
Transformer | 没有Attention的Transformer依然是顶流!!!
共 8357字,需浏览 17分钟
·
2021-06-06 13:42


本文主要介绍了Attention Free Transformer(AFT),同时作者还引入了AFT-local和AFT-Conv,这两个模型在保持全局连通性的同时,利用了局域性和空间权重共享的思想。通过实验验证了AFT在所有benchmarks上具有竞争性能的同时具有出色的效率。
1简介
本文主要介绍了Attention Free Transformer(AFT),在AFT层中,首先将key和value与一组学习到的位置偏差结合起来,然后以元素方式将其结果与query相乘。这个新的操作在context size和特征维度上都具有线性的内存复杂度,使得它能够兼容大的输入和模型大小。
作者还引入了AFT-local和AFT-Conv,这两个模型变种在保持全局连通性的同时还利用了局域性和空间权重共享的思想。作者对2个自回归建模任务(CIFAR10和Enwik8)以及一个图像识别任务(ImageNet-1K分类)进行了广泛的实验。验证了AFT在所有benchmarks上不仅具有不错的性能,同时还具有出色的效率。
2本文方法
2.1 Attention Free Transformer
首先,定义了Attention Free Transformer(AFT),它是MHA的plugin replacement,不需要改变Transformer的其他架构。给定输入X, AFT先将它们线性变换为 , , ,然后执行以下操作:
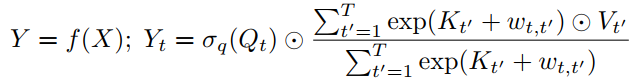
其中, 是元素的乘积; 是应用于query的非线性映射,默认为sigmoid; 是学习到成对的位置偏差。

换句话说,对于每个目标位置 , AFT把加权平均的结果与具有元素级乘法的query相结合。而加权操作则是由key和一组学习成对的位置偏差组成。这提供了一个直接的优势,即不需要计算和存储消耗大的注意力矩阵,同时能够像MHA那样维护query和value之间的全局交互。
为了进一步了解AFT与MHA的关系可以将方程改写为:
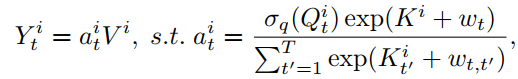
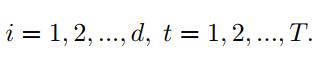
这里使用上标 来索引矩阵的特征维数。在这种重新排列的形式中,能够再次用注意力来表达AFT。具体来说,对于每个位置有一个关注向量 ,每个维度由 组成。换句话说,AFT可以解释为与特征尺寸一样多的Head中进行implicit attention,其中注意力矩阵采用因数分解的形式进行求解。
2.2 AFT variants: locality, weight sharing and parameterization
1 AFT-full
将下面方程中定义的AFT的基本版本表示为AFT-full:
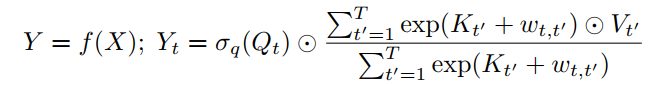
2 AFT-local
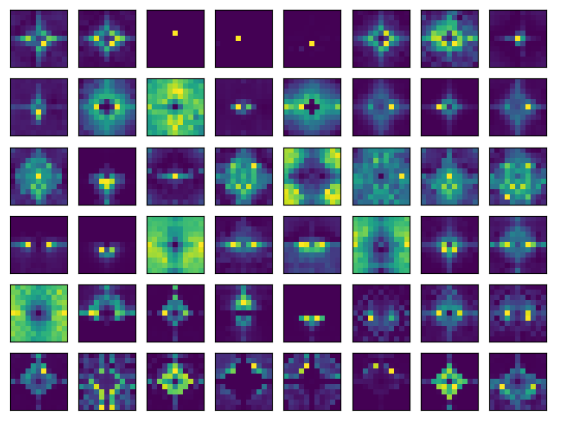
作者发现了训练的标准Transformers倾向于表现出广泛的局部注意力模式。具体地说,把ImagenetNet预训练Vision Transformer(ViT),由12层组成,每层6个Head。为了实现可视化忽略分类标记,将每一层的注意力张量reshape为6×196×196(因为ViT特征图的空间大小为14×14)。然后从ImageNet验证集中采样256张图像。对于每一层和每一个Head,计算平均的average relative 2d attentions、averaged across position和images。这就产生了一组尺寸为12×6×27×27的注意力map(如下图)。

