支持,感谢路上有你。