
都在刷的力扣算法题,居然长这样?
大家好,可以叫我才哥。
最近 有好朋友在咱们交流群分享力扣算法题,感觉还蛮好玩的。然后才哥去力扣看了看,很快就怂了,觉得自己像个傻子,傻傻的都不会写!!
不过,硬着头皮写了一段时间,发现还是收获很多,对于锻炼逻辑思维能力和编码能力都有很不错的助力,就是费时间一个算法题可能要研究一个晚上才能独立码出理想的代码。
那么,力扣里的算法题都是什么样的呢?大家都喜欢刷什么难度的题,通过率都如何?咱们今天就简单介绍一下吧!
目录:
1. 数据获取
2. 数据可视化
2.1. 难度分布
2.2. 通过率分布
2.3. 提交数分布
2.4. 题解数分布
3. 那些最热门和最噩梦的算法题
3.1. 最热门
3.2. 最噩梦
3.3. 最简单?
1. 数据获取
直接用python从力扣爬取全部算法题题库列表数据即可
# 题库列表数据接口地址
url = 'https://leetcode-cn.com/api/problems/all/'
由于获取的数据是json格式的,所以比较好解析,具体数据爬取及清洗处理过程见下面代码:
import requests
import pandas as pd
url = 'https://leetcode-cn.com/api/problems/all/'
r = requests.get(url)
data = r.json()
# 多层字典解析
df = pd.json_normalize(data['stat_status_pairs'])
# 只筛选需要用到的列
df = df[['stat.question_id', 'stat.question__title',
'stat.total_acs', 'stat.total_submitted',
'stat.total_column_articles', 'stat.frontend_question_id',
'difficulty.level']]
# 重命名列名为中文名
df.columns = ['id', '题目名称',
'通过数', '提交数',
'题解数', '题目id',
'难度']
# 将难度枚举数字替换为 描述形容词(这里用到replace)
df['难度'].replace([1, 2, 3], ['简单', '中等', '困难'], inplace=True)
# 计算通过率(这里用到assign)
df = df.assign(通过率 = df.通过数/df.提交数)
# 由于题目id含有标签(如LCP 11、面试题 17等),这里将标签解析出来为(LCP、面试题等)
df = df.assign(题目标签 = df.题目id.str.extract(r'(\S*?\s*\S*?)[\s]*\d+'))
df['题目标签'].replace('', 'ID类', inplace=True)
df.head()
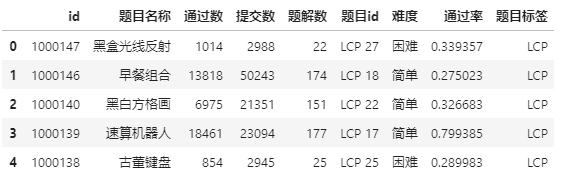
这里涉及到几个pandas函数的使用,大家可以参考历史推文《再推荐几个好用的pandas函数,继续加快你数据处理的速度》和《学会这些好用的pandas函数,让你的数据处理更快人一步》进行更多了解。
2. 数据可视化
对于力扣的题库,我们简单看看难度分布、通过率、提交数分布等等情况,以及了解下通过率最低的都是什么魔鬼题目呢!?
