
太难了,一个接口超时问题,从应用排查到内核....
来源:https://zhenbianshu.github.io
问题描述
最近在查一个问题,花费了近两个星期,问题算是有了一个小结,是时候总结一下了。
排查过程走了很多弯路,由于眼界和知识储备问题,也进入了一些思维误区,希望此问题能以后再查询此类问题时能有所警示和参考。
而且很多排查方法和思路都来自于部门 leader 和 组里大神给的提示和启发,总结一下也能对这些知识有更深的理解。
这个问题出现在典型的高并发场景下,现象是某个接口会偶尔超时。
查了几个 case 的日志,发现 httpClient 在请求某三方接口结束后输出一条日志时间为 A,方法返回后将请求结果解析成为 JSON 对象后,再输出的日志时间为 B, AB之间的时间差会特别大,100-700ms 不等,而 JSON 解析正常是特别快的,不应该超过 1ms。
GC
首先考虑导致这种现象的可能:
应用上有锁导致方法被 block 住了,但 JSON 解析方法上并不存在锁,排除这种可能。
JVM 上,GC 可能导致 STW。
系统上,如果系统负载很高,操作系统繁忙,线程调度出现问题可能会导致这种情况,但观察监控系统发现系统负载一直处于很低的水平,也排除了系统问题。
我们都知道 JVM 在 GC 时会导致 STW,进而导致所有线程都会暂停,接下来重点排查 GC 问题。
首先我们使用 jstat 命令查看了 GC 状态,发现 fullGC 并不频繁,系统运行了两天才有 100 来次,而 minorGC 也是几秒才会进行一次,且 gcTime 一直在正常范围。
由于我们的 JVM 在启动时添加了 -XX:+PrintGCApplicationStoppedTime 参数,而这个参数的名字跟它的意义并不是完全相对的,在启用此参数时,gclog 不仅会打印出 GC 导致的 STW,其他原因导致的 STW 也会被记录到 gclog 中,于是 gclog 就可以成为一个重要的排查工具。
查看 gclog 发现确实存在异常状况,如下图:
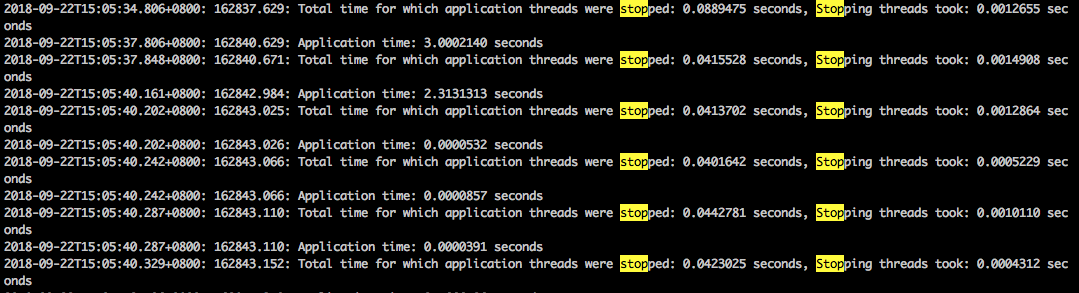
系统 STW 有时会非常频繁地发生,且持续时间也较长,其中间隔甚至不足 1ms。
也就是说一次停顿持续了几十 ms 之后,系统还没有开始运行,又会进行第二次 STW,如上图的情况,系统应该会一次 hang 住 120ms,如果次数再频繁一些,确实有可能会导致接口超时。
安全点
那么这么频繁的 STW 是由什么产生的呢,minorGC 的频率都没有这么高。
我们知道,系统在 STW 前,会等待所有线程安全点,在安全点里,线程的状态是确定的,其引用的 heap 也是静止的,这样,JVM 才能安心地进行 GC 等操作。
至于安全点的常见位置和安全点的实现方式网卡有很多文章介绍这里不再多提了,这里重点说一下安全点日志。
安全点日志是每次 JVM 在所有线程进入安全点 STW 后输出的日志,日志记录了进入安全点用了多久,STW 了多久,安全点内的时间都是被哪个步骤消耗的,通过它我们可以分析出 JVM STW 的原因。
服务启动时,使用 -XX:+UnlockDiagnosticVMOptions -XX:+PrintSafepointStatistics -XX:+LogVMOutput -XX:LogFile=./safepoint.log 参数,可以将安全点日志输出到 safepoint.log 中。
在安全点日志中,我发现有很多下图类似的日志输出:

