
Google AI教你如何啃NLP中的硬骨头:开放域长形式问答系统

新智元报道
新智元报道
来源:外媒
编辑:PY
【新智元导读】 开放域长格式问答(Open-domain long-on answering (LFQA))是自然语言处理的一项基本挑战。谷歌AI利用最新的稀疏注意力模型和基于检索的模型推出了一个新系统,对于回答长篇问题有着杰出的效果。
开放域长时间回答(LFQA)问题是自然语言处理(NLP)中的一个基本挑战,涉及与给定查询相关的检索文档,并且根据它们生成详细的有大段文字的答案。
近年来,在虚拟开放域问答系统(QA)方面取得了显著进展。
在这种技术中,一个的短语就足以回答一个问题,但是对于长形式的问题回答(LFQA)则表现不理想。
LFQA 是一个重要的任务,主要是因为它提供了一个测试生成文本模型的真实性的平台。
但是,现有的基准和评估指标并不完全适用于 LFQA 的进展。
在最近即将在 NAACL 2021上发表的一篇题为「长形式问答进步中的障碍」的论文中,Google.ai 提出了一个新的开放域长形式问答系统,该系统利用了 NLP 的两个最新进展:
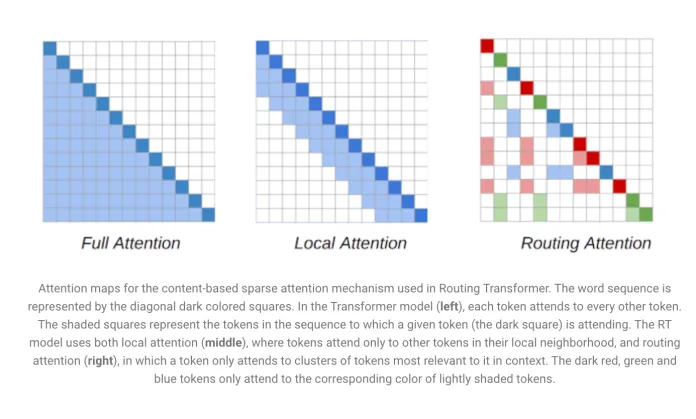
一个是最先进的「稀疏注意模型」(sparse attention models),例如RT(Routing Transformer),允许基于注意力的模型扩展到长序列。
另一个是基于检索的模型,例如 REALM,可以方便检索与给定查询相关的维基百科文章。

该系统在生成答案之前,将来自多个检索到的维基百科文章中与给定问题相关的信息组合在一起。
ELI5是唯一可用于长形式问题回答的大规模公开数据集,该系统在 ELI5上实现了一个新的最先进的状态,。
然而,尽管该系统在公共排行榜上名列前茅,研究人员已经发现了一些关于ELI5数据集和相关的评估指标令人担忧的事情。
特别是,他们发现很少有证据表明,模型使用的检索条件和琐碎的基线(例如,输入复制)胜过现代系统。研究人员还观察到,数据集中存在明显的训练/验证重叠。
文本生成
NLP 模型的主要组成部分是 Transformer 体系结构。序列中的每一个令牌(token )都会照顾到序列中的每一个其他令牌,从而形成一个可以根据序列长度进行二次伸缩的模型。
RT 模型引入了一种动态的、基于内容的机制,降低了 Transformer 模型中注意力的复杂性。
NLP 模型的主要组成部分是 Transformer 体系结构。序列中的每一个令牌都会照顾到序列中的每一个其他令牌,从而形成一个可以根据序列长度进行二次伸缩的模型。RT 模型引入了一种动态的、基于内容的机制,降低了 Transformer 模型中注意力的复杂性。
RT 工作的关键因素是,每一个能参与到其他每个令牌的令牌通常是多余的,可以通过本地和全局注意力的组合来近似。
RT 模型是基于 PG-19数据集的语言建模目标进行预训练的。


信息检索
研究人员将 RT 模型与来自 REALM 的检索结合起来,证明了 RT 模型的有效性。
REALM 模型是一种基于检索的模型,它利用最大限度的内部产品搜索来获取与特定查询或问题相关的维基百科文章。
研究人员通过使用「对比损失」提高了 REALM 检索的质量。
评估
该模型通过 ELI5数据集进行了测试,ELI5数据集是 KILT 基准的一部分,也是唯一公开的大规模 LFQA 数据集。接下来,他们对来自 KILT 的 ELI5数据集上的预训练 RT 模型和来自 c-REALM 的检索进行微调。
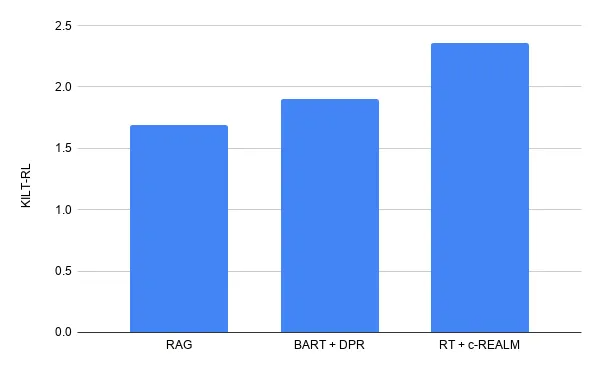
根据已经提交的结果,在 ELI5上的 KILT 排行榜上的长形式的问题回答结果第一位是 RT+c-REALM,得分为2.36。
尽管这种模式在排行榜上名列前茅,但仍然存在着一些挑战。
参考资料:
https://www.marktechpost.com/2021/03/27/google-ai-introduces-a-new-system-for-open-domain-long-form-question-answering-lfqa/
