
RocketMQ调优心得总结
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
一、问题
线上RocketMQ 集群,偶尔报错如下:
(1)[REJECTREQUEST]system busy, start flow control for a while
(2)[TIMEOUT_CLEAN_QUEUE]broker busy, start flow control for a while, period in queue: 206ms, size of queue: 5二、调优历程
Google资料
翻阅github 和 stackoverflow,在stackoverflow 上找到该问题:https://stackoverflow.com/questions/47749906/rocketmq-throw-exception-timeout-clean-queuebroker-busy-start-flow-control-f
按照以上方式增加配置文件参数:
sendMessageThreadPoolNums=64
useReentrantLockWhenPutMessage=true 之后重启观察,报错确实变少了,但量大了后,还有报错。期间对sendMessageThreadPoolNums参数做过多次调整,32 、64、128 都试过,发现在 4核CPU, 30G内存的机器上,配置sendMessageThreadPoolNums超过64 反倒表现的更不好。本人最后选择sendMessageThreadPoolNums=32。具体多少合适,最好通过压测评估。
撸源码
此时还会报 broker busy,实在没办法,只能看源码,尤其对报错前后相关代码多次阅读,基本了解了报错原因。
两个报错的代码如下:

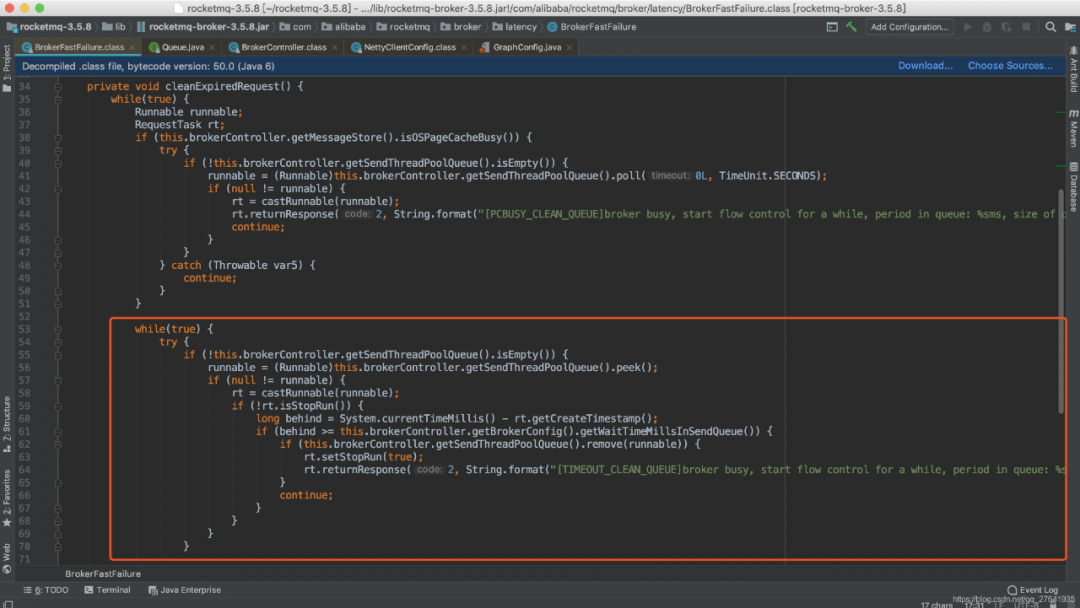
通过阅读源码,得出结果:mq busy是因为线程等待时间,超过了waitTimeMillsInSendQueue的值,该值默认 200ms。
所以还需分析,到底是什么原因,导致线程在等待,并超过了200ms,有两种可能:
1. mq消息消费速度慢,消息堆积,导致消息写入内存变慢,超过了200ms
2. GC时JVM STW(stop the world) ,导致超时
之后对 JVM 进行了调优,选用 G1回收器,并且观察 gc 时间,full GC 基本没有了,新生代gc 时间控制在50ms 之内,而且频率不高。
JVM 优化后,还是偶尔有 broker busy.