从前面的 vmopt 列可以得知,进入安全点的原因是 RevokeBias, 查资料得知,这是在释放 偏向锁。
偏向锁
偏向锁是 JVM 对锁的一种优化,JVM 的开发人员统计发现绝大部分的锁都是由同一个线程获取,锁争抢的可能性很小,而系统调用一次加锁释放锁的开销相对很大,所以引入偏向锁默认锁不会被竞争,偏向锁中的 “偏向” 便指向第一个获取到锁的线程。
在一个锁在被第一次获取后,JVM 并不需要用系统指令加锁,而是使用偏向锁来标志它,将对象头中 MarkWord 的偏向锁标识设置为1,将偏向线程设置为持续锁的线程 ID,这样,之后线程再次申请锁时如果发现这个锁已经 “偏向” 了当前线程,直接使用即可。
而且持有偏向锁的线程不会主动释放锁,只有在出现锁竞争时,偏向锁才会释放,进而膨胀为更高级别的锁。
有利则有弊,偏向锁在单线程环境内确实能极大降低锁消耗,但在多线程高并发环境下,线程竞争频繁,而偏向锁在释放时,为了避免出现冲突,需要等到进入全局安全点才能进行,所以每次偏向锁释放会有更大的消耗。
明白了 JVM 为什么会频繁进行 STW,再修改服务启动参数,添加 -XX:-UseBiasedLocking 参数禁用偏向锁后,再观察服务运行。
发现停顿问题的频率下降了一半,但还是会出现,问题又回到原点。
Log4j
定位
这时候就需要猜想排查了。
首先提出可能导致问题的点,再依次替换掉这些因素压测,看能否复现来确定问题点。
考虑到的问题点有 HttpClient、Hystrix、Log4j2。
使用固定数据替换了三方接口的返回值,删去了 Hystrix,甚至将逻辑代码都删掉,只要使用 Log4j2 输出大量日志,问题就可以复现,终于定位到了 Log4j2,原来是监守自盗啊...
虽然定位到 Log4j2,但日志也不能不记啊,还是要查问题到底出在哪里。
使用 btrace 排查 log4j2 内的锁性能。
首先考虑 Log4j2 代码里的锁,怀疑是由于锁冲突,导致输出 log 时被 block 住了。
查看源码,统计存在锁的地方有三处:
rollover()方法,在检测到日志文件需要切换时会锁住进行日志文件的切分。encodeText()方法,日志输出需要将各种字符集的日志都转换为 byte 数组,在进行大日志输出时,需要分块进行。为了避免多线程块之间的乱序,使用synchronized 关键字对方法加锁。flush()方法,同样是为了避免不同日志之间的穿插乱序,需要对此方法加锁。
具体是哪一处代码出现了问题呢,我使用 btrace 这一 Java 性能排查利器进行了排查。
使用 btrace 分别在这三个方法前后都注入代码,将方法每次的执行时间输出,然后进行压测,等待问题发生,最终找到了执行慢的方法:encodeText()。
排查代码并未发现 encodeText 方法的异常(千锤百炼的代码,当然看不出什么问题)。
使用 jmc 分析问题
这时,组内大神建议我使用 jmc 来捕捉异常事件。给 docker-compose 添加以下参数来启用环境的 JFR。
environment:
- JFR=true
- JMX_PORT=port
- JMX_HOST=ip
- JMX_LOGIN=user:pwd
在记录内查找停顿时间附近的异常事件,发现耗时统计内有一项长耗时引人注目:调用 RandomAccessFile.write() 方法竟然耗时 1063 ms,而这个时间段和线程 ID 则完全匹配。
查看这个耗时长的方法,它调用的是 native 方法 write()...
