
实例|使用图像分割进行物体缺陷检测

1. 介绍
什么是物体检测?
随着深度学习和计算机视觉的兴起,我们可以实现目标检测的自动化。我们可以建立深度学习和计算机视觉模型,可以检测和定位目标,计算它们之间的距离,预测它们的未来的位置等。目标检测在计算机视觉和机器学习中有着广泛的应用。目标跟踪、闭路电视监控、人类活动识别,甚至自动驾驶汽车都利用了这项技术。为了更好地理解它,考虑下面的图片。
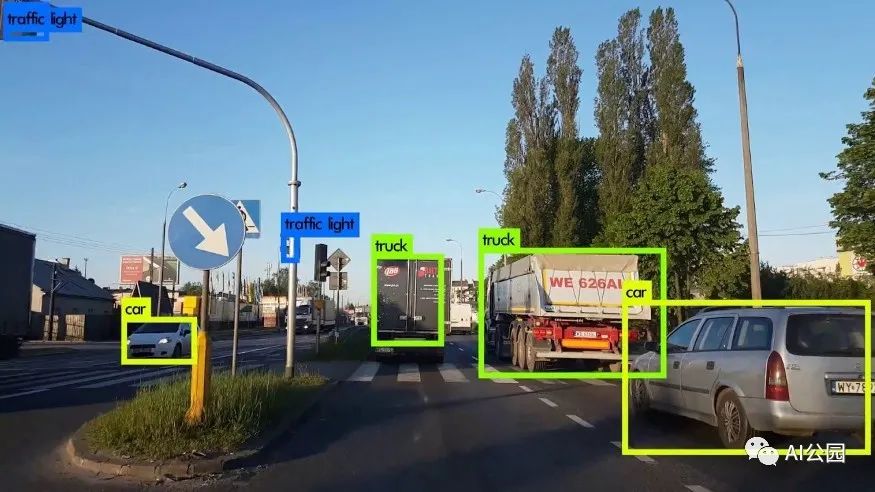
图中为一幅道路交通图像从车辆上看的目标检测。这里我们可以看到它正在检测其他车辆,交通信号等。如果车辆是自动驾驶汽车,应该能够检测到行驶路径、其他车辆、行人、交通信号等,以便平稳、安全驾驶。
现在我们已经了解了目标检测,让我们转移到一个稍微高级的技术,称为图像分割。通过分析下图,我们可以很容易地理解目标检测和图像分割之间的区别。

这两种方法都试图识别和定位图像中的物体。在目标检测中,这是通过边界框实现的。该算法或模型将通过在目标周围绘制一个矩形边界框来定位目标。在图像分割中,对图像中的每个像素进行标注。这意味着,给定一幅图像,分割模型试图通过将图像的所有像素分类成有意义的对象类别来进行像素级分类。这也被称为密集预测,因为它通过识别和理解每个像素属于什么对象来预测每个像素的含义。
“图像分割的返回格式称为掩码:一个与原始图像大小相同的图像,但对于每个像素,它只有一个布尔值指示目标是否存在。“
我们将在本案例研究中使用这种技术。现在我们有了目标检测和图像分割的概念。让我们进一步理解问题陈述。
2. 问题陈述
我们得到了一些产品的图像。有些产品有缺陷,有些没有。考虑到产品的图像,我们需要检测它是否有缺陷。我们还需要定位这个缺陷。
3. 机器学习的形式
这个问题可以表述为图像分割任务。给定一个产品的图像,我们需要为其绘制分割掩模。如果产品有缺陷,分割图应该能够定位该缺陷。
4. 性能度量
在分割问题中最常用的指标之一是(IoU分数。参考下面的图像,这清楚地显示了如何IoU分数是计算的。