配置优化
查看rocketmq 日志,存储层日志store.log:
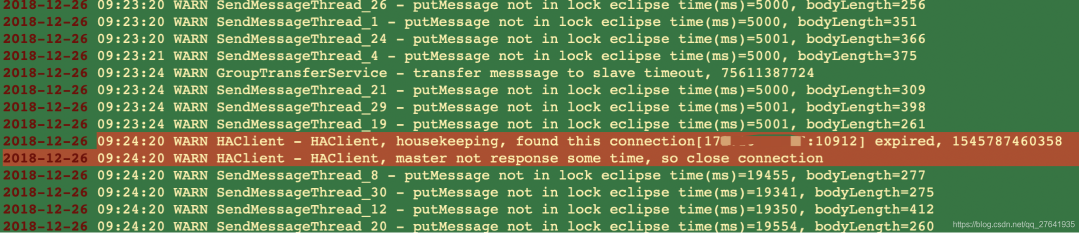
可以看出,在消息发送时,主从同步时,连接从服务器等待超时,自动断了连接。
如果是同步双写模式,master会等待slave也写成功才会给客户端返回成功。这个也会耗时,性能不好,建议使用异步。
优化建议:主从同步使用异步,配置brokerRole=ASYNC_MASTER。
到此,优化配置:
#主从同步模式
brokerRole=ASYNC_MASTER
#消息发送队列等待时间,默认200
waitTimeMillsInSendQueue=400
#发送消息的最大线程数,默认1,因为服务器配置不同,具体多少需要压测后取最优值
sendMessageThreadPoolNums=32
#发送消息是否使用可重入锁(4.1版本以上才有)
useReentrantLockWhenPutMessage=true到此,MQ 基本稳定,连续几个月再没有报错。
后来MQ集群内存快不够了,扩了集群,扩为之前2倍节点。
扩容后过段时间,又出现了 以上两个错, broker busy 报错居多。。。
此时第一感觉是新增的机器问题,通过Falcon监控,观察分析后,发现报错期间,CPU、内存、IO 等都无异常,有部分报错时间点 swap 波动较大。
当内存不够用时,rocketMQ 会使用交换区,使用交换区性能较差,这里就不对swap做过多解释了。
对Linux内核参数调优:
查看 cat /proc/sys/vm/swappiness
设置 swappiness = 1减少使用交换区,提升性能。
优化该参数后,报错减少。
后来上线异步消息,并发增高,随着使用方量级增长,broker busy 还是会出现。
在和 system busy 和 broker busy 的斗争中,我对RocketMQ的了解也在加深。
对于RocketMQ 集群,和其他使用者也有过交流,总之经验是:多个小集群 优于 一个大集群。
调优时,多关注磁盘IO 和 内存使用情况及释放时间点,重点关注以下指标:
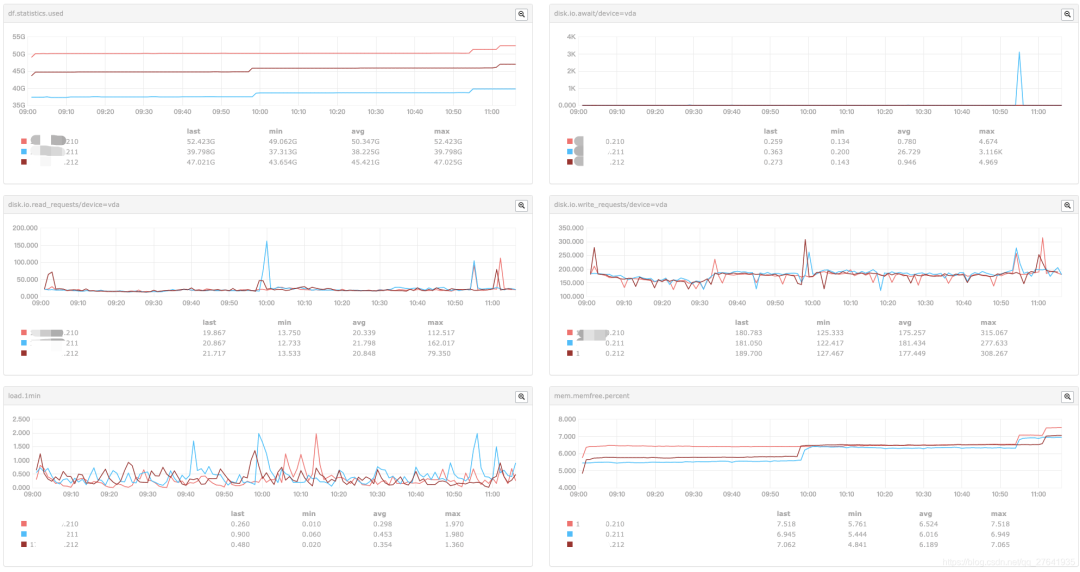
三、最终的参数调优方案
机器配置参考:CPU 4核 \ 内存30G
RocketMQ 的配置
#主从异步复制
brokerRole=ASYNC_MASTER
#异步刷盘
flushDiskType=ASYNC_FLUSH
#线上关闭自动创建topic
autoCreateTopicEnable=false
#发送消息的最大线程数,默认1
sendMessageThreadPoolNums=32
#使用可重入锁
useReentrantLockWhenPutMessage=true
#发送消息线程等待时间,默认200ms
waitTimeMillsInSendQueue=1000
#开启临时存储池
transientStorePoolEnable=true
#开启Slave读权限(分担master 压力)
slaveReadEnable=true
#关闭堆内存数据传输
transferMsgByHeap=false
#开启文件预热
warmMapedFileEnable=trueJVM
-server -Xms10g -Xmx10g
-XX:+UseG1GC -XX:MaxGCPauseMillis=80 -XX:G1HeapRegionSize=16m
-XX:G1ReservePercent=25 -XX:InitiatingHeapOccupancyPercent=30
-XX:SoftRefLRUPolicyMSPerMB=0 -XX:SurvivorRatio=8