阶段性小结
native 方法再查下去就是系统问题了,但是目前我们可以给出两个对症下药的解决方案。
服务少记一些日志,日志太多的话才会导致这个问题。
使用 Log4j2 的异步日志,虽然有可能会在缓冲区满或服务重启时丢日志。
同时可以进行一个阶段性的小结。
查问题的过程确实学习到了很多知识,让我更熟悉了 Java 的生态,但我觉得更重要的是排查问题的思路,于是我总结了一个排查问题的一般步骤,当作以后排查此类问题的 checkList。
尽量分析更多的问题 case。找出他们的共性,避免盯错问题点。比如此次问题排查开始时,如果多看几个 case 就会发现,日志停顿在任何日志点都会出现,由此就可以直接排除掉 HttpClient 和 Hystrix 的影响。
在可控的环境复现问题。在测试环境复现问题可能帮助我们随时调整排查策略,极大地缩短排查周期。当然还需要注意的是一定要跟线上环境保持一致,不一致的环境很可能把你的思路带歪,比如我在压测复现问题时,由于堆内存设置得太小,导致频繁发生 GC,让我错认为是 GC 原因导致的停顿。
对比变化,提出猜想。在服务出现问题时,我们总是先问最近上线了什么内容,程序是有惯性的,如果没有变化,系统一般会一直正常运行。当然变化不止是时间维度上的,我们还可以在多个服务之间对比差异。
排除法定位问题。一般我们会提出多个导致问题的可能性,排查时,保持一个变量在变化,再对比问题的发生,从而总结出变量对问题的影响。解决。当我们定位到问题之后,问题的解决一般都很简单,可能只需要改一行代码。
当然还有一个非常重要的点,贯穿始末,那就是数据支持,排查过程中一定要有数据作为支持。通过总量、百分比数据的前后对比来说服其他人相信你的理论,也就是用数据说话。
应用复现
Jdk 的 native 方法当然不是终点,虽然发现 Jdk、docker、操作系统 Bug 的可能性极小,但再往底层查却很可能发现一些常见的配置错误。
为了便于复现,我用 JMH 写了一个简单的 demo,控制速度不断地通过 log4j2 写入日志。将项目打包成 jar 包,就可以很方便地在各处运行了。
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@State(Scope.Benchmark)
@Threads(5)
public class LoggerRunner {
public static void main(String[] args) throws RunnerException {
Options options = new OptionsBuilder()
.include(LoggerRunner.class.getName())
.warmupIterations(2)
.forks(1)
.measurementIterations(1000)
.build();
new Runner(options).run();
}
}
我比较怀疑是 docker 的原因。
但是在 docker 内外运行了 jar 包却发现都能很简单地复现日志停顿问题。而 jdk 版本众多,我准备首先排查操作系统配置问题。
系统调用
这里需要使用到 strace 命令。
这个命令很早就使用过,但我还是不太习惯把 Java 和它联系起来,幸好有部门的老司机指点,于是就使用 strace 分析了一波 Java 应用。
命令跟分析普通脚本一样,strace -T -ttt -f -o strace.log java -jar log.jar, -T 选项可以将每一个系统调用的耗时打印到系统调用的结尾。
