
送书 | aiohttp异步协程爬取同程旅行酒店评论并作词云图
大家好!我是啃书君!
Python并发编程有三种方式:多线程(Threading)、多进程(Process)、协程(Coroutine),使用并发编程会大大提高程序的效率,今天我们将学习如何选择多线程、多进程和协程来提高代码的效率、如何使用异步协程,并用协程来获取同程旅行酒店的评论数据。
并发编程
多线程(Threading)
多线程(Threading):从软件或者硬件上实现多个线程并发执行的技术。能够在同一时间执行多于一个线程,进而提升整体处理性能,利用CPU和IO可以同时执行的原理,让CPU不会干巴巴地等待IO完成。
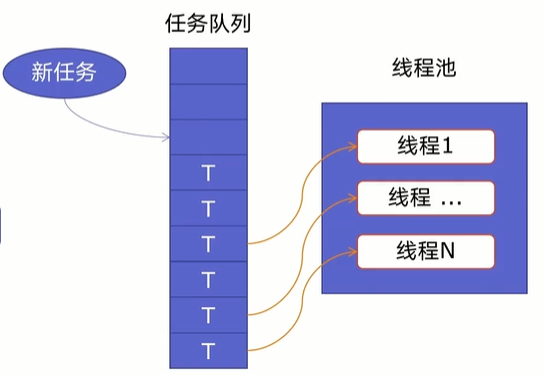
工作方式:多线程由三个部分组成:新任务、任务队列、线程。由于新建线程系统是需要分配资源的,终止线程系统是需要回收资源的,为了重用线程,把线程放在一个线程池中,如下图所示:
-
线程池:里面提前建好N个线程,这些都会被重复利用; -
任务队列:当有新任务的时候,会把任务放在任务队列中。
当任务队列里有任务时,线程池的线程会从任务队列中取出任务并执行,执行完任务后,线程会执行下一个任务,直到没有任务执行后,线程会回到线程池中等待任务。
多进程(Process)
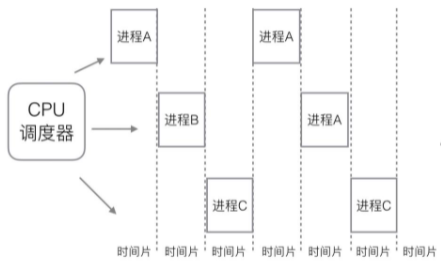
多进程:一个程序的执行实例就是一个进程,每一个进程提供执行程序所需的所有资源,利用多核CPU的能力,真正的并行执行任务。
工作方式:通过CPU调度器来并发执行进程,如下图所示:
协程(Coroutine)
协程:一种比多线程高效得多的并发模型,是无序的,为了完成某个任务,在执行的过程中,不同程序单元之间过程中无需通信协调,也能完成任务的方式,在单线程利用CPU和IO同时执行的原理,实现函数异步执行。
工作方式:如下图所示:
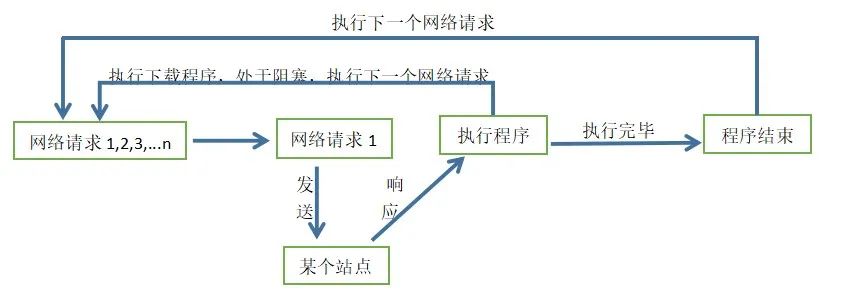
当请求程序发送网络请求1并收到某个站点的响应后,开始执行程序中的下载程序,由于下载需要时间或者其他原因使处于阻塞状态,请求程序和下载程序是不相关的程序单元,所以请求程序发送下一个网络请求。
并发编程对比
简单了解了并发编程的三种方式,接下来将对比这三种方式的优缺点并根据任务来选择对应的技术。
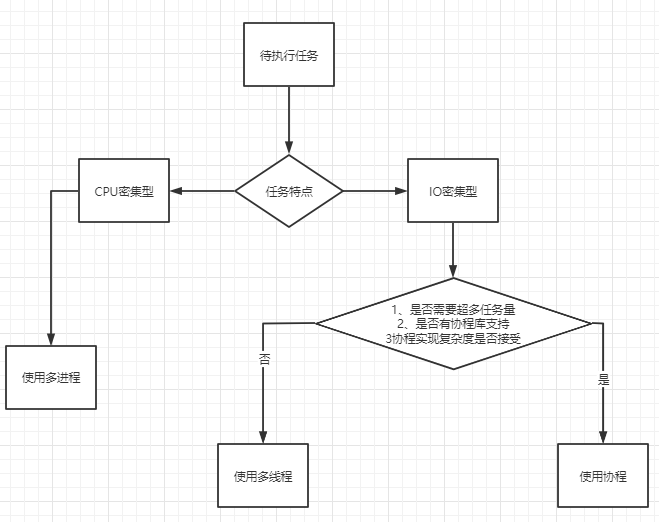
多进程Process
-
优点:可以利用多核CPU并行运算; -
缺点:占用资源最多、可启动数目比线程少; -
适用于:CPU密集型计算。
多线程threading
-
优点:比进程更轻量级,占用资源少; -
缺点:只能并发执行,不能利用多CPU,启动数目有限,占用内存资源,有线程切换开销; -
适用于:IO密集型计算、同时运行的任务数目要求不多。
协程Corutine
-
优点:内存开销最少,启动协程数量最多; -
缺点:之前的库有限制、代码实现复杂; -
适用于:IO密集型计算、需要超多任务运行。
有人可能不知道什么是CPU、IO密集型计算,我们来简单讲解一下:
-
CPU密集型:指I/O在很短的时间就可以完成,CPU需要大量的计算机和处理,CPU占用率很高,压缩解压、加密解密、正则表达式搜索等都属于CPU密集型计算。 -
