
极限挑战:使用 Go 打造百亿级文件系统的实践之旅
JuiceFS 企业版是一款为云环境设计的分布式文件系统,单命名空间内可稳定管理高达百亿级数量的文件。
构建这个大规模、高性能的文件系统面临众多复杂性挑战,其中最为关键的环节之一就是元数据引擎的设计。JuiceFS 企业版于 2017 年上线,经过几年的不断迭代和优化,在单个元数据服务进程使用 30 GiB 内存的情况下,能够管理约 3 亿个文件,并将元数据请求的平均处理时间维持在 100 微秒量级。在当前线上某个生产集群中,包含了十个拥有 512 GB 内存的元数据节点,它们共同管理着超过 200 亿个文件。
为了实现极致的性能,JuiceFS 元数据引擎采用的是全内存方案,并通过不断的优化来减小文件元数据的内存占用。目前,在管理相同文件数的情况下,JuiceFS 所需内存大概只有 HDFS NameNode 的 27%,或者 CephFS MDS 的 3.7 %。这种极高的内存效率,意味着在相同的硬件资源下,JuiceFS 能够处理更多的文件和更复杂的操作,从而实现更高的整体系统性能。
本文将详细介绍我们在元数据引擎方面进行的各项探索和优化措施,希望这能让 JuiceFS 用户对其有更多的了解,在应对极限场景时能有更强的信心。同时我们也希望它能抛砖引玉,为设计大规模系统的同行提供有价值的参考。
一、JuiceFS 简介
JuiceFS 主要分为三大组件:
-
• 客户端:它是与业务交互的接入层。JuiceFS 支持多种协议,包括 POSIX、Java SDK、Kerbenetes CSI Driver 和 S3 Gateway 等。
-
• 元数据引擎:负责维护文件系统的目录树结构,以及各个文件的属性等。
-
• 数据存储:负责存储普通文件的具体内容,通常由亚马逊 S3、阿里云 OSS 等对象存储担任。
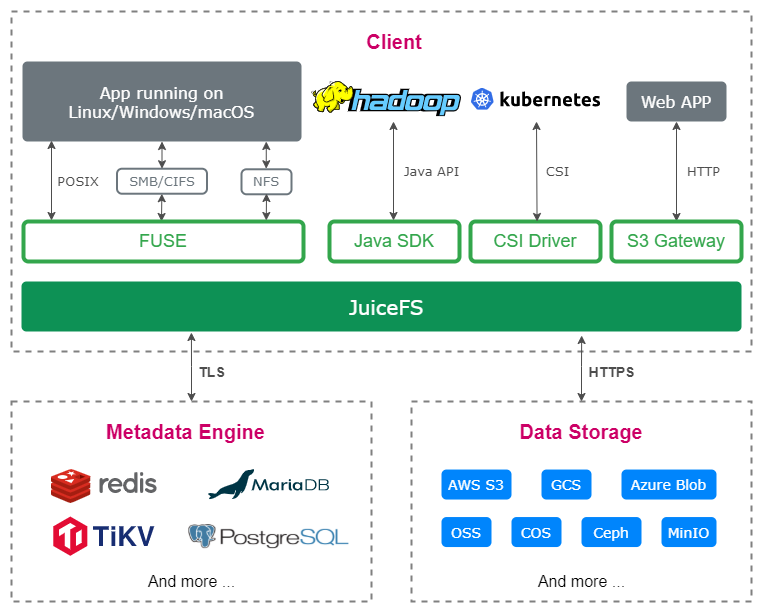
JuiceFS 架构图
目前 JuiceFS 拥有社区版和企业版两个版本,它们的架构基本一致,主要区别在于元数据引擎的实现。社区版的元数据引擎一般使用现有的数据库服务(如架构图中所示),如 Redis、MySQL、TiKV 等;而企业版则使用一个自主研发的元数据引擎。这个引擎能在更低资源消耗的情况下提供更高的性能,同时也能额外支持一些企业级需求。下文将介绍我们在研发这款元数据引擎过程中的思考与实践。
二、元数据引擎设计
2.1 使用 Go 作为开发语言
底层系统级软件的开发通常以 C/C++ 为主,而 JuiceFS 选择了 Go 作为开发语言,这主要是考虑到:
-
