
自动化机器学习入门指南,来了
从Google Cloud绘制的AutoML的工作原理图可以看出,我们使用者只需要给其提供数据源,以及好坏样本(或者不需要),然后后面的一切都交给AutoML组件去完成。
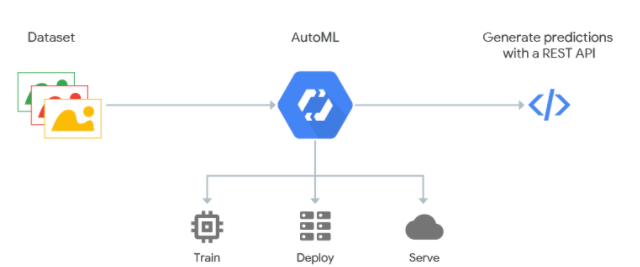
? AutoML的关键节点
我们可以认识到AutoML大大降低了机器学习模型的开发门槛,但是我们还是需要了解这里面的原理的,这里涉及了机器学习的几个关键节点的内容,需要我们特别关注。
其中最为重要的是自动化特征工程了,一般缩写为“Auto FE”,主要是包括了预处理、特征选择、特征提取、元学习等等的操作,把每一个环节的处理逻辑写到脚本里,结合一些策略让逻辑更加科学,结果更加合理。
第二个就是自动化模型选择,也叫Automated Model Selection,简称AMS,就是根据实际的数据来选择合适的算法。因为大多数的算法都是有超参数的,这时候AutoML是需要进行自动化的超参数优化的,英文叫做Hyperparameter Optimization,简称HPO,在学习中了解到这块的知识研究还是蛮丰富的,主要有下面的一些方法:
基于贝叶斯优化的超参数优化 Bayesian Optimization 基于进化算法的超参数优化 Evolutionary Algorithms 基于本地搜索的超参数优化 Local Search 基于随机搜索的超参数优化 Random Search 基于粒子群优化算法的超参数优化 Particle Swarm Optimization 基于元学习的超参数优化 Meta Learning 基于迁移学习的超参数优化 Transfer Learning
还有一个概念就是NAS,即Neural Architecture Search(神经网络结构搜索),因为目前深度学习应用很广泛了,很多时候是需要搭建一个深度神经网络,这里面涉及的参数是真的多,按照传统的超参数优化的方法显得十分吃力,所以也有了这个NAS的概念,而关于NAS的研究方法,主要有下面几种:
基于进化算法的超参数优化 Evolutionary Algorithms 基于元学习的超参数优化 Meta Learning 基于迁移学习的超参数优化 Transfer Learning 基于本地搜索的超参数优化 Local Search 基于强化学习的超参数优化 Reinforcement Learning 基于Network Morphism 基于 Continuous Optimization优化
? 市面上的AutoML产品
目前AutoML工具我们可以从两个途径来进行获取学习:
开源框架:如Auto-Keras、Auto-sklearn等开源工具 商业服务:如Google Cloud、Microsoft Azure等
从Awesome-AutoML-Papers(https://github.com/hibayesian/awesome-automl-papers#projects)里有一张AutoML工具的对比图,大家可以浏览一波。
| 名称 | 支持类型 | 编程语言 |
|---|---|---|
| AdaNet | NAS | Python |
| Advisor | HPO | Python |
| AMLA | HPO, NAS | Python |
| ATM | HPO | Python |
| Auger | HPO | Python |
| Auto-Keras | NAS | Python |
| AutoML Vision | NAS | Python |
| AutoML Video Intelligence | Python | |
| AutoML Natural Language | NAS | Python |
| AutoML Translation | NAS | Python |
| AutoML Tables | AutoFE, HPO | Python |
| auto-sklearn | HPO | Python |
| auto_ml | HPO | Python |
| BayesianOptimization | HPO | Python |
| BayesOpt | HPO | C++ |
| comet | HPO | Python |
| DataRobot | HPO | Python |
| DEvol | NAS | Python |
| Driverless AI | AutoFE | Python |
| FAR-HO | HPO | Python |
| H2O AutoML | HPO | Python, R, Java, Scala |
| HpBandSter | HPO | Python |
| HyperBand | HPO | Python |
| Hyperopt | HPO | Python |
| Hyperopt-sklearn | HPO | Python |
| Hyperparameter Hunter | HPO | Python |
| Katib | HPO | Python |
| MateLabs | HPO | Python |
| Milano | HPO | Python |
| MLJAR | HPO | Python |
| nasbot | NAS | Python |