IO密集型:指I/O(硬盘/内存)的读写操作,CPU占用率较低,文件处理程序、网络爬虫、读写数据库都属于IO密集型计算。
好了,最后通过一张图来总结如何选择并发编程的方式:
异步协程
asyncio模块
asyncio模块是Python中实现协程的模块之一,其语法格式如下:
import asyncio
#定义协程
async def myfunc(url):
await 响应的数据或调用下一个方法等等
#获取事件循环
loop=asyncio.get_event_loop()
#创建task列表
tasks=[loop.create_task(myfunc(url))]
#执行爬虫事件列表
loop.run_until_complete(asyncio.wait(tasks))
其中:
-
async:声明该方法是异步协程方法; -
await:声明为异步协程可等待对象; -
create_task:创建线程任务;
注意:异步协程操作不能出现同步操作,否则异步操作将失效或报错。
aiohttp库
requests请求库是不支持异步协程的,所以我们使用aiohttp请求库,这个请求库只能发送异步请求,下篇文章我们学习更强大的异步请求库httpx,httpx请求库既可以发送同步请求,也可以发送异步请求。
aiohttp基本使用
使用语法为:
import aiohttp
import asyncio
async def main():
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
print(await 响应的数据或调用下一个方法等等)
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
先导入aiohttp模块和asyncio模块,aiohttp.ClientSession() 相当于把aiohttp的功能传递给session,也就是说语法中的ClientSession()相当于aiohttp,接着我们就可以使用client来调用get请求调用asyncio.get_event_loop()方法进入事件循环,再调用loop.run_until_complete(main())方法运行事件循环,直到main运行结束。
post请求
网页请求中有两种类型,一种是Form Data类型和Request Playload类型
当我们发送post请求中,需要根据请求类型来传递是否使用data参数还是使用json参数
params = [('key', 'value1'), ('key', 'value2')]
async with aiohttp.ClientSession() as session:
#data参数
async with session.post(url,data=params) as resp:
...
#json参数
async with session.post(url,json=params) as resp:
有时候,我们URL参数构造正确却获取不到数据,有可能是因为post请求中的参数选择不正确,
那么什么时候使用data参数,什么时候json参数呢?