1. 开发效率更高:Go 语法相较 C 语言更为简洁,表达能力更强;同时 Go 自带内存管理功能,以及如 pprof 等强大的工具链。
-
2. 程序执行性能出色:Go 本身也是一门编译型语言,编写的程序性能在绝大部分情况下并不逊色于 C 程序。
-
3. 程序可移植性更佳:Go 对静态编译支持的更好,更容易让程序在不同操作系统上直接运行。
-
4. 支持多语言 SDK:借助原生的 cgo 工具 Go 代码也能编译成共享库文件(.so 文件),方便其他语言加载。
当然,Go 语言在带来便利的同时,也隐藏了一些底层细节,一定程度上会影响程序对硬件资源的使用效率(尤其是 GC 对内存的管理),因此在性能关键处我们需要进行针对性优化。
2.2 性能提升策略:全内存,无锁服务
要提升性能,我们首先需要理解元数据引擎在分布式文件系统中的核心职责。通常来说,它主要承担以下两项关键任务:
-
1. 管理海量文件的元数据
要完成这项任务常见的有两种设计方案。一种是将所有文件的元数据都加载到内存中,如 HDFS 的 NameNode,这样能提供很好的性能,但势必需要大量的内存资源。另一种是仅缓存部分元数据在内存,如 CephFS 的 MDS。当请求的元数据不在缓存中时,MDS 需要暂存该请求,并通过网络从硬盘(元数据池)中读取相应内容,解析后再进行重试。显然,这很容易产生时延尖刺,影响业务体验。因此,在实践中为了满足业务的低时延访问需要,通常会尽量调高 MDS 内存限制来缓存更多的文件,甚至全部文件。
JuiceFS 企业版追求极致性能,因此采用的是第一种全内存方案,并通过不断的优化来减小文件元数据的内存占用。全内存模式通常会使用实时落盘的事务日志来保证数据的可靠性,JuiceFS 还使用了 Raft 共识算法来实现元数据的多机复制和自动故障切换。
-
2. 快速处理元数据请求
元数据引擎的关键性能指标是每秒能处理的请求数量。通常,元数据请求需要保证事务性,并涉及多个数据结构,由多线程并发处理时一般需要复杂的锁机制以确保数据一致性和安全性。当事务的冲突比较多时,多线程并不能有效提升吞吐量,反而会因为太多的锁操作导致延迟增加,这个现象在高并发场景中尤其明显。
JuiceFS 采用了一种不同的方法,即类似于 Redis 的无锁模式。在这种模式下,所有核心数据结构的相关操作都在单个线程中执行。这种单线程方法不仅保证了每个操作的原子性(避免了操作被其他线程打断的问题),还减少了线程间的上下文切换和资源竞争,从而提高了系统的整体效率。同时,它大大降低了系统复杂度,提升了稳定性和可维护性。得益于全内存的元数据存储模式,请求都可以被非常高效地处理,CPU 不容易成为瓶颈。
