
再见,Python正则表达式!
点击上方Python知识圈,设为星标
回复100获取100题PDF
阅读文本大概需要 5 分钟
再见,Python正则表达式!今天,我们就尝试用一篇文章,带大家轻松入门Python正则表达式!re库
正则表达式库,也属于Python标准库之一,不用安装就可以使用。什么是正则表达式?
正则表达式是一组由字母和符号组成的特殊文本,可以帮助我们从某个复杂的字符串中,提取出满足我们要求的特殊文本。正则匹配的过程。苹果相当于写的“正则表达式”,字符串相当于“水果市场”,“正则匹配的过程”就相当于拿着苹果去“水果市场”找苹果的过程,每找到一个就返回一个,否则就什么也没有。常用操作符介绍
第一,元字符; 第二,量化符; 第三,特殊符;
1. 常用元字符
“元字符”,指的是那些不仅仅可以表示字符本身含义、并且还可以表示其他特殊含义的字符。. [ ] () ^ $ | \ ? * + { }共11种,为了更清楚地说明每个元字符的含义,我这里整理了一张表格供大家参考。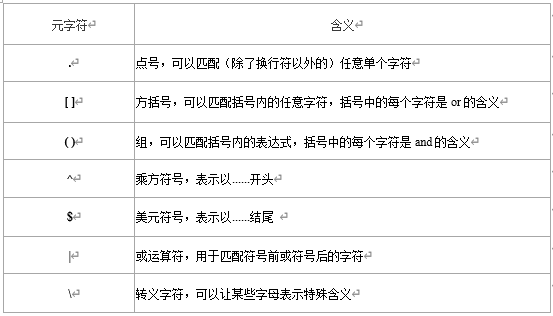
2. 常用量化符
“量化符”,指的就是将紧挨着量化符前面的那个字符,匹配0次、1次或者多次,详细说明见下表。
3. 常用特殊符
所谓“特殊符”,指的就是由转义字符加某些字母组合而成的具有特殊意义的特殊字符,详细说明见下表。
常用方法介绍
match()、search()还有findall(),下面我们分别对他们进行讲述。1. 三大函数含义对比
match(pattern,string):匹配字符串的开头,如果开头匹配不上,则返回None; seach(pattern,string):扫描整个字符串,匹配后立即返回,不在往后面匹配; findll(pattern,string):扫描整个字符串,以列表形式返回所有的匹配值;
2. 三大函数用法对比
import re
s = "黄同学喜欢唱歌,黄同学喜欢写作,黄同学喜欢吃火锅!"
s1 = "喜欢唱歌,喜欢写作,喜欢吃火锅"
① 使用match()函数
re.match("喜欢",s)
re.match("喜欢",s) == None
re.match("喜欢",s1)
re.match("喜欢",s1).group()
② 使用search()函数
re.search("喜欢",s)
re.search("喜欢",s).group()
③ 使用finall()函数
re.findall("喜欢",s)
3. 其他常用方法
split(pattern,string):按照某个匹配的正则表达式,将整个字符串切分后,以列表返回; sub(pattern,repl,string):按照某个匹配的正则表达式,将整个字符串的某个字串替换为另外一个字串; re.I:让正则表达式自动忽略大小写; re.S:让“.”能够匹配包括换行符在内的任意字符;
s = "赵1钱2孙4李8周16吴32郑64王128黄"
s1 = "Huang是huang"
s2 = "黄\n同学"
需求1:将字符串s按照数字切分,以一个汉字组成的列表返回。
re.split("\d+",s)
需求2:将字符串s中的数字部分,全都替换为空。
re.sub("\d+"," ",s)
需求3:将字符串s1中的h匹配出来,不区分大小写;
re.findall("h",s1)
re.findall("h",s1,re.I)
需求4:将字符串s2整个匹配出来,包括换行符;
re.findall(".+",s2)
re.findall(".+",s2,re.S)
往期推荐 01 02 03
我就知道你“在看” 
评论