判断方法很简单,当出现如下图的情况时,该网页请求是Form Data类型,要使用data参数:
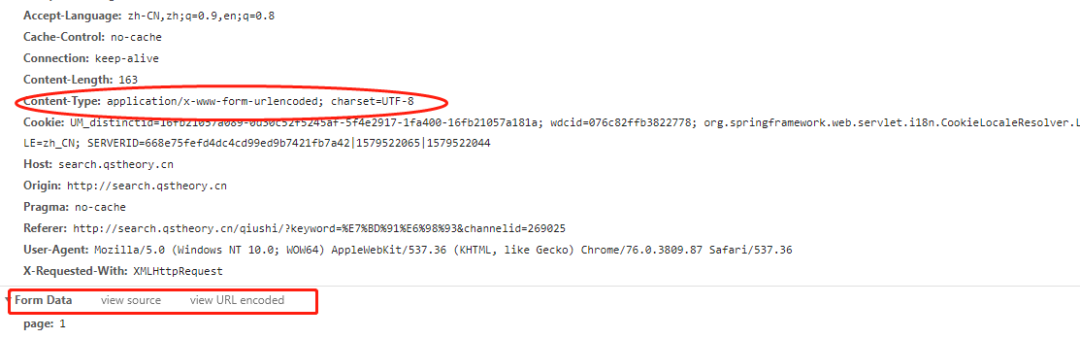
当出现如下图情况时,该网页请求是Request Playload类型,要使用json参数:
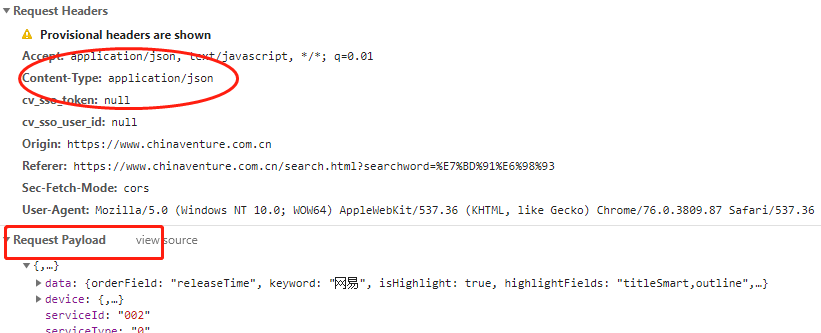
超时
在某些情况下,我们调用第三方接口时,响应时间无法估计,这时可以指定超时时间,如果超时未处理成功,则直接跳过它,继续向下执行。aiohttp提供了ClientTimeout方法来设置超时,其语法格式如下:
timeout=aiohttp.ClientTimeout(total=5*60, connect=None,sock_connect=None, sock_read=None)
async with aiohttp.ClientSession(timeout=timeout) as session:
...
默认情况下,aiohttp使用总共300 秒(5 分钟)的超时时间,这意味着整个操作应该在 5 分钟内完成。
其中:
-
total:整个操作的最大秒数,包括连接建立、请求发送和响应读取; -
connect:连接建立新连接或在超过池连接限制时等待来自池的空闲连接的最大秒数; -
sock_connect:连接到新连接的对等点的最大秒数; -
sock_read:从对等方读取新数据部分之间允许的最大秒数。
限制连接池大小
当我们要获取的数据量很大时,为了提高程序效率或防止访问网页过多造成对方网页瘫痪,通常情况下要设置连接池的大小,aiohttp提供了TCPConnector方法来限制连接池的大小,其语法格式为:
conn = aiohttp.TCPConnector(limit=30)
async with aiohttp.ClientSession(connector=conn) as session:
...
上面的设置是并行连接总数限制为30,默认情况下限制数是100,当我们不想设置限制数目时,可以把limit参数中的值改为0即可。
好了,aiohttp请求库讲解到这里,接下来我们正式开始爬取同程旅行酒店评论。
实战演练
这次的爬虫过程是:
-
评论数据网页分析; -
酒店列表网页分析; -
同步请求获取酒店id -
异步请求获取酒店评论; -
保存数据到MongoDB中; -
绘制词云图。
评论数据网页分析
随意进入一个酒店的详情页并打开开发者工具,如下图所示:
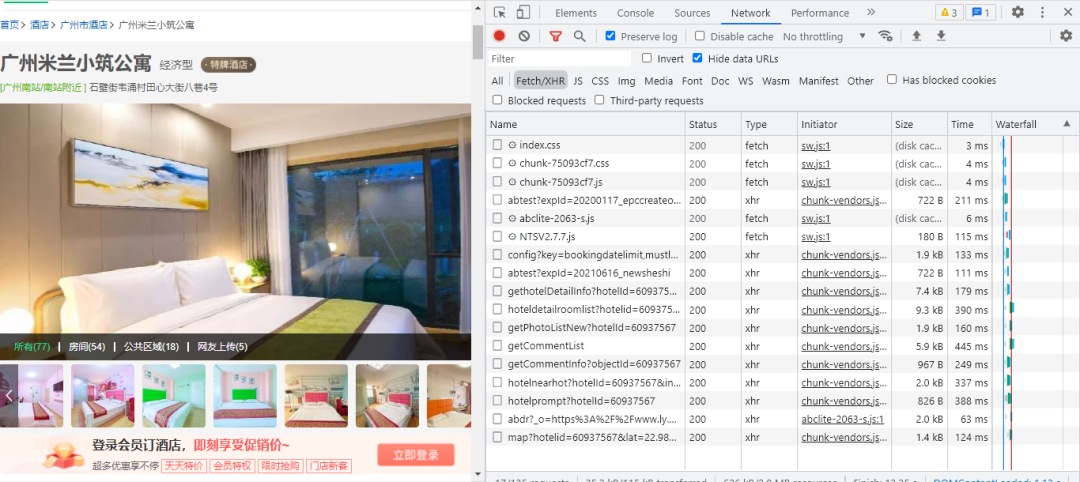
经过查找,我们发现评论数据保存在getCommentList数据包中,如下图所示:
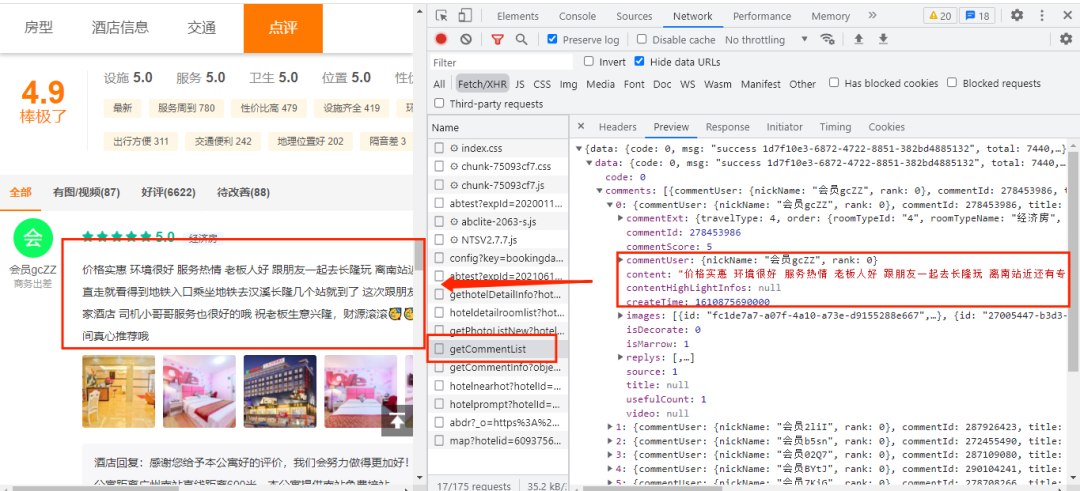
那么我们观察一下getCommentList数据包的headers信息,如下图所示:
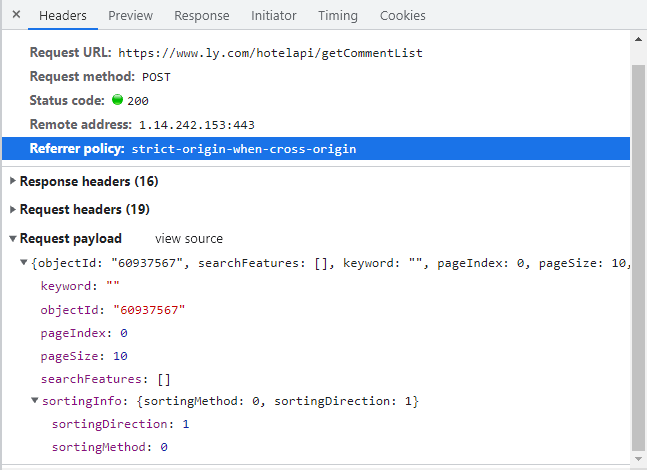