2.3 多分区水平扩展
单个元数据服务进程可用的内存是有上限的,而且单进程内存过高时也会逐渐出现效率下降的情况。JuiceFS 会通过聚合分布在多个节点的虚拟分区中的元数据来实现水平扩展,以支撑更大的数据规模和更高的性能需求。
具体来说,每个分区各自负责文件系统中的一部分子树,由客户端来协调和管理多个分区中的文件,把它们组装成单一的命名空间;同时这些文件能够在多个分区间根据需要进行动态迁移。例如,一个管理超过 200 亿文件的集群,就使用了 10 个 512 GB 内存的元数据节点,部署了 80 个分区。一般情况下,我们建议将单个元数据服务进程的内存控制在 40 GiB 以内,并通过多分区水平扩展的方式来管理更多的文件。
文件系统的访问通常有很强的局部性,换言之文件一般在同一个目录或者相邻的目录间移动。因此 JuiceFS 实现的动态子树拆分方式中会尽量维持较大的子树,使得绝大部分元数据操作都发生在单一的分区中。这样的好处是能大幅减少分布式事务的使用,使得集群在大规模扩展后仍然能保持跟单分区接近的元数据响应延迟。
三、内存优化
随着数据量的增加,元数据服务需要的内存也随之增加,这不仅会影响系统的性能,同时也会让硬件成本快速上升。因此,在海量文件场景中,减少元数据的内存占用对于维持系统稳定和控制成本是非常关键的。
为了实现这一目标,我们在内存分配和使用上进行了广泛的探索和尝试。接下来,我们将分享一些经过多年迭代和优化,被证明为有效的措施。
3.1 使用内存池来减少分配
这是在 Go 程序中非常常见的优化手段,主要是借助标准库中的 sync.Pool 结构。其基本原理是,用完的数据结构不丢弃,而是将它放回到一个池中。当再次需要使用相同类型的数据结构时,可以直接从池中获取,而不需要申请。这种方法可以有效减少内存申请和释放的次数,从而提高性能。这里有个简单的例子:
pool := sync.Pool{
New: func() interface{} {
buf := make([]byte, 1<<17)
return &buf
},
}
buf := pool.Get().(*[]byte)
// do some work
pool.Put(buf)
在初始化时,通常需要定义一个 New 函数来创建新的结构体。使用时,首先通过 Get 方法获取对象,并转换为相应类型;使用完毕后,通过 Put 方法将结构体放回池中。值得注意的是,放回去后这个结构体仅有弱引用,也就是说它随时可能被垃圾回收机制(GC)回收。
示例中的结构体是一段预定长度的内存切片,因此我们得到的其实是一个简单的内存池。这个池结合下一小节的精细管理手段,就能实现程序对内存的高效使用。