-verbose:gc -Xloggc:/dev/shm/mq_gc_%p.log -XX:+PrintGCDetails
-XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=30m
-XX:-OmitStackTraceInFastThrow -XX:+AlwaysPreTouch -XX:MaxDirectMemorySize=15g
-XX:-UseLargePages -XX:-UseBiasedLocking -XX:+PrintGCApplicationStoppedTime
-XX:+PrintSafepointStatistics -XX:PrintSafepointStatisticsCount=1
-XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCDateStamps
-XX:+PrintAdaptiveSizePolicyLinux
vm.extra_free_kbytes,告诉VM在后台回收(kswapd)启动的阈值与直接回收(通过分配进程)的阈值之间保留额外的可用内存。RocketMQ使用此参数来避免内存分配中的长延迟。(与具体内核版本相关)
vm.min_free_kbytes,如果将其设置为低于1024KB,将会巧妙的将系统破坏,并且系统在高负载下容易出现死锁。
vm.max_map_count,限制一个进程可能具有的最大内存映射区域数。RocketMQ将使用mmap加载CommitLog和ConsumeQueue,因此建议将为此参数设置较大的值。(agressiveness --> aggressiveness)
vm.swappiness,定义内核交换内存页面的积极程度。较高的值会增加攻击性,较低的值会减少交换量。建议将值设置为10来避免交换延迟。
File descriptor limits,RocketMQ需要为文件(CommitLog和ConsumeQueue)和网络连接打开文件描述符。我们建议设置文件描述符的值为655350。
Disk scheduler,RocketMQ建议使用I/O截止时间调度器,它试图为请求提供有保证的延迟。
1. 减少使用交换区
swappiness = 12. Disk scheduler使用DeadLine IO调度器
查看IO调度器:
#查看机器整体
dmesg | grep -i scheduler
#查看某个磁盘的调度器
cat /sys/block/vda/queue/scheduler修改IO调度器:
echo deadline > /sys/block/vda/queue/scheduler注意:Linux version 3.10 以上的版本,会出现修改不成功。
如下:
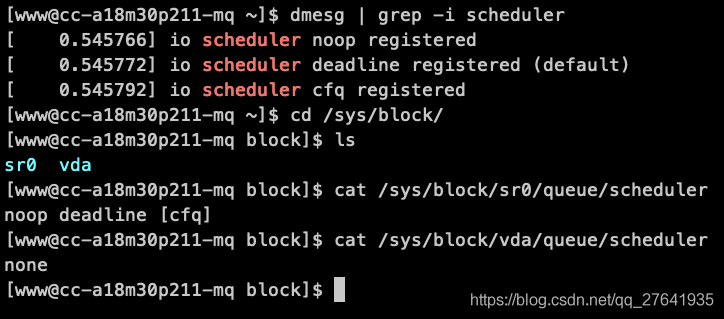
如果你的Linux 服务器,查看磁盘IO调度器发现是 none, none 意思是不使用 IO调度器,一般都是开启了 blk-mq, 查看/sys/block/vda/ 下,如果有mq目录,说明使用的是blk-mq机制。
Blk-mq
Linux 3.13引入了块层的新框架 blk-mq(多队列块IO排队机制),并且在3.16内核中已具有完整的功能。Blk-mq 通过8插槽服务器上的高性能闪存设备(例如PCIe SSD)允许超过1500万IOPS。
Blk-mq无缝集成到Linux存储堆栈中。它为设备驱动程序提供了基本功能,用于将I / O查询映射到多个队列。任务分布在多个线程中,因此分布到多个CPU内核(每个内核软件队列)。兼容Blk-mq的驱动程序通知blk-mq设备支持多少个并行硬件队列(作为硬件调度队列注册的一部分的提交队列的数量)。基于Blk-mq的设备驱动程序会绕过以前的Linux I / O调度程序。根据Linux I / O调度程序(基于request_fn的方法,请参阅Linux I / O堆栈图),使用前一个块I / O层的所有设备驱动程序将继续独立于blk-mq用作基于请求的驱动程序。