我们也可以把IoU分数写成TP/TP+FN+FP。
这个度量值的范围是0到1。Iou得分为1表示完全重叠,Iou得分为0表示完全不重叠。
本案例研究中使用的损失函数是Dice损失。Dice 损失可以被认为是1-Dice 系数,其中Dice 系数定义为,
Dice系数 = 2 * 相交的重叠面积
5. 理解数据
该数据集包含两个文件夹 —— train和test。训练集由六类图像组成。每一类图像被分成两个文件夹,其中一个文件夹包含1000张无缺陷图像,另一个文件夹包含130张有缺陷图像。下图显示了train文件夹中的文件夹。
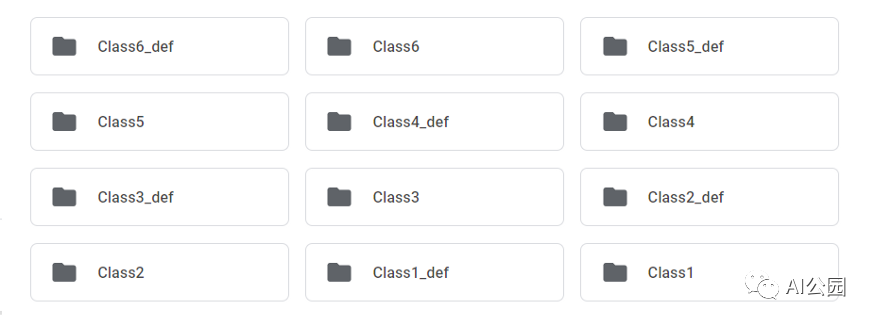
以 “def”结尾的文件夹名称包含相应类的有缺陷的图像,没有“def”的则表示无缺陷的图像。测试文件夹包含一组120个有缺陷的图像,这些图像的分割图将被预测。
6. 数据预处理
6.1 准备图像数据和分割蒙版
现在我们需要为每个图像准备图像数据和相应的分割掩模。我们把图片分成十二个文件夹。让我们来看一些图片。


第一幅图像表示有缺陷的产品,第二幅图像表示无缺陷的图像。现在我们需要为这些图像准备分割图。分割图可以检测出图像中有缺陷的部分。对于上面的图像,预期的分割图是这样的。


我们可以看到,在第一幅图像中,椭圆区域代表检测部分。第二幅图像是空白的,因为它没有缺陷。
让我们再分析一些有缺陷的图像。




我们可以看到缺陷在图像中以曲线或直线的形式出现。因此,我们可以利用椭圆来将这些区域标记为缺陷。
但我们如何准备分割掩码?是否需要手工标注?
我们有另一个包含关于分割掩码信息的文件。
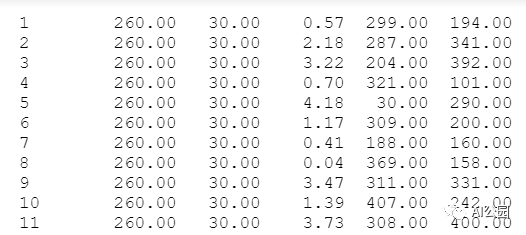
每一行包含关于图像的mask区域的信息。每一列表示图像的文件名、椭圆的半长轴、椭圆的半短轴、椭圆的旋转角度、椭球中心的x位置、椭球中心的y位置。
绘制椭圆所需的数据是使用get_data函数获得的,如下所示:

我们可以使用这些信息,并使用skimage函数绘制一个椭圆分割蒙版。
值得注意的是,这只适用于有缺陷的图像。对于无缺陷的图像,我们需要创建空白图像作为分割掩模。
6.2 加载图像
结构化数据以如下所示的形式获得。

“images”列包含每个图像的完整文件路径,“mask”列包含相应的掩码图像。
下一步是加载数据。

7. 模型
现在我们得到了所有的数据,下一步是找到一个模型,可以生成图像的分割mask。让我来介绍一下UNet模型,它在图像分割任务中非常流行。
UNet架构包含两种路径:收缩路径和扩展路径。下图可以更好地理解Unet架构。
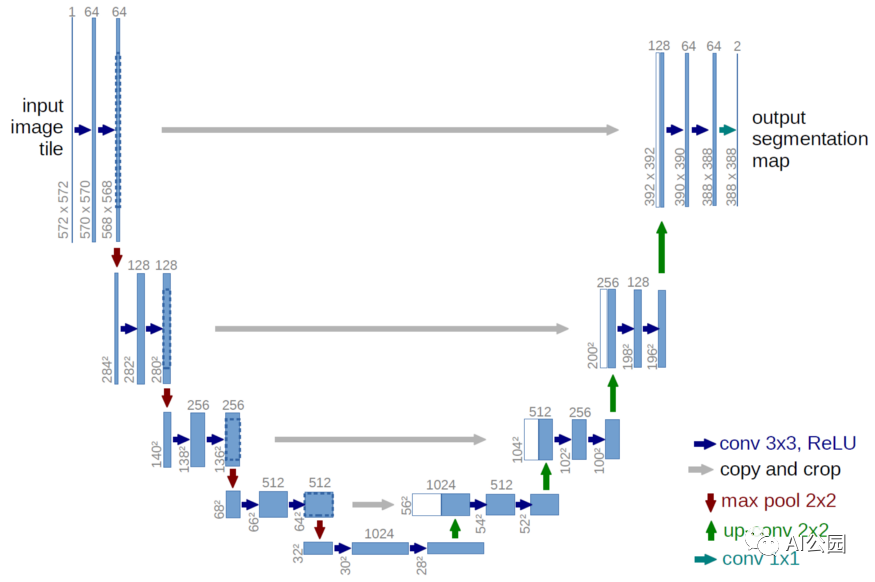
模型结构类似于英文字母“U”,因此得名Unet。模型的左侧包含收缩路径(也称为编码器),它有助于捕获图像中的上下文。该编码器只是一个传统的卷积和最大池层堆栈。在这里我们可以看到,池化层降低了图像的高度和宽度,增加了通道的深度和数量。在收缩路径的末端,模型将理解图像中出现的形状、模式、边缘等,但它丢失了“在哪里”出现的信息。
由于我们的问题是获取图像的分割映射,我们从压缩路径中获得的信息是不够的。我们需要一个高分辨率的图像作为输出,其中所有像素都是分类的。
”如果我们使用一个规则的卷积网络,pooling层和dense层,我们会丢失WHERE信息,只保留不是我们想要的“WHAT”信息。在分割的情况下,我们既需要“WHAT”信息,也需要“WHERE”信息
所以我们需要对图像进行上采样,以保留“where”信息。这是在右边的扩张路径中完成的。扩展路径(也称为解码器)用于使用上采样技术定位捕获的上下文。上采样技术有双线性插值法、最近邻法、转置卷积法等。、
8. 训练
现在我们已经准备好了所有的训练数据,也确定了模型。现在让我们训练模型。
由于无缺陷图像的数量远远高于有缺陷图像的数量,所以我们只从无缺陷图像中提取一个样本,以获得更好的结果。采用adam优化器训练模型,并以dice 损失为损失函数。
使用的性能指标是iou分数。