3.2 自主管理小块内存分配
在 JuiceFS 元数据引擎中,最关键部分就是要维护目录树结构,大致如下:
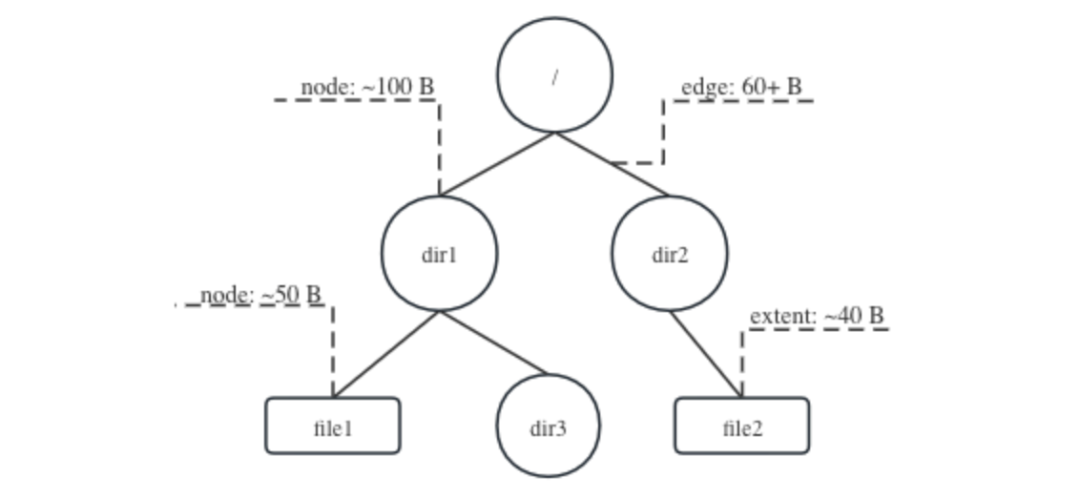 目录树结构示意图
目录树结构示意图
其中:
-
• 节点(node)记录了每个文件或目录的属性,一般占用 50 到 100 字节
-
• 边(edge)描述父子节点间的联系,一般占用 60 到 70 字节
-
• 数据块(extent)则记录数据所在的位置,一般占用约 40 字节
可见这些结构体都非常小,但是数量会非常庞大。Go 的 GC 不支持分代,也就是说如果将它们都交由 GC 来管理,就需要在每次进行内存回收时都将它们扫描一遍,并且标记所有被引用的对象。这个过程会非常慢,不仅使得内存无法及时回收,还可能消耗过多的 CPU 资源。
为了能够高效地管理这些海量小对象,我们使用 unsafe 指针(包括 uintptr)来绕过 Go 的 GC 进行手动内存分配和管理。实现时,元数据引擎每次向系统申请大块的内存,然后根据对象的大小拆分成相同尺寸的小块来使用。在保存指向这些手动分配的内存块的指针时,尽量使用 unsafe.Pointer 甚至 uintptr 类型,这样 GC 就不需要扫描这些指针,也就大幅减轻了其在执行内存回收时的工作量。
具体而言,我们设计了一个名为 Arena 的元数据内存池,其中包含有多个不同的桶,用来隔离大小差异较大的结构体。每个桶存放的是较大的内存块,例如 32 KiB 或 128 KiB 。需要使用元数据结构体时,通过 Arena 接口找到相应的桶,并从其中的内存块划分一小段来使用;使用完毕后,同样通知 Arena 将其放回内存池。它的设计示意图如下:
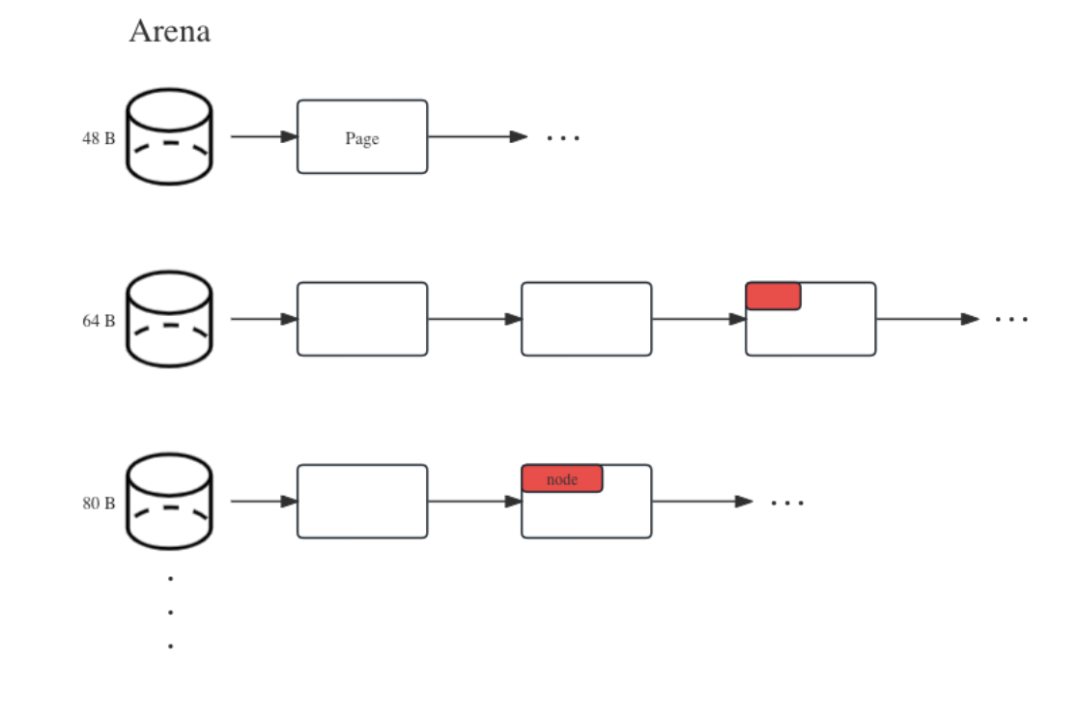 JuiceFS 元数据内存池 Arena 示意图
JuiceFS 元数据内存池 Arena 示意图
具体的管理细节较为复杂,感兴趣的读者可以了解更多关于 tcmalloc 和 jemalloc 等内存分配器的实现原理,基本思路与它们类似。以下介绍 Arena 中的关键代码:
// 内存块常驻
var slabs = make(map[uintptr][]byte)
p := pagePool.Get().(*[]byte) // 128 KiB
ptr := unsafe.Pointer(&(*p)[0])
slabs[uintptr(ptr)] = *p