| neptune | HPO | Python |
| NNI | HPO, NAS | Python |
| Optunity | HPO | Python |
| R2.ai | HPO | ------ |
| RBFOpt | HPO | Python |
| RoBO | HPO | Python |
| Scikit-Optimize | HPO | Python |
| SigOpt | HPO | Python |
| SMAC3 | HPO | Python |
| TPOT | AutoFE, HPO | Python |
| TransmogrifAI | HPO | Scala |
| Tune | HPO | Python |
| Xcessiv | HPO | Python |
| SmartML | HPO | R |
? AutoML学习框架——auto-sklearn介绍与入门
这里会简单地讲一下auto-sklearn的框架,让大家对这个学习框架有一定的了解,接下来就会拿官方的栗子来说明一下怎么使用,然后罗列一下这个auto-sklearn可以做什么内容,让大家对这个框架的功能有一定的了解。
二话不说,先在本地安装一下这个包,直接pip install auto-sklearn走起,如果安装失败可能是因为缺少依赖项,可以试试:
curl https://raw.githubusercontent.com/automl/auto-sklearn/master/requirements.txt | xargs -n 1 -L 1 pip install
如果出现Failed to connect to raw.githubusercontent.com port 443: Connection refused的报错,初步估计是DNS污染,可以查看相关攻略:https://github.com/hawtim/blog/issues/10
如果安装失败,可以按照官网网站的指导再试试:https://automl.github.io/auto-sklearn/master/installation.html
相关学习传送门:
auto-sklearn官方文档(https://automl.github.io/auto-sklearn/master/api.html) auto-sklearn官方示例(https://automl.github.io/auto-sklearn/master/examples/index.html)
我们从上面官方文档可以知道(可能需要番羽Q,所以我就把相关的example的code下载下来了,大家可以后台回复“automl”获取),auto-sklearn的功能主要有下面的截图所示,包括分类模型、回归模型的构建,模型评估方法的支持等,涵盖了我们主要的基础建模需求。
auto-sklearn顾名思义应该是和我们常用的scikit-learn有一定的关系,确实对的,auto-sklearn就是基于scikit-learn进行开发的自动化机器学习库,所以如果我们熟悉scikit-learn的使用,那么对于这个auto-sklearn就很好理解了的,不熟悉其实也没有关系,也蛮简单的,后续我拿一些小栗子来说明一下,主要围绕两个核心的分类接口和回归接口API:AutoSklearnClassifier 和 AutoSklearnRegressor 。
? AutoSklearnClassifier(分类)
我们直接在官方文档里看下这个API的参数,如下图所示:

参数的数量还是蛮多的,我们简单介绍两个Parameters:
time_left_for_this_task:int类型,默认3600秒 时间限制是针对模型参数搜索的,我们可以通过加大这个值来增加模型训练的时间,有更大的机会找到更好的模型。 per_run_time_limit:int类型, 默认值为参数time_left_for_this_task值的1/10 这个时间限制是针对每次模型调用的,如果模型调用时间超出这个值,则会被直接终止拟合,可以适当加大这个值。
简单调用一下:
# 导入相关包
import numpy as np
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
import warnings
from autosklearn.classification import AutoSklearnClassifier
warnings.filterwarnings('ignore') # 忽略代码警告
# 导入手写数字的数据集
digits = load_digits() # 加载数据集
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
digits.data, digits.target, test_size=0.3, random_state=42) # 切分数据集
# 调用Auto-sklearn
# 限制算法搜索最大时间,更快得到结果
auto_model = AutoSklearnClassifier(
time_left_for_this_task=120, per_run_time_limit=10)
# 训练模型
auto_model.fit(X_train, y_train)
# 用测试集评估模型效果
auto_model.score(X_test, y_test)