经过10个epoch,我们能够获得0.98的iou分数和0.007的骰子损失,这是相当不错的。让我们看一些图像的分割图。
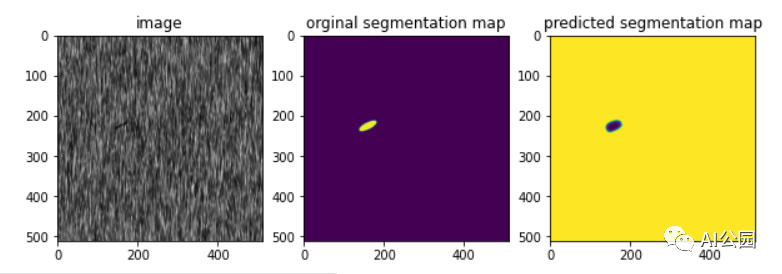

我们可以看到,该模型能够预测类似于原始分割图的分割图。
9. 测试数据分割图的预测
现在让我们尝试解决手边的问题,即预测和绘制测试图像的分割蒙版。下图显示了一些测试图像的预测分割图。
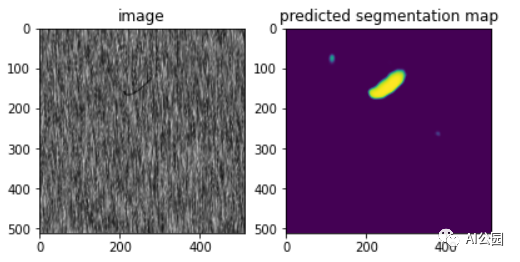
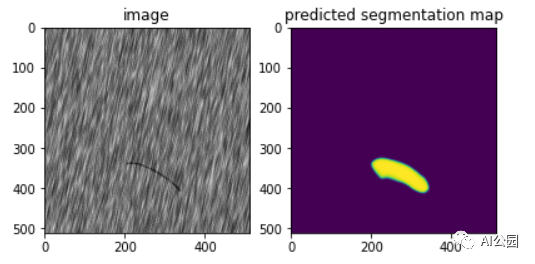

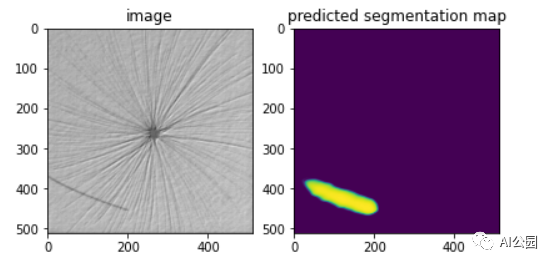
可以看出,该模型具有良好的测试性能,能够检测出测试图像中的缺陷。
10. 未来的工作
如上所述,与无缺陷图像相比,有缺陷图像的数量非常少。因此,对缺陷图像采用上采样和增强技术可以改善训练效果。
英文原文:https://medium.com/analytics-vidhya/defect-detection-in-products-using-image-segmentation-a87a8863a9e5
✄------------------------------------------------
双一流大学研究生团队创建,专注于目标检测与深度学习,希望可以将分享变成一种习惯。
整理不易,点赞三连!