其中 slabs 是一个全局的 map,它记录了 Arena 里所有被申请的内存块,这样 GC 就能知道这些大内存块正在被使用。下面一段是结构体创建的代码:
func (a *arena) Alloc(size int) unsafe.Pointer {...}
size := nodeSizes[type]
n := (*node)(nodeArena.Alloc(size))
// var nodeMap map[uint32, uintptr]
nodeMap[n.id] = uintptr(unsafe.Pointer(n)))
其中 Arena 的 Alloc 函数用于申请指定大小的内存,并返回一个 unsafe.Pointer 指针。创建一个 node 时,我们先确定其类型所需的大小,然后将申请到的指针转换为所需结构体类型,即可正常使用。必要时,我们会将这个 unsafe.Pointer 转成 uintptr 保存在 nodeMap 中。这是一个非常大的映射(map),用来根据 node ID 快速找到对应的结构体。
在这种设计下,从 GC 角度看,会发现程序申请了许多 128 KiB 的内存块,且一直在使用,但里面具体的内容显然不需要它来操心。另外,虽然 nodeMap 中含有数亿甚至数十亿元素,但其键值均为数值类型,因此 GC 并不需要扫描每一个键值对。这种设计对 GC 非常友好,即使上百 GiB 的内存也能轻松完成扫描。
3.3 压缩空闲目录
在 2.3 节中提到过,文件系统的访问具有很强的局部性,应用程序在一段时间内通常只会频繁访问几个特定的目录,而其他部分则相对闲置,全局随机访问的情况较少。基于此,我们可以将不活跃的目录元数据进行压缩,从而达到减少内存占用的效果。如下图所示:
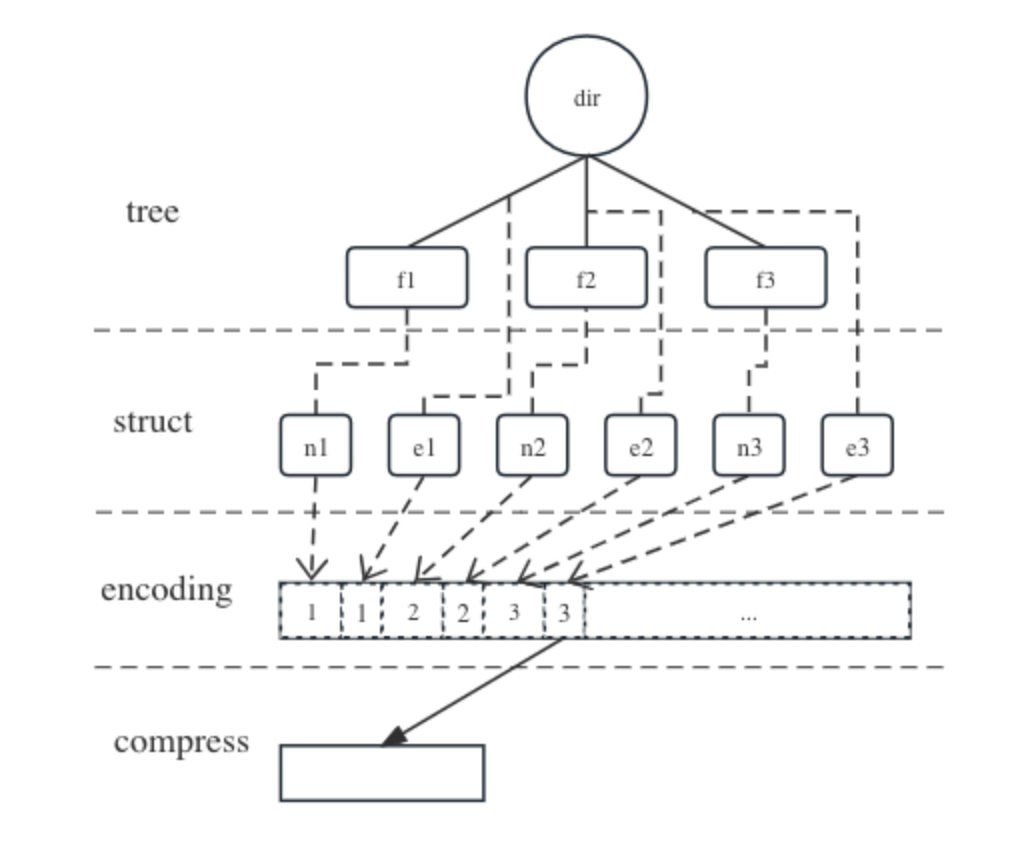 JuiceFS 目录序列化和压缩示意图
JuiceFS 目录序列化和压缩示意图
当目录 dir 处于空闲状态时,可以将它和它下面所有一级子项的元数据按预定格式紧凑地序列化,得到一段连续的内存缓冲区;然后再将这段缓冲区进行压缩,变成一段更小的内存。
通常情况下,将多个结构体一起序列化后能节省近一半的内存,而压缩处理则能进一步节省大约一半到三分之二的内存。因此,这种方法大幅降低了单个文件元数据的平均占用。然而,序列化和压缩过程会占用一定的 CPU 资源,并可能增加请求的延迟。为了平衡效率,我们在程序内部监控 CPU 状态,仅在 CPU 有闲余时触发此流程,并将每次处理的文件数限制在 1000 以内,以保证其快速完成。
3.4 为小文件设计更紧凑的格式