请求方式是post请求,而且是Request payload类型,所以我们在使用json参数。
经过观察,我们发现objectId是酒店的id,pageIndex是翻页参数,pageSize是每个url存放的数量,其他的参数要么是空,要么是定值,所以我们只要知道酒店的id就可以构造url来获取酒店的评论数据了。
酒店列表页网页分析
进入同程旅行酒店列表网页并打开开发者工具,如下图所示:
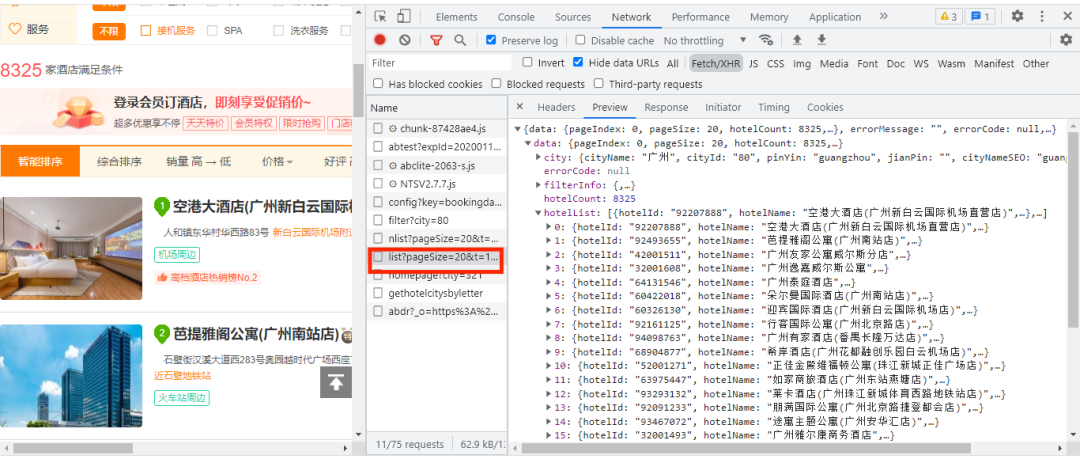
经过查找,发现酒店基本数据(酒店id等)存放在上图红框的数据包中,其URL链接为:
https://www.ly.com/hotelapi/v2/list?pageSize=20&t=1634638146507&city=80&inDate=2021-10-19&outDate=2021-10-20&filterList=8888_1&pageIndex=0&sugActInfo=
观察URL链接,可以推测pageSize每一页的酒店数据量,t是时间戳,city是城市编号,inDate、outDate为入住和离店的时间,filterList为定值,pageIndex是翻页。
好了,网页分析就到这里了,接下来正式开始编写代码来爬取评论数据。
同步请求获取酒店id
由于我们请求的酒店列表页的URL只要三四个,那么使用同步请求即可,主要代码如下图所示:
async def get_link(url):
response=requests.get(url, headers=headers)
json = response.json()
data = json.get('data').get('hotelList')
hotelName_list = []
task=[]
for i in data:
hotelId = i.get('hotelId')
hotelName=i.get('hotelName')
task.append(get_commtent(hotelId,hotelName))
hotelName_list.append(hotelName)
await asyncio.wait(task)
首先定义协程方法get_link(),发送get网络请求,返回的数据类型为json格式,再通过get()方法来获取酒店名及酒店id,创建一个任务列表task,并将自定义的get_commtent()方法放在task任务列表中。
获取酒店评论
酒店id、酒店名已经获取了,接下来构造参数,主要代码如下所示:
#构造参数
data = {
'keyword': '',
'objectId': hotelId,
'pageIndex': i,
'pageSize': '20',
'searchFeatures': [],
'sortingInfo': {
'sortingDirection': '1',
'sortingMethod': '0'
}
}
发送异步请求,主要代码如下图所示:
async with aiohttp.ClientSession()as session: async with session.post(url,json=data,headers=headers)as response: Json = await response.json() data = Json.get('data').get('comments') if data != None: for i in data: commtent_list = { 'hotelName': hotelName, 'content': i.get('content').replace(' ', ''), 'commentScore': i.get('commentScore'), 'createTime': i.get('createTime') } await saving_data(commtent_list) elif data == None: commtent_list = { 'hotelName': hotelName, 'content': '0', 'commentScore': '0', 'createTime': '0' } await saving_data(commtent_list)
首先通过async语法来声明为异步协程操作,再通过post()来发送网络请求,使用await方法来声明响应内容为异步协程可等待对象,再通过get()方法来提取数据并把数据传递到自定义方法saving_data()中。
注意:有些酒店可能是新开业的原因,没有评论,所以我们使用if-elif语句来防止因为没有评论而报错。
数据保存
数据已经获取了,接下来把数据保存在MongoDB数据库中,首先创建MongoDB数据库和数据集合,主要代码如下所示:
async def create_db(hotelName): #连接数据库 client = pymongo.MongoClient(host='localhost', port=27017) #创造数据库 db = client['comment_data'] #创建数据表 colist=db.list_collection_names() for i in hotelName: if i not in colist: db.create_collection(i)
创建数据库后,接下来将保存数据,主要代码如下图所示:
async def saving_data(commtent_list): #连接数据库 client=pymongo.MongoClient(host='localhost',port=27017) db=client['comment_data'] collection=db[commtent_list['hotelName']] #插入数据到数据库中 result=collection.insert_one(commtent_list)
由于代码比较简单,我就直接在代码里面写注释。