通过上图可以看到,相对注意力Map显示出强烈的局部模式,特别是在lower layers。这激发了AFT的一种变体,称为AFT-local,即只在局部应用一组学习到的相对位置偏差:
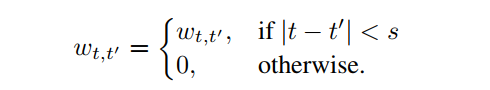
这里s≤T是一个局部window size。AFT-local提供了进一步的计算量的节省,包括参数的数量和时间/空间复杂度。
3 AFT-simple
AFT-local的一个极端形式是当s=0时,即没有学习到位置偏差。这就产生了一个极其简单的AFT版本,AFT-simple,有:
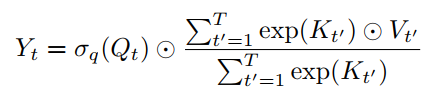

在这个版本中,context reduction进一步简化为元素操作和全局池化。其实AFT-simple类似于线性化注意,公式为:

然而,AFT-simple完全摆脱了点积操作,这促使复杂度从 降低为 。
4 AFT-conv
作者还可以进一步扩展局部化locality的思想,加入空间权值共享,即卷积。这种变体与视觉任务特别相关,因为它通常希望将一个预训练模型扩展到可变大小的输入。具体来说,让 的值只依赖于 和 , 而 为在给定的空间网格(1d或2d)中的相对位置。与CNN类似也可以学习多组位置偏差(重用head的概念作为参考)。为了考虑到#parameters随着 #heads的增加而增长,作者还采用了一个设计,将K的维度与#heads联系起来。这使得AFT-conv可修改为依赖于深度可分离卷积、全局池化和元素操作来实现。
类似的尺寸的AFT-conv学习到的相对位置偏差。
举一个例子,这里将模型构型表示为AFT-conv-h-s,其中h为head的个数,s×s为2d local window size。,于是对于每一个head 来说,有:
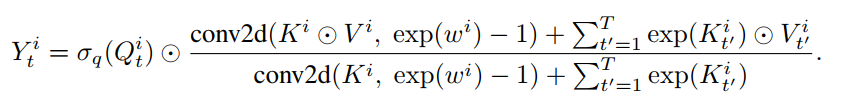
注意,上式可以很容易地解释为一个特殊的卷积层,具有:
-
全局连通性
-
非负卷积权值
-
复杂的除法/乘法门机制
实验表明,这3个方面对AFT-conv的性能都有显著的影响。
5 Parameterization
根据经验,作者发现适当地参数化位置偏差是很重要的。
对于AFT-full和AFT-local,采用w的因数分解形式:
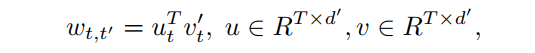
其中 是一个小的嵌入维数(例如128)。这种简单的因式分解不仅大大减少了参数量,而且在训练和测试中都有效地提高了模型的性能。
对于AFT-conv,因式分解的技巧并不适用。相反,作者采用一个简单的重新参数化,对于每个head i,让:
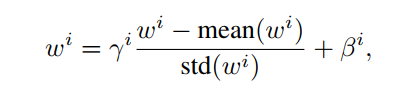
其中 是可学习增益和偏置参数,均初始化为0。

3实验
3.1 Image Autoregressive Modeling
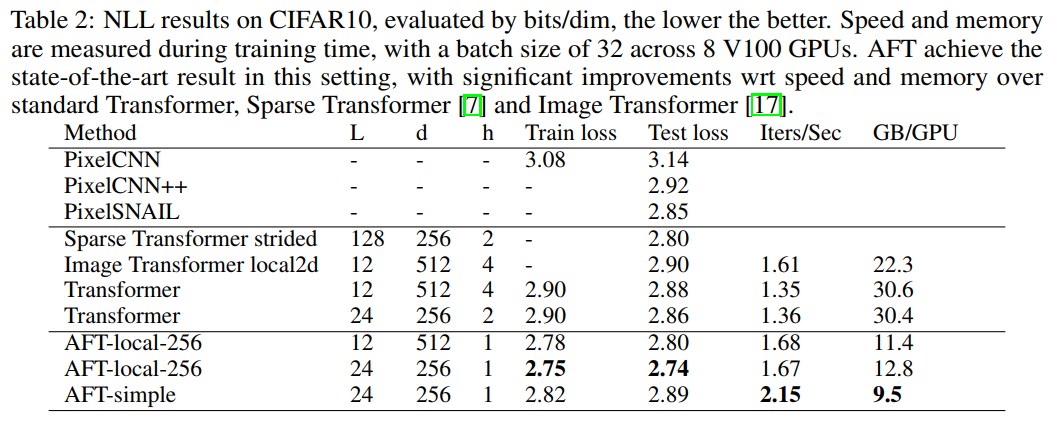
SOTA模型对比
Factorization的影响