为了支持高效的随机读写,JuiceFS 中普通文件的元数据会分为三个层级来进行索引:fnode 、chunks 和 slice,其中 chunks 是一个数组,slice 则放在一个哈希表中。初始设计时,每个文件都需要分配这 3 块内存,但后来我们发现这种方式对绝大部分小文件而言并不够高效。因为小文件通常只有一个 chunk,这个 chunk 也只有一个 slice,而且 slice 的长度跟文件的长度是一致的。
因此,我们为这类小文件引入了一个更紧凑高效的内存格式。在新的格式中,我们只需要记录 slice 的 ID,再从文件的长度得到 slice 的长度,无须存储 slice 本身。同时,我们调整了 fnode 的结构。原来 fnode 中保存了指向 chunks 数组的指针,而它指向的数组中只有一个 8 字节的 slice ID,现在我们直接将这个 ID 保存在了指针变量的位置。这种用法类似 C 语言里的 union 结构,即在同一内存位置根据实际情况存储不同类型的数据。经此调整后,每个小文件就只有一个 fnode 对象,而无需其他 chunk 列表和 slices 信息。具体示意图如下:
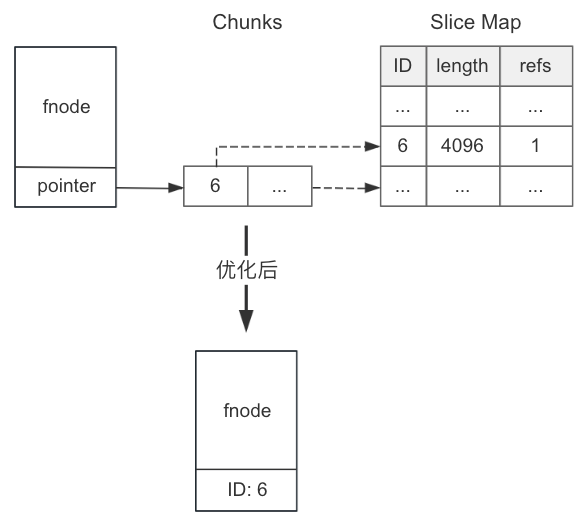
小文件优化示意图
优化后的格式可以为每个小文件节省约 40 字节内存。同时,这也减少了内存的分配和索引操作,访问起来会更快。
3.5 整体优化效果
下图总结了到目前为止的优化成果:
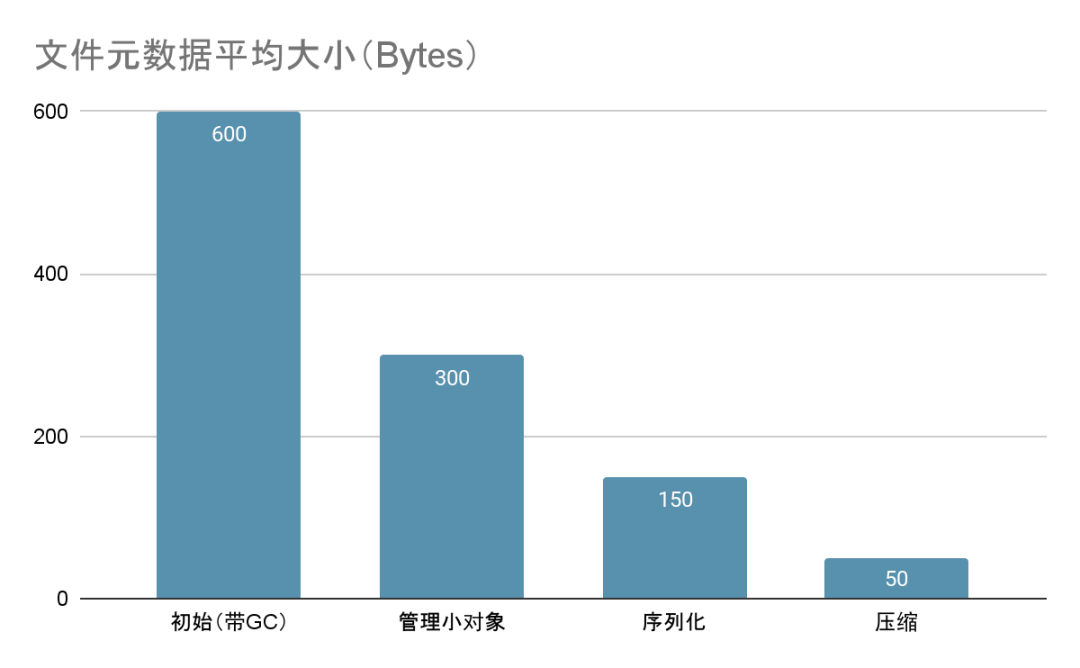
在图中,文件的平均元数据大小呈现显著下降。最初,每个文件的元数据平均占用近 600字节。通过自行管理内存,这一数字降至大约 300 字节,并大幅缩减了 GC 的开销。随后,对空闲目录进行序列化处理,进一步将其减少到约 150 字节。最后,通过内存压缩技术,平均大小降低到了大约 50 字节。当然,元数据服务在运行时还需要负责状态监控、会话管理等任务,并应对网络传输等各种临时消耗,实际的内存占用量可能达到这个核心值的两倍,因此我们一般按每个文件 100 字节来预估所需的硬件资源。
常见分布式文件系统的单文件内存占用情况如下:
-
• HDFS:370 字节(数据来源:网络文章[1])
-
• CephFS:2700 字节(数据来源:Nautilus 版本集群监控 - 32G 内存 1200万文件)
-
• Alluxio (Heap模式):2100 字节(数据来源:官方文档[2] - 64G 内存 3000万文件)
-
• JuiceFS 社区版 Redis 引擎:430 字节(数据来源:官方文档[3])
-
• JuiceFS 企业版:100 字节(数据来源:线上集群监控 - 30G 内存 3亿文件)