本文数据可视化部分使用的是可视化库plotly,感兴趣的可以参考此前教程了解:
2.1. 难度分布
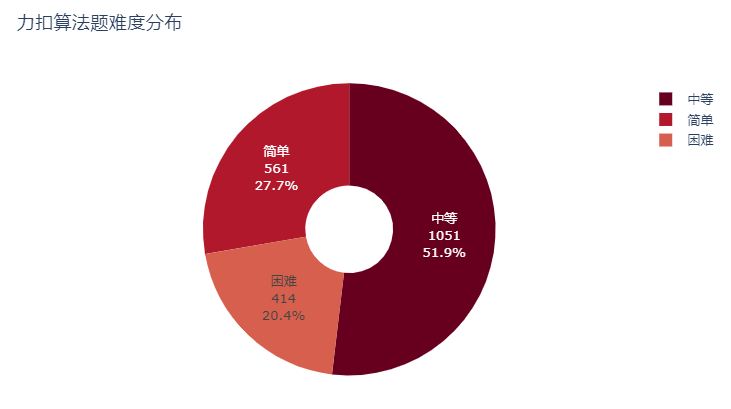
在一共的2,026道算法题中,中等难度最多高达1,051题占比51.9%,其次是简单难度占比27.7%,困难难度一共414题仅占20.4%。
绘图代码:
# 力扣算法题难度分布
import plotly.express as px
df['值'] = 1
fig = px.pie(df, values="值", names='难度',
color_discrete_sequence=px.colors.sequential.RdBu,
hole=.3, # 设置空心半径比例
title='力扣算法题难度分布',
)
fig.update_traces(textposition='inside',
textinfo='percent+label+value' # 数据标签显示的内容
)
fig.show()
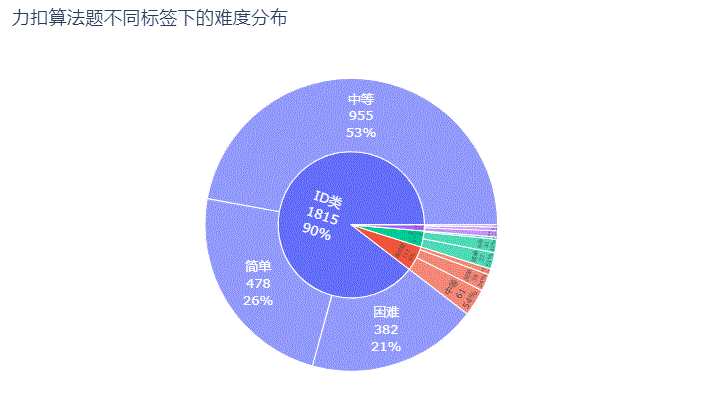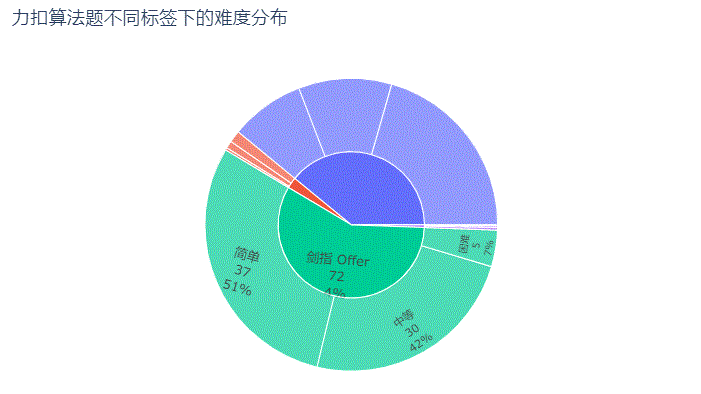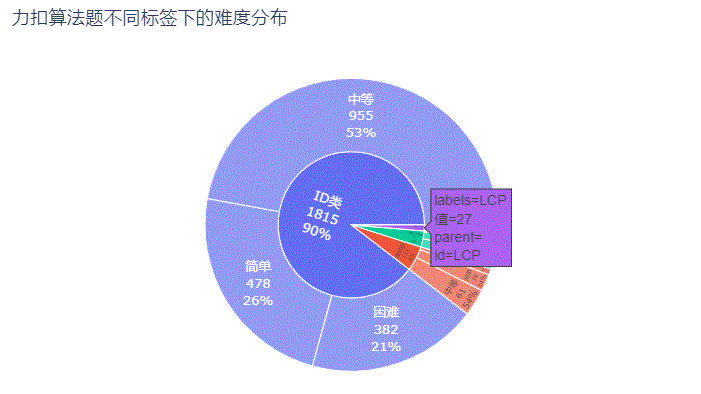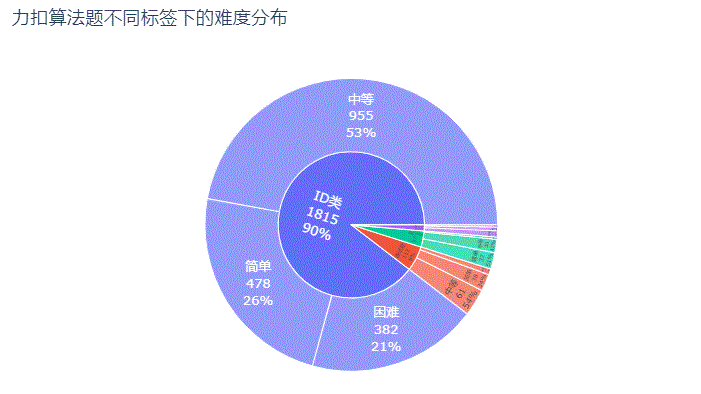
那么,不同标签下难度分布情况又是什么样呢?