? AutoSklearnRegressor(回归)
我们继续看官方文档里的API参数,如下图所示:

参数也是照样很多,
time_left_for_this_task:int类型,和上面的分类API是一样的参数 per_run_time_limit:int类型,和上面的分类API是一样的参数 ensemble_size:int类型,默认是50 从算法中选择构建为集成模型的数量
总结来说这两个API的参数几乎是一样的,正所谓一份学习double享受,jeng!同样的我们简单地调用一下,这次我们用房价预测的数据集,这是一个很经典的回归算法的数据集。
# 导入相关包
from sklearn.datasets import load_boston
from autosklearn.regression import AutoSklearnRegressor
# 导入数据集
boston = load_boston() # 加载数据集
# 限制算法搜索最大时间,更快得到结果
auto_model = AutoSklearnRegressor(
time_left_for_this_task=120, per_run_time_limit=10)
auto_model.fit(boston.data, boston.target)
# 查看模型效果,用R方来看
auto_model.score(boston.data, boston.target)
? Auto-sklearn支持的Metrics方法
我们评估一个机器学习模型的好坏需要量化的指标,而我们常用的几个像准确率、AUC、ROC、f1等等,在这里是否也支持呢?我们可以看看:
print("Available CLASSIFICATION metrics autosklearn.metrics.*:")
print("\t*" + "\n\t*".join(autosklearn.metrics.CLASSIFICATION_METRICS))
print("Available REGRESSION autosklearn.metrics.*:")
print("\t*" + "\n\t*".join(autosklearn.metrics.REGRESSION_METRICS))
Available CLASSIFICATION metrics autosklearn.metrics.*:
*accuracy
*balanced_accuracy
*roc_auc
*average_precision
*log_loss
*precision
*precision_macro
*precision_micro
*precision_samples
*precision_weighted
*recall
*recall_macro
*recall_micro
*recall_samples
*recall_weighted
*f1
*f1_macro
*f1_micro
*f1_samples
*f1_weighted
Available REGRESSION autosklearn.metrics.*:
*r2
*mean_squared_error
*mean_absolute_error
*median_absolute_error
我们可以看出其实大多数的评估指标都涵盖了,具体怎么用,建议可以去看看官方文档看看例子~
? AutoDL学习框架——auto-keras介绍与入门
介绍完了机器学习框架的原理以及其中一个产品的简单使用,顺便也介绍下深度学习的自动化机器学习框架,深度学习在近几年十分大热,神经网络在很多时候的表现也是让人吃惊,确实也很有必要去了解一下。
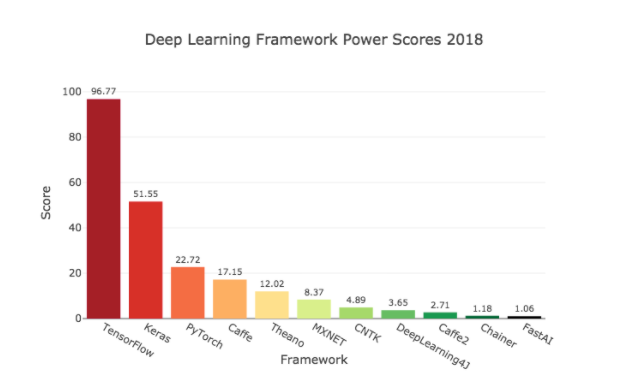
towardsdatascience.com
可以从上图看出目前最流行的深度学习框架有TensorFlow、Keras和PyTorch,今天我们不展开这些框架的学习,篇幅有限也不好展开(主要是我也不熟哈哈哈),我们今天就来讲讲Auto-Keras的简单使用,毕竟今天的主要还是自动化机器学习。

Auto-Keras框架是由DATA Lab开发的,由Keras官方团队维护。它主要提供了神经结构搜索(NAS)和超参数自动优化(HPO),其后端依赖于scikit-learn、TensorFlow和PyTorch,我们还是把一些常用的地址贴一下:
官方网站:https://autokeras.com/ GitHub地址:https://github.com/keras-team/autokeras
安装的话也是比较简单,可以使用pip的方式进行安装,不过目前AutoKeras只支持Python >= 3.5 and TensorFlow >= 2.3.0:
pip3 install git+https://github.com/keras-team/keras-tuner.git@1.0.2rc1
pip3 install autokeras
我们从官网文档里可以看出主要是支持图片分类、图片生成、文本分类、文本生成等,算是涵盖了计算机视觉和自然语言处理的常用应用场景了。
import sys
sys.path.append("autokeras") # 链接到 Auto-Keras 库
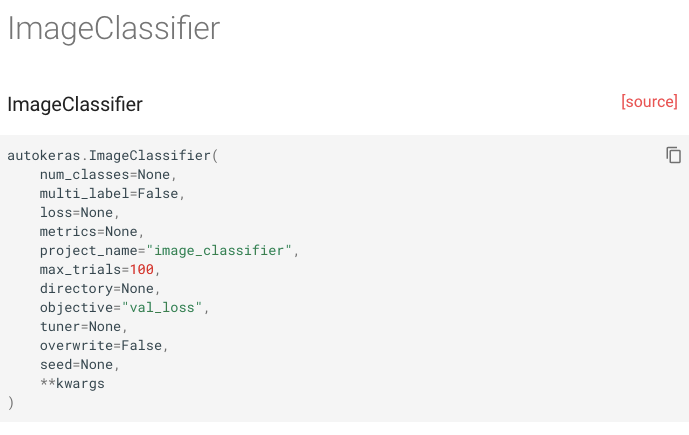