可以看到,JuiceFS 在元数据内存占用方面的表现非常突出,仅为 HDFS NameNode 的 27%,CephFS MDS 的 3.7 %。它不仅意味着更高的内存效率,也意味着在相同的硬件资源下,JuiceFS 能够处理更多的文件和更复杂的操作,从而提高整体系统性能。
四、小结
文件系统的核心之一在于其元数据的管理,而当构建一款能够处理百亿文件数规模的分布式文件系统时,这一设计任务变得尤为复杂。本文介绍了 JuiceFS 在设计元数据引擎时所做的关键决策,并详细介绍了内存池、自主管理小块内存、压缩空闲目录以及优化小文件格式这 4 个内存优化手段。这些措施是我们在不断探索、尝试和迭代的过程中得出的成果,最终使 JuiceFS 的文件元数据平均内存占用下降至 100 字节,令其更能够应对更多更极限的使用场景。
关于作者
 负责豆瓣数据平台的功能开发和维护直播回顾 :https://www.bilibili.com/video/BV1wX4y1X7em/直播回顾:https://www.bilibili.com/video/BV1wX4y1X7em/直播回顾:https://www.bilibili.com/video/BV1wX4y1X7em/直播回顾:https://www.bilibili.com/video/BV1wX4y1X7em/
负责豆瓣数据平台的功能开发和维护直播回顾 :https://www.bilibili.com/video/BV1wX4y1X7em/直播回顾:https://www.bilibili.com/video/BV1wX4y1X7em/直播回顾:https://www.bilibili.com/video/BV1wX4y1X7em/直播回顾:https://www.bilibili.com/video/BV1wX4y1X7em/
Sandy
JuiceFS 核心系统工程师
引用链接
[1] 网络文章: https://blog.csdn.net/lingbo229/article/details/81079769[2] 官方文档: https://docs.alluxio.io/ee-da/user/stable/en/operation/Metastore.html[3] 官方文档: https://juicefs.com/docs/zh/community/redis_best_practices
推荐阅读:
想要了解Go更多内容,欢迎扫描下方👇关注公众号, 回复关键词 [实战群] ,就有机会进群和我们进行交流
分享、在看与点赞Go