
持续集成和交付流水线的8个反模式 | IDCF

来源:Thoughtworks洞见 作者:冯炜 原文发表:原文发表于:https://www.rea-group.com/blog/continuous-integration-and-delivery-pipeline-mistakes/
一、CI/CD & Pipeline

随着DevOps的理念在众多公司的采纳,CI/CD也渐渐落地。
CI(Continuous Integration)持续集成,是把代码变更自动集成到主干的一种实践。CI的出现解决了集成地狱的问题,让产品可以快速迭代,同时还能保持高质量。它的核心措施是,代码集成到主干之前,必须通过一系列自动化测试,比如编译、单元测试、lint、代码风格检查。 CD包括持续交付和持续部署。持续交付(Continuous Delivery)指的是团队自动地、频繁地、可预测地交付高质量软件版本的过程,可以看做持续集成的下一个阶段,强调的是无论代码怎么更新,软件都是随时可以交付的;持续部署(continuous deployment)更强调的是使用自动化测试来保证变更的正确性和稳定性,以便在测试通过后立即部署,是持续交付的更进一步。二者的区别是,持续交付需要人为介入,需要确保可以部署到生产环境时,才去进行部署。
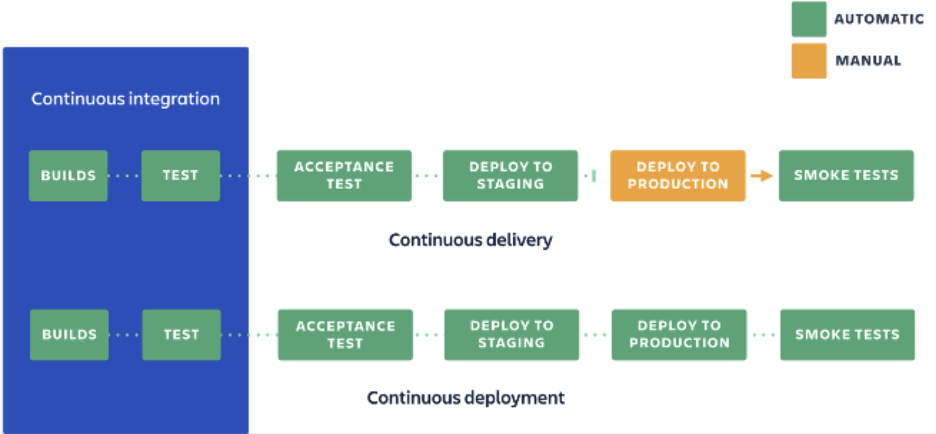
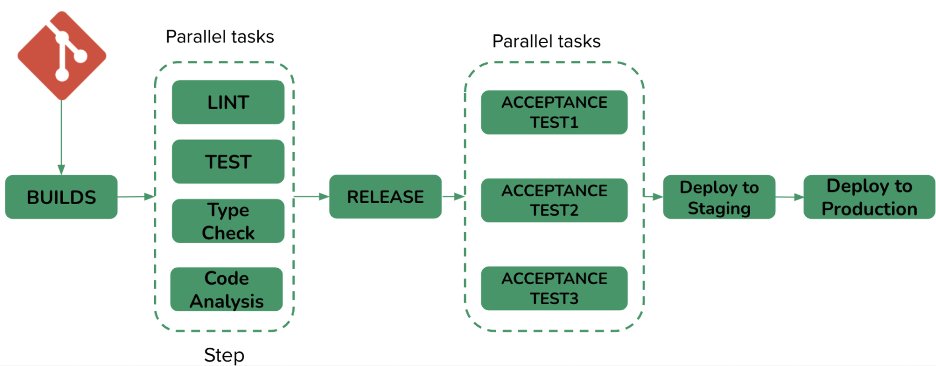
二、CI/CD Pipeline的反模式
该并行的任务没有并行执行,等待的任务拉长了执行时间; 执行Pipeline的agent节点太少,或者性能不足,导致排队时间太长,效率太低; 执行的任务太重,相同测试场景被不同的测试覆盖了很多次。比如同样的逻辑在不同测试中都测了一遍; 没有合理利用缓存,比如每个任务里都要下载全部依赖,在构建Dockerfile时没有合理利用layer,每次都会构建一个全新的image。
检查Pipeline的设计是否合理,尽可能让任务并行; 对代码的各种测试深入了解,让测试尽量正交,避免过多的重复; 检查代码中的依赖,合理利用好缓存。包括Docker Image、Gradle、Yarn、Rubygem的缓存