所以,如果你的MQ服务器硬盘是SSD 或者 内核为 3.10以上的,理论上使用blk-mq性能将会更高,不需要修改。
Netty
相关配置参数
1. jvm参数加:-Dio.netty.recycler.maxCapacity.default=0
2. jvm参数去掉-XX:+DisableExplicitGC
Netty性能问题
1.查阅netty相关资料,在netty的github上找到了一个issue #4147,大致可以看出,netty实现的Recycler并不保证池的大小,也就是说有多少对象就往池中加入多少对象,从而可能撑满服务器。通过在jvm启动时加入-Dio.netty.recycler.maxCapacity.default=0参数来关闭Recycler池,前提:netty version>=4.0。所以可怀疑为内存泄露!
千万不要开启-XX:+DisableExplicitGC!因为netty要做System.gc()操作,而System.gc()会对直接内存进行一次标记回收,如果通过DisableExplicitGC禁用了,会导致netty产生的对象爆满
2.Netty里四种主力的ByteBuf,
其中UnpooledHeapByteBuf 底下的byte[]能够依赖JVM GC自然回收;而UnpooledDirectByteBuf底下是DirectByteBuffer,如Java堆外内存扫盲贴所述,除了等JVM GC,最好也能主动进行回收;而PooledHeapByteBuf 和 PooledDirectByteBuf,则必须要主动将用完的byte[]/ByteBuffer放回池里,否则内存就要爆掉。所以,Netty ByteBuf需要在JVM的GC机制之外,有自己的引用计数器和回收过程。
在DirectByteBuffer中,首先向Bits类申请额度,Bits类有一个全局的 totalCapacity变量,记录着全部DirectByteBuffer的总大小,每次申请,都先看看是否超限 -- 堆外内存的限额默认与堆内内存(由-XMX 设定)相仿,可用 -XX:MaxDirectMemorySize 重新设定。
如果已经超限,会主动执行Sytem.gc(),期待能主动回收一点堆外内存。然后休眠一百毫秒,看看totalCapacity降下来没有,如果内存还是不足,就抛出大家最头痛的OOM异常。
心得:
MQ 调优过程,需要关注 disk 、mem 、IO、CPU 等方面指标,尤其要关注 iowait , 磁盘iowait 会直接影响性能。
发送消息线程数并不是越多越好,太多的线程,CPU 上下文切换也是很大的性能损耗。
需要对Linux 有较为深刻的了解,其中涉及 页缓存、缺页中断、零拷贝、预读、回写、内存映射、IO调度器。
其他技术:并发处理、锁机制、异步、池化技术、堆外内存、Netty 等相关技术。
只有对以上这些技术都有深刻理解,才能很好的理解RocketMQ,并对其做出合理的优化。
————————————————
版权声明:本文为CSDN博主「CleverApe」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:
https://blog.csdn.net/qq_27641935/article/details/106015319
锋哥最新SpringCloud分布式电商秒杀课程发布
👇👇👇
👆长按上方微信二维码 2 秒
感谢点赞支持下哈 