纯ID类的算法题最多,高达1,815题,占了整个题库的90%,它的中等难度题955题占自身题量的53% 面试题类的算法题共112题,中等难度也是最多共61题占比54%,它的困难难度仅占自身题量的12% 剑指 Offer类算法题共72题,简单难度反而最多占比51%,困难难度的仅5题只占自身题量的7%而已 LCP 类算法题共27题,则主要以困难难度为主,共14题占自身题量的52%
绘图代码:
import plotly.express as px
fig = px.sunburst(df,
path=['题目标签', '难度'],
values="值",
title='力扣算法题不同标签下的难度分布',
)
fig.update_traces(textinfo='percent parent+label+value' # 数据标签显示的内容
)
fig.show()
2.2. 通过率分布
整体来看,大部分的算法题的通过率集中在0.4-0.6之间,还蛮近正态分布的。
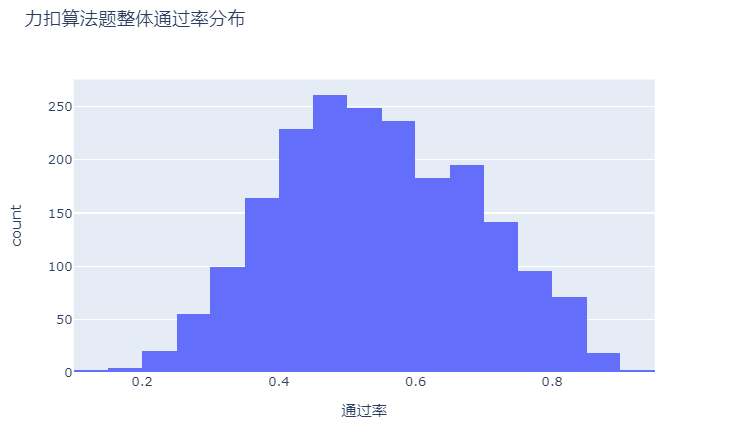
我们对不同难度的算法题进行拆分看通过率,发现确实满足简单的通过率普遍较高、中等的更接近正态分布,困难模式下通过率低了很多。
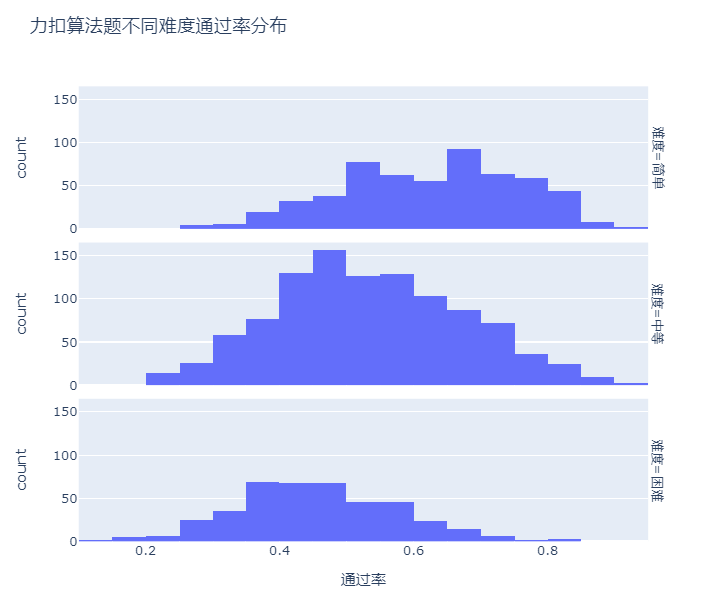