3.2 Language Modeling
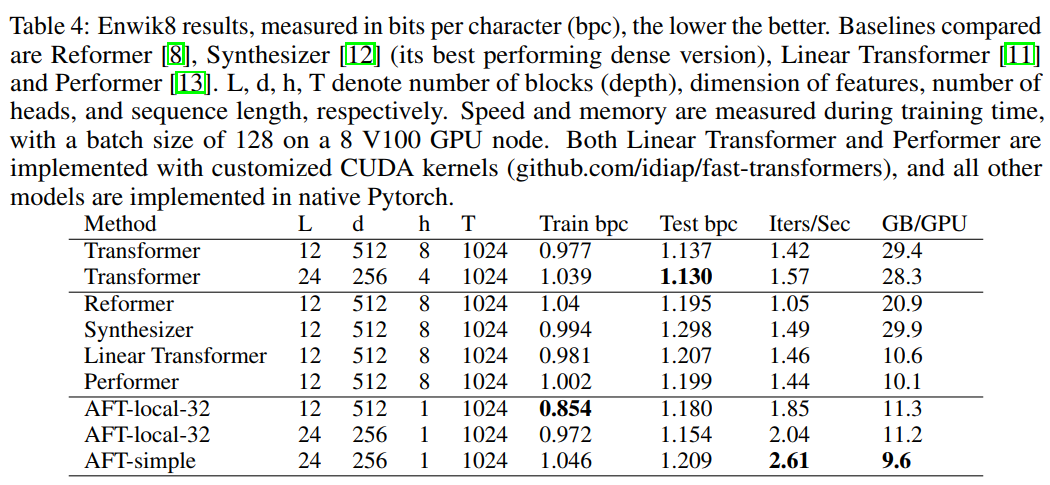
SOTA模型对比
local window size的影响

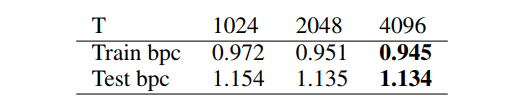
Longer sequence size
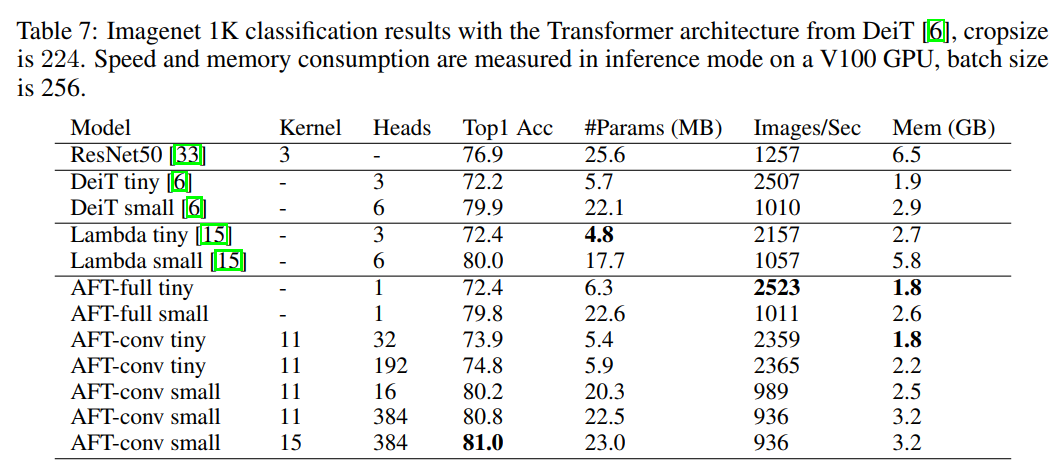
3.3 Image Classification

4参考
[1].An Attention Free Transformer
5推荐阅读

项目实践 | 从零开始边缘部署轻量化人脸检测模型——EAIDK310部署篇

项目实践 | 从零开始边缘部署轻量化人脸检测模型——训练篇

Google新作 | 详细解读 Transformer那些有趣的特性(建议全文背诵)

极品Trick | 在ResNet与Transformer均适用的Skip Connection解读

Transformer又一城 | Swin-Unet:首个纯Transformer的医学图像分割模型解读
本文论文原文获取方式,扫描下方二维码
回复【AFT】即可获取项目代码
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