当然排查时使用 -p pid 附加到 tomcat 上也是可以的,虽然会有很多容易混淆的系统调用。
对比 jmh 压测用例输出的 log4j2.info() 方法耗时,发现了下图中的状况:

一次 write 系统调用竟然消耗了 147ms,很明显地,问题出在 write 系统调用上。
文件系统
结构
这时候就要好好回想一下操作系统的知识了。
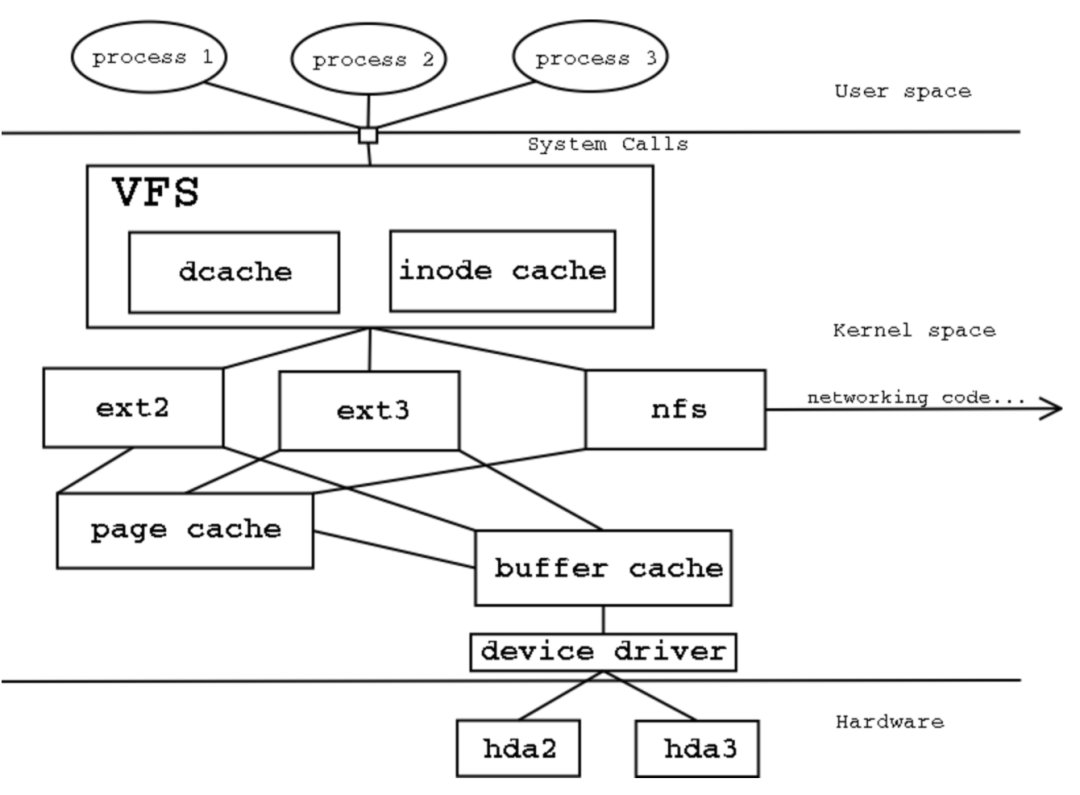
在 linux 系统中,万物皆文件,而为了给不同的介质提供一种抽象的接口,在应用层和系统层之间,抽象了一个虚拟文件系统层(virtual file system, VFS)。
上层的应用程序通过 系统调用 system call 操作虚拟文件系统,进而反馈到下层的硬件层。
由于硬盘等介质操作速度与内存不在同一个数量级上,为了平衡两者之间的速度,linux 便把文件映射到内存中,将硬盘单位块(block)对应到内存中的一个 页(page)上。
这样,当需要操作文件时,直接操作内存就可以了。
当缓冲区操作达到一定量或到达一定的时间后,再将变更统一刷到磁盘上。这样便有效地减少了磁盘操作,应用也不必等待硬盘操作结束,响应速度得到了提升。
而 write 系统调用会将数据写到内存中的 page cache,将 page 标记为 脏页(dirty) 后返回。
linux 的 writeback 机制
对于将内存缓冲区的内容刷到磁盘上,则有两种方式:
首先,应用程序在调用 write 系统调用写入数据时,如果发现 page cache 的使用量大于了设定的大小,便会主动将内存中的脏页刷到硬盘上。在此期间,所有的 write 系统调用都会被阻塞。
系统当然不会容忍不定时的 write 阻塞,linux 还会定时启动 pdflush 线程,判断内存页达到一定的比例或脏页存活时间达到设定的时间,将这些脏页刷回到磁盘上,以避免被动刷缓冲区,这种机制就是 linux 的 writeback 机制。
猜测
了解了以上基础知识,那么对于 write 系统调用为什么会被阻塞,提出了两种可能:
page cache 可用空间不足,导致触发了主动的 flush,此时会阻塞所有对此 device 的 write。
写入过程被其他事务阻塞。
首先对于第一种可能。查看系统配置 dirty_ratio 的大小:20。
此值是 page cache 占用系统可用内存(real mem + swap)的最大百分比,我们的内存为 32G,没有启用 swap,则实际可用的 page cache 大小约为 6G。
另外,与 pdflush 相关的系统配置:系统会每 vm.dirty_writeback_centisecs (5s) 唤醒一次 pdflush 线程, 发现脏页比例超过 vm.dirty_background_ratio (10%) 或 脏页存活时间超过 vm.dirty_expire_centisecs(30s) 时,会将脏页刷回硬盘。
查看 /proc/meminfo 内 Dirty/Writeback 项的变化,并对比服务的文件写入速度,结论是数据会被 pdflush 刷回到硬盘,不会触发被动 flush 以阻塞 write 系统调用。
ext4 的 journal 特性
write 被阻塞的原因
继续搜索资料,在一篇文章(Why buffered writes are sometimes stalled)中看到 write 系统调用被阻塞有以下可能:
http://yoshinorimatsunobu.blogspot.com/2014/03/why-buffered-writes-are-sometimes.html
要写入的数据依赖读取的结果时。但记录日志不依赖读文件;
wirte page 时有别的线程在调用 fsync() 等主动 flush 脏页的方法。但由于锁的存在,log 在写入时不会有其他的线程操作;
格式为 ext3/4 的文件系统在记录 journal log 时会阻塞 write。而我们的系统文件格式为 ext4。
journal
journal 是 文件系统保证数据一致性的一种手段,在写入数据前,将即将进行的各个操作步骤记录下来,一旦系统掉电,恢复时读取这些日志继续操作就可以了。
但批量的 journal commit 是一个事务,flush 时会阻塞 write 的提交。
我们可以使用 dumpe2fs /dev/disk | grep features 查看磁盘支持的特性,其中有 has_journal 代表文件系统支持 journal 特性。
ext4 格式的文件系统在挂载时可以选择 (jouranling、ordered、writeback) 三种之一的 journal 记录模式。
三种模式分别有以下特性:
journal:在将数据写入文件系统前,必须等待 metadata 和 journal 已经落盘了。
ordered:不记录数据的 journal,只记录 metadata 的 journal 日志,且需要保证所有数据在其 metadata journal 被 commit 之前落盘。ext4 在不添加挂载参数时使用此模式。
writeback: 数据可能在 metadata journal 被提交之后落盘,可能导致旧数据在系统掉电后恢复到磁盘中。
当然,我们也可以选择直接禁用 journal,使用 tune2fs -O ^has_journal /dev/disk,只能操作未被挂载的磁盘。
猜测因为 journal 触发了脏页落盘,而脏页落盘导致 write 被阻塞,所以解决 journal 问题就可以解决接口超时问题。
解决方案与压测结果
以下是我总结的几个接口超时问题的解决方案:
log4j2 日志模式改异步。但有可能会在系统重启时丢失日志,另外在异步队列 ringbuffer 被填满未消费后,新日志会自动使用同步模式。
调整系统刷脏页的配置,将检查脏页和脏页过期时间设置得更短(1s 以内)。但理论上会略微提升系统负载(未明显观察到)。
挂载硬盘时使用
data=writeback选项修改 journal 模式。但可能导致系统重启后文件包含已删除的内容。禁用 ext4 的 journal 特性。但可能会导致系统文件的不一致。
把 ext4 的 journal 日志迁移到更快的磁盘上,如 ssd、闪存等。操作复杂,不易维护。
使用 xfs、fat 等文件系统格式。特性不了解,影响不可知。
当然,对于这几种方案,我也做了压测,以下是压测的结果:

所以,程序员还是要懂些操作系统知识的,不仅帮我们在应对这种诡异的问题时不至于束手无策,也可以在做一些业务设计时能有所参考。
打印进程内核栈
前面我们查到是因为 journal 导致 write 系统调用被阻塞进而导致超时,但是总感觉证据还不够充分,没有一个完美的交待。
所以我们还需要继续追踪问题。
回到问题的原点,对于此问题,我能确定的资料只有稳定复现的环境和不知道什么时候会触发 write system call 延迟的 jar 包。
考虑到 write system call 被阻塞可长达几百 ms,我想我能抓出当前进程的内核栈来看一下 write system call 此时被阻塞在什么位置。