? ImageClassifier(图片分类)
同样的,我们可以看看官方文档:
调用栗子:
我们导入自带的MNIST手写字符分类数据集,样本数据形状为28x28的灰度图像,已经转为了numpy数组。
# 导入相关包
import tensorflow as tf
from autokeras.image.image_supervised import ImageClassifier
# 加载数据集
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
# 实例化模型,verbose=True 输出训练过程参数
clf = ImageClassifier(verbose=True)
# 训练模型,最大时间设为 30 分钟
clf.fit(X_train, y_train, time_limit=30 * 60)
# 评估模型
clf.evaluate(X_test, y_test)
那如果是针对那些数据集本身是图片的呢,又可以如何操作?也可以参考下面的例子:
# 下载图片数据
!wget -nc "https://labfile.oss.aliyuncs.com/courses/1357/load_raw_image_data.zip"
!unzip -o "load_raw_image_data.zip" # 解压数据
# 导入相关包
import pandas as pd
from autokeras.image.image_supervised import load_image_dataset
# 读取数据
X_train, y_train = load_image_dataset(
="load_raw_image/train/label.csv", images_path="load_raw_image/train")
X_test, y_test = load_image_dataset(
csv_file_path="load_raw_image/test/label.csv", images_path="load_raw_image/test")
# 实例化模型,verbose=True 输出训练过程参数
clf = ImageClassifier(verbose=True)
# 训练模型,最大时间设为 30 分钟
clf.fit(X_train, y_train, time_limit=30 * 60)
# 评估模型
clf.evaluate(X_test, y_test)
? TextClassifier(文本分类)
同样的,我们可以看看官方文档:

NLP有十分丰富的应用,比如文本分类、情感分析、机器翻译、智能问答等,在Auto-Keras中也有类似的APIs可以用,我们拿其中一个文本分类预测来看看。
# 下载数据集(关于电影影评的积极与消极情绪的识别)
!wget -nc "https://labfile.oss.aliyuncs.com/courses/1357/imdb-reviews.zip"
!unzip -o "imdb-reviews.zip"
# 导入相关包
import pandas as pd
from sklearn.model_selection import train_test_split
from autokeras.text.text_supervised import TextClassifier
# 导入数据
reviews = pd.read_csv("imdb-reviews.csv")
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(
reviews['text'], reviews['sentiment'], test_size=0.1)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
# 独热编码,因为auto-kearn要求输入的为独热编码后的数组
y_train_ = pd.get_dummies(y_train).values
y_test_ = pd.get_dummies(y_test).values
# 实例化模型,verbose=True 输出训练过程参数
clf = TextClassifier(verbose=True)
clf.fit(X_train, y_train, time_limit=30 * 60)
# 评估模型
clf.evaluate(X_test, y_test)
(我把相关的example的code下载下来了,大家可以后台回复“automl”获取)
? References
自动化机器学习综述——实验楼 Awesome-AutoML-Papers(https://github.com/hibayesian/awesome-automl-papers) auto-sklearn官方文档(https://automl.github.io/auto-sklearn/master/api.html) auto-sklearn官方示例(https://automl.github.io/auto-sklearn/master/examples/index.html) 解决DNS污染的问题(https://github.com/hawtim/blog/issues/10)