绘图代码:
# 绘制通过率直方图
import plotly.express as px
fig = px.histogram(df, x="通过率",
nbins=20, # 分成20组
facet_row="难度",
title='力扣算法题不同难度通过率分布',
height=600,
category_orders={"难度": ["简单", "中等", "困难"]}
)
fig.show()
2.3. 提交数分布
力扣是2018年2月进入中国大陆,至今刚好3年有余,我们发现最高的提交数就是ID类第1题的两数之和,高达超过379万次提交,不过通过率居然仅仅50.8%不到,有点意思。
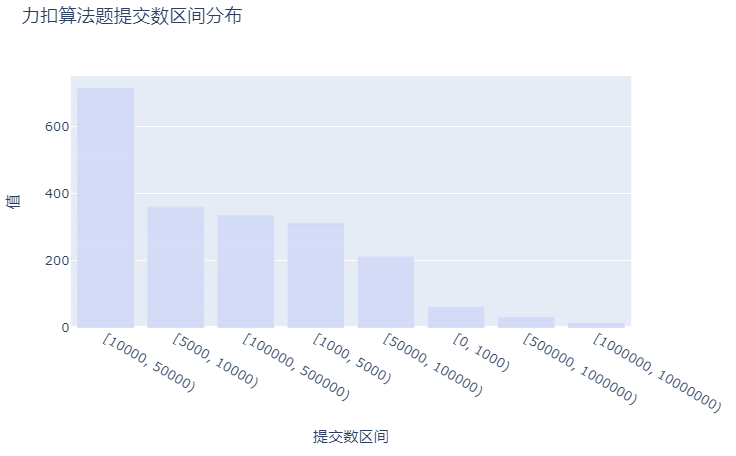
提交数最多的范围是在1万-5万之间,其次是5千-1万,再次是10万-50万。绝大多数算法题的提交数是较多的,毕竟可以重复提交看优化代码后的性能效率嘛。
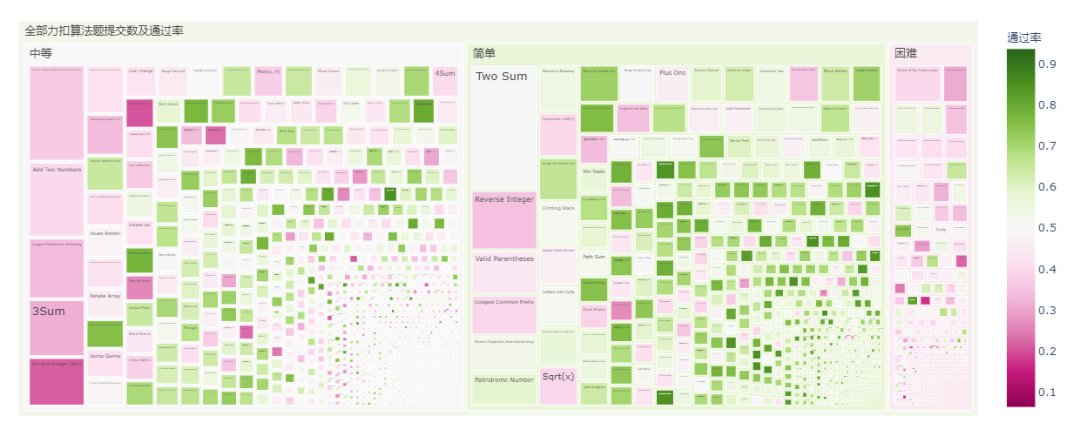
我们对不同难度的算法题按照提交数和通过率绘制树状热图如下:中等难度整体提交数高于简单难度。
(绿色表示通过率大于50%,紫红色表示通过率低于50%)
绘图代码:
import plotly.express as px