具体步骤为:
多个线程不便于抓内核栈,先将程序修改为单线程定量写入。
使用 jar 包启动一个进程,使用 ps 拿到进程号。
再通过
top -H -p pid拿到占用 cpu、内存等资源最多的线程 ID,或使用 strace 启动,查看其输出里正在写入的线程 ID。使用 watch 命令搭配 pstack 或
cat /proc/pid/stack不停打印进程内核栈。具体命令为watch -n 0.1 "date +%s >> stack.log;cat /proc/pid/stack >> stack.log"找到
write system call被阻塞时的时间戳,在stack.log里查看当时的进程内核栈。
可稳定收集到 write system call 被阻塞时,进程内核栈为:
[] call_rwsem_down_read_failed+0x14/0x30
[] ext4_da_get_block_prep+0x1a4/0x4b0 [ext4]
[] __block_write_begin+0x1a7/0x490
[] ext4_da_write_begin+0x15c/0x340 [ext4]
[] generic_file_buffered_write+0x11e/0x290
[] __generic_file_aio_write+0x1d5/0x3e0
[] generic_file_aio_write+0x5d/0xc0
[] ext4_file_write+0xb5/0x460 [ext4]
[] do_sync_write+0x8d/0xd0
[] vfs_write+0xbd/0x1e0
[] SyS_write+0x58/0xb0
[] system_call_fastpath+0x16/0x1b
[] 0xffffffffffffffff
内核栈分析
write system call 阻塞位置
通过内核栈函数关键字找到了 OenHan 大神的博客:读写信号量与实时进程阻塞挂死问题。
https://oenhan.com/rwsem-realtime-task-hung
这篇文章描述的问题虽然跟我遇到的问题不同,但进程内核栈的分析对我很有启发。为了便于分析内核函数,我 clone 了一份 linux 3.10.0 的源码,在本地查看。
搜索源码可以证实,栈顶的汇编函数 ENTRY call_rwsem_down_read_failed 会调用 rwsem_down_read_failed(), 而此函数会一直阻塞在获取 inode 的锁。
struct rw_semaphore __sched *rwsem_down_read_failed(struct rw_semaphore *sem) {
.....
/* wait to be given the lock */
while (true) {
set_task_state(tsk, TASK_UNINTERRUPTIBLE);
if (!waiter.task)
break;
schedule();
}
tsk->state = TASK_RUNNING;
return sem;
}
延迟分配
知道了 write system call 阻塞的位置,还要查它会什么会阻塞在这里。
这时,栈顶的函数名 call_rwsem_down_read_failed 让我觉得很奇怪,这不是 “write” system call 么,为什么会 down_read_failed?
