
我用Redis实现了一个轻量级的搜索引擎!

阅读本文大概需要 4.5 分钟。

大家如果是做后端开发的,想必都实现过列表查询的接口,当然有的查询条件很简单,一条 SQL 就搞定了。

实现 1
select ... from table_1
left join table_2
left join table_3
left join (select ... from table_x where ...) tmp_1
...
where ...
order by ...
limit m,n
实现 2
$result_1 = query('select ... from table_1 where ...');
$result_2 = query('select ... from table_2 where ...');
$result_3 = query('select ... from table_3 where ...');
...
$result = array_intersect($result_1, $result_2, $result_3, ...);
实现 3

子类单选:直接根据条件 Key,获取对应结果集。
子类多选:根据多个条件 Key,进行并集操作,获取对应结果集。
最终结果:将获取的所有子类结果集进行交集操作,得到最终结果。
扩展
①分页
这里你或许发现了一个严重的功能缺陷,列表查询怎么能没有分页。是的,我们马上来看 Redis 是如何实现分页的。
分页主要涉及排序,这里简单起见,就以创建时间为例。如图所示:
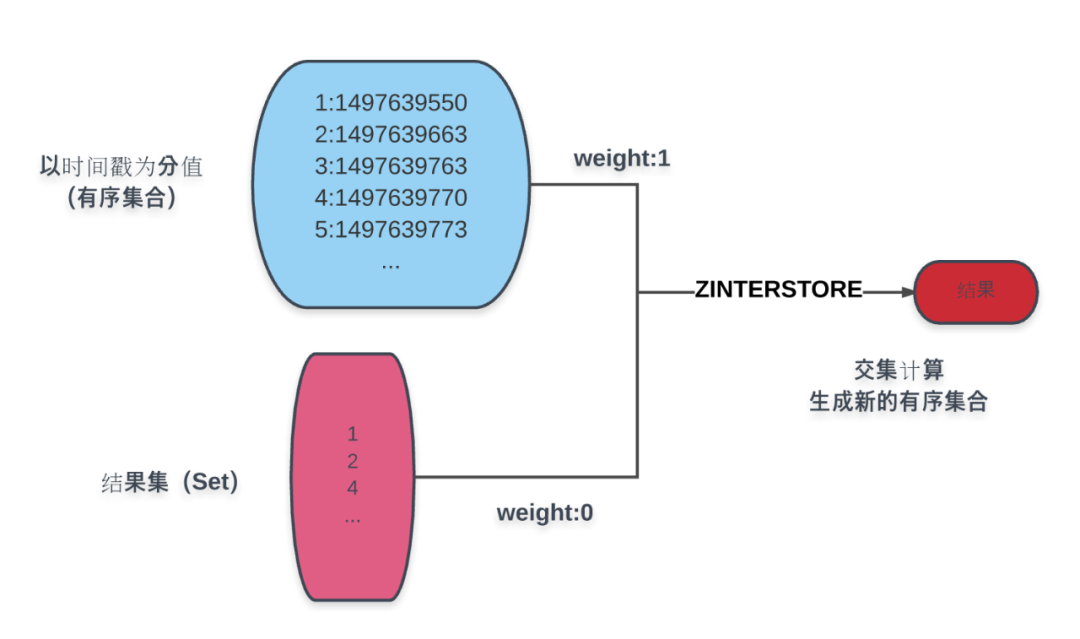
图中蓝色部分是以创建时间为分值的商品有序集合,蓝色下方的结果集即为条件计算而得的结果,通过 ZINTERSTORE 命令,赋结果集权重为 0,商品时间结果为 1,取交集而得的结果集赋予创建时间分值的新有序集合。
对新结果集的操作即能得到分页所需的各个数据:
页面总数为:ZCOUNT 命令。
当前页内容:ZRANGE 命令。
若以倒序排列:ZREVRANGE命令。
②数据更新
关于索引数据更新的问题,有两种方式来进行。一种是通过商品数据的修改,来即时触发更新操作,一种是通过定时脚本来进行批量更新。
这里要注意的是,关于索引内容的更新,如果暴力的删除 Key,再重新设置 Key。
因为 Redis 中两个操作不会是原子性进行的,所以中间可能存在空白间隙,建议采用仅移除集合中失效元素,添加新元素的方式进行。
③性能优化
Redis 是内存级操作,所以单次的查询会很快。但是如果我们的实现中会进行多次的 Redis 操作,Redis 的多次连接时间可能是不必要时间消耗。
通过使用 MULTI 命令,开启一个事务,将 Redis 的多次操作放在一个事务中,最后通过 EXEC 来进行原子性执行。
注意:这里所谓的事务,只是将多个操作在一次连接中执行,如果执行过程中遇到失败,是不会回滚的。
总结
这里只是一个采用 Redis 优化查询搜索的一个简单 Demo,和现有的开源搜索引擎相比,它更轻量,学习成本页相应低些。
其次,它的一些思想与开源搜索引擎是类似的,如果再加上词语解析,也可以实现类似全文检索的功能。
<END>
扫码加入技术交流群,不定时「送书」
推荐阅读:
内容包含Java基础、JavaWeb、MySQL性能优化、JVM、锁、百万并发、消息队列、高性能缓存、反射、Spring全家桶原理、微服务、Zookeeper、数据结构、限流熔断降级......等技术栈!
⬇戳阅读原文领取! 朕已阅 
评论