import numpy as np
df["all"] = "全部力扣算法题提交数及通过率" # in order to have a single root node
fig = px.treemap(df, path=['all', '难度', '题目名称'], values='提交数',
color='通过率',
color_continuous_scale='PiYG',
color_continuous_midpoint=0.5,
height = 560,
width = 1200,
)
fig.show()
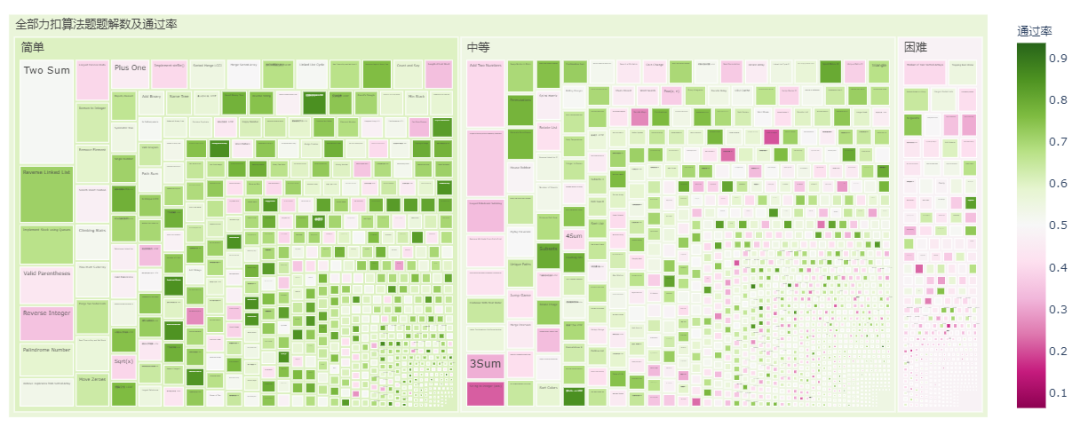
2.4. 题解数分布
对于我这种算法小白来说,看题解是很过瘾的。在力扣题库里,大多数的算法题题解在100以内,其实100-200,200-500范围内。不过,实际看题解的时候会发现题解下面的评论也是很精彩的,毕竟大家都会踊跃讨论,氛围组!
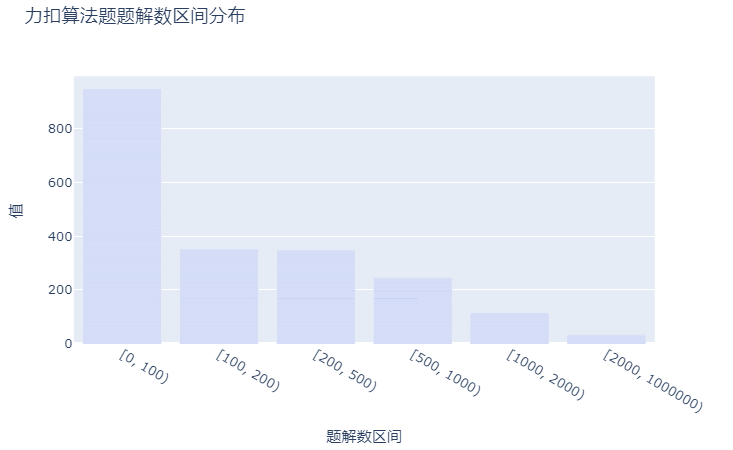
和提交数与通过率的树状矩形图中中等难度提交数更多稍有不同,简单模式的题解数更多些:
3. 那些最热门和最噩梦的算法题
在合计1.416亿次提交数,0.746亿次通过数,63.61万次题解数中,最热门和噩梦的算法题都长什么样呢?