直接搜索这个函数没有什么资料,但向栈底方向,再搜索其他函数就有了线索了,原来这是在做系统磁盘块的准备,于是就牵扯出了 ext4 的 delayed allocation 特性。
延迟分配(delayed allocation):ext4 文件系统在应用程序调用 write system call 时并不为缓存页面分配对应的物理磁盘块,当文件的缓存页面真正要被刷新至磁盘中时,才会为所有未分配物理磁盘块的页面缓存分配尽量连续的磁盘块。
这一特性,可以避免磁盘的碎片化,也可以避免存活时间极短文件的磁盘块分配,能很大提升系统文件 I/O 性能。
而在 write 向内存页时,就需要查询这些内存页是否已经分配了磁盘块,然后给未分配的脏页打上延迟分配的标签。
写入的详细过程可以查看 ext4 的延迟分配:
https://blog.csdn.net/kai_ding/article/details/9914629
此时需要获取此 inode 的读锁,若出现锁冲突,write system call 便会 hang 住。
在挂载磁盘时使用 -o nodelalloc 选项禁用掉延迟分配特性后再进行测试,发现 write system call 被阻塞的情况确实消失了,证明问题确定跟延迟分配有关。
不算结论的结论
寻找写锁
知道了 write system call 阻塞在获取读锁,那么一定是内核里有哪些地方持有了写锁。
ipcs 命令可以查看系统内核此时的进程间通信设施的状态,它打印的项目包括消息列表(-q)、共享内存(-m)和信号量(-q)的信息,用 ipcs -q 打印内核栈的函数查看 write system call 被阻塞时的信号量,却没有输出任何信息。
仔细想了一下发现其写锁 i_data_sem 是一把读写锁,而信号量是一种 非0即1 的PV量,虽然名字里带有 sem,可它并不是用信号量实现的。
perf lock 可以用来分析系统内核的锁信息,但要使用它需要重新编译内核,添加 CONFIG_LOCKDEP、CONFIG_LOCK_STAT 选项。先不说我们测试机的重启需要建提案等两天,编译完能不能启动得来我真的没有信心,第一次试图使用 perf 分析 linux 性能问题就这么折戟了。
转变方法
问题又卡住了,这时我也没有太多办法了,现在开始研究 linux 文件系统源码是来不及了,但我还可以问。
在 stackOverflow 上问没人理我:how metadata journal stalls write system call?,
https://stackoverflow.com/questions/52778498/how-metadata-journal-stalls-write-system-call
追着 OenHan 问了几次也没有什么结论:Linux内核写文件流程。
http://oenhan.com/linux-kernel-write#comment-201
虽然自己没法测试 upstream linux,还是在 kernel bugzilla 上发了个帖子:ext4 journal stalls write system call。
https://bugzilla.kernel.org/show_bug.cgi?id=201461
终于有内核大佬回复我:在 ext4_map_blocks() 函数中进行磁盘块分配时内核会持有写锁。
查看了源码里的函数详情,证实了这一结论:
/*
* The ext4_map_blocks() function tries to look up the requested blocks,
* and returns if the blocks are already mapped.
*
* Otherwise it takes the write lock of the i_data_sem and allocate blocks
* and store the allocated blocks in the result buffer head and mark it
* mapped.
*/
int ext4_map_blocks(handle_t *handle, struct inode *inode,
struct ext4_map_blocks *map, int flags)
{
.....
/*
* New blocks allocate and/or writing to uninitialized extent
* will possibly result in updating i_data, so we take
* the write lock of i_data_sem, and call get_blocks()
* with create == 1 flag.
*/
down_write((&EXT4_I(inode)->i_data_sem));
.....
}
但又是哪里引用了 ext4_map_blocks() 函数,长时间获取了写锁呢?
再追问时大佬已经颇有些无奈了,linux 3.10.0 的 release 已经是 5年 前了,当时肯定也有一堆 bug 和缺陷,到现在已经发生了很大变动,追查这个问题可能并没有很大的意义了,我只好识趣停止了。
推论
其实再向下查这个问题对我来说也没有太大意义了,缺少对源码理解的积累,再看太多的资料也没有什么收益。
就如向建筑师向小孩子讲建筑设计,知道窗子要朝南,大门要靠近电梯这些知识并无意义,不了解建筑设计的原则,只专注于一些自己可以推导出来的理论点,根本没办法吸收到其中精髓。
那么只好走到最后一步,根据查到的资料和测试现象对问题原因做出推论,虽然没有直接证据,但肯定跟这些因素有关。
在 ext4 文件系统下,默认为 ordered journal 模式,所以写 metadata journal 可能会迫使脏页刷盘, 而在 ext4 启用 delayed allocation 特性时,脏页可能在落盘时发现没有分配对应的磁盘块而分配磁盘块。在脏页太多的情况下,分配磁盘块慢时会持有 inode 的写锁时间过长,阻塞了 write 系统调用。
追求知识的每一步或多或少都有其中意义,查这个问题就迫使我读了很多外语文献,也了解了一部分文件系统设计思想。
linux 真的是博大精深啊。