最后调用asyncio.get_event_loop()方法进入事件循环,再调用loop.run_until_complete(get_link())方法运行事件循环,直到function运行结束。主要代码如下所示:
for i in range(0,3): t=time.time() url = f'https://www.ly.com/hotelapi/v2/list?pageSize=20&t={t}&city=80&inDate=2021-10-17&outDate=2021-10-18&filterList=8888_1&pageIndex={i}&sugActInfo=' loop=asyncio.get_event_loop() loop.run_until_complete(get_link(url))
运行结果如下图所示:
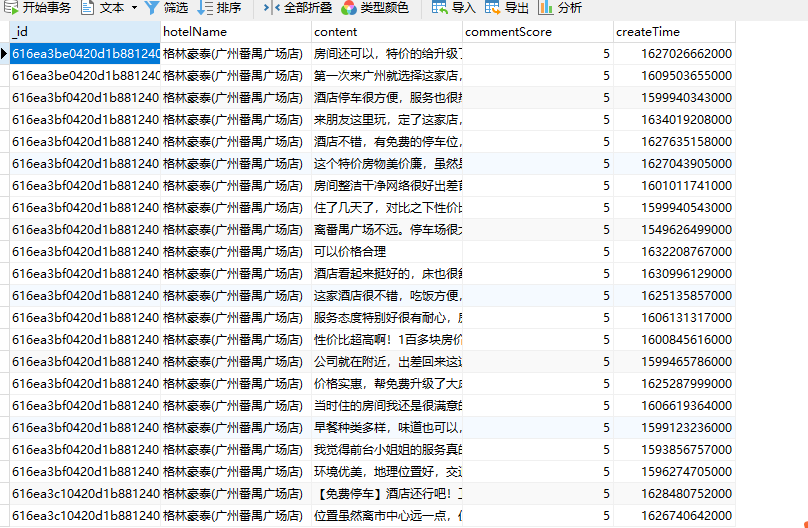
绘制词云

从词云图中看出,该酒店总体评价是不错,好,干净。
好了,aiohttp异步协程爬取同程旅行酒店评论就讲到这里了,感谢观看!!!
送书
又到了每周三的送书时刻,今天给大家带来的是《Python一行流:像专家一样写代码》
你会学到什么?
下面是你会学到的内容的概述。
1 Python温故知新 介绍 Python 的基础知识,让你重新检视自己的 Python 知识。
2 Python技巧 包括10个一行流技巧,帮助你熟练掌握基本知识,例如列表解析、文件输入、lambda函数、map()和zip()、all()量词、切片,以及基础的列表运算。你还会学到如何引入和操作各种数据结构,利用它们来解决各种各样的日常问题。
3 数据科学 包含了数据科学方面的10个一行流程序,全部基于 NumPy 库构建。NumPy 处于 Python 强大的机器学习和数据科学能力的核心,你将会学到基本的 NumPy 知识,如数组、形状、轴、类型、广播、高级索引、切片、排序、搜索、聚合与统计。
4 机器学习 涵盖了使用 Python 的 scikit-learn 库进行机器学习的10个一行流程序,会涉及值预测的回归算法,这些算法的例子包括线性回归、K-近邻算法和神经网络。你也会学到分类算法,比如逻辑回归、决策树学习、支持向量机和随机森林。此外,还会学习如何计算多维数据阵列的基本统计数据,以及用于无监督学习的 K-Means 算法,这些都是机器学习领域最为重要的算法与范式。
5 正则表达式 包含10个一行流程序,帮助你用正则表达式实现更多的目标。你会学到各种基本的正则表达式,并把它们组合(然后再组合)以创建更加高级的正则表达式,还会学习如何使用分组和命名组、反向查找、转义字符、空白字符、字符集(以及反向字符集)和贪婪/非贪婪运算符。
6 算法 包含了10个一行流算法程序,涉及广泛的计算机科学主题,包括拟合、回文、超集、换元、阶乘、质数、斐波那契数列、混淆、搜索和基于算法的排序。其中许多内容将构成更高级算法的基础,是进入全面系统的算法学习的良好导引。
后记 总结全书,让你带着升级后的全新 Python 编程技能,去面对真实世界的考验。
点击下方回复:送书 即可!