3.1. 最热门
我们先看提交数最多的前三甲:
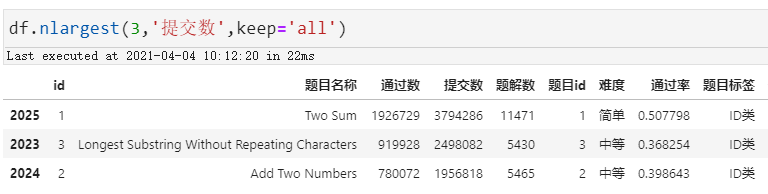
分别是ID类的前3题,最多提交也正常了,毕竟曝光最多嘛
两数之和:379万次提交 无重复字符的最长子串:249万次提交 两数相加:195万次提交
再看题解数最多的前三甲:
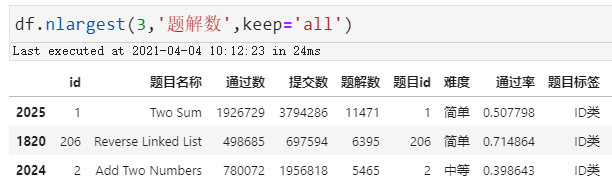
对于两数之和与两数相加在意料之中,居然还冒出了第206题反转链表题解高达6千多,这题的通过率也是老高了达到71.48%!!
3.2. 最噩梦
所谓最噩梦,我们以通过率最低为标尺,可以看到有这么几题通过率居然都低于17%,妥妥的困难模式!
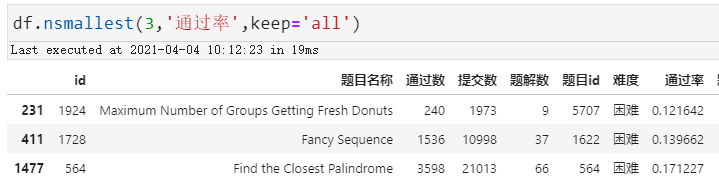
最噩梦之一:5707. 得到新鲜甜甜圈的最多组数
>有一个甜甜圈商店,每批次都烤 batchSize 个甜甜圈。这个店铺有个规则,就是在烤一批新的甜甜圈时,之前所有甜甜圈都必须已经全部销售完毕。给你一个整数 batchSize 和一个整数数组 groups ,数组中的每个整数都代表一批前来购买甜甜圈的顾客,其中 groups[i] 表示这一批顾客的人数。每一位顾客都恰好只要一个甜甜圈。当有一批顾客来到商店时,他们所有人都必须在下一批顾客来之前购买完甜甜圈。如果一批顾客中第一位顾客得到的甜甜圈不是上一组剩下的,那么这一组人都会很开心。你可以随意安排每批顾客到来的顺序。请你返回在此前提下,最多 有多少组人会感到开心。
示例 1:
输入:batchSize = 3, groups = [1,2,3,4,5,6]
输出:4
解释:你可以将这些批次的顾客顺序安排为 [6,2,4,5,1,3] 。那么第 1,2,4,6 组都会感到开心。
示例 2:
输入:batchSize = 4, groups = [1,3,2,5,2,2,1,6]
输出:4
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/maximum-number-of-groups-getting-fresh-donuts
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
最噩梦之二:1622. 奇妙序列
>请你实现三个 API append,addAll 和 multAll 来实现奇妙序列。
请实现 Fancy 类 :
Fancy() 初始化一个空序列对象。
void append(val) 将整数 val 添加在序列末尾。
void addAll(inc) 将所有序列中的现有数值都增加 inc 。
void multAll(m) 将序列中的所有现有数值都乘以整数 m 。
int getIndex(idx) 得到下标为 idx 处的数值(下标从 0 开始),并将结果对 109 + 7 取余。如果下标大于等于序列的长度,请返回 -1 。
示例:
输入:
["Fancy", "append", "addAll", "append", "multAll", "getIndex", "addAll", "append", "multAll", "getIndex", "getIndex", "getIndex"]
[[], [2], [3], [7], [2], [0], [3], [10], [2], [0], [1], [2]]
输出:
[null, null, null, null, null, 10, null, null, null, 26, 34, 20]
解释:
Fancy fancy = new Fancy();
fancy.append(2); // 奇妙序列:[2]
fancy.addAll(3); // 奇妙序列:[2+3] -> [5]
fancy.append(7); // 奇妙序列:[5, 7]
fancy.multAll(2); // 奇妙序列:[5*2, 7*2] -> [10, 14]
fancy.getIndex(0); // 返回 10
fancy.addAll(3); // 奇妙序列:[10+3, 14+3] -> [13, 17]
fancy.append(10); // 奇妙序列:[13, 17, 10]
fancy.multAll(2); // 奇妙序列:[13*2, 17*2, 10*2] -> [26, 34, 20]
fancy.getIndex(0); // 返回 26
fancy.getIndex(1); // 返回 34
fancy.getIndex(2); // 返回 20
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/fancy-sequence
最噩梦之三:564. 寻找最近的回文数
>给定一个整数 n ,你需要找到与它最近的回文数(不包括自身)。
“最近的”定义为两个整数差的绝对值最小。
示例 1:
输入: "123"
输出: "121"
注意:
n 是由字符串表示的正整数,其长度不超过18。
如果有多个结果,返回最小的那个。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/find-the-closest-palindrome
3.3. 最简单?
通过率最高的居然高达90%,其中还有2个是中等难度的。。
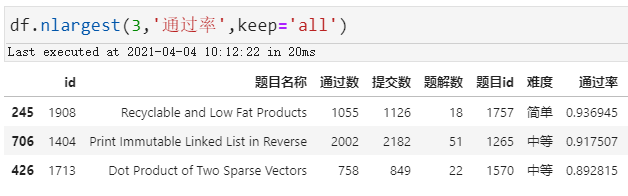
不过,这三题都是会员可见:
可回收且低脂的产品:通过率 93.7% 逆序打印不可变链表:通过率 91.8% 两个稀疏向量的点积:通过率 89.3%
除了会员可见的外,通过率最高的是一个中等难度题,也有高达86.9%的通过率
1689. 十-二进制数的最少数目
>如果一个十进制数字不含任何前导零,且每一位上的数字不是 0 就是 1 ,
那么该数字就是一个 十-二进制数 。例如,101 和 1100 都是 十-二进制数,
而 112 和 3001 不是。
给你一个表示十进制整数的字符串 n ,返回和为 n 的 十-二进制数 的最少数目。
示例 1:
输入:n = "32"
输出:3
解释:10 + 11 + 11 = 32
示例 2:
输入:n = "82734"
输出:8
示例 3:
输入:n = "27346209830709182346"
输出:9
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/partitioning-into-minimum-number-of-deci-binary-numbers
以上就是本期全部内容,感兴趣的可以试试。
超详细!用户留存分析实操攻略 从0到1,掌握数据可视化的基本技巧 从0到1,搭建数据监控体系 促销活动监控,你准备好了吗 够清楚!用户分层与RFM模型可以这么做 数据分析复盘报告,用Excel轻松搞掂! 数据可视化的基本规范,15张图打包一次讲清楚 真实!数据分析师到底是做什么的?

想和小师妹聊天?
想看海量行业资料?
想学习陈老师的思维方式?
想和陈老师讨论具体工作遇到的问题?
想在求职、转行、转岗道路上得到一对一亲自指导?
扫描二维码
↓ ↓ ↓加入十年数据人陈老师的知识星球 ↓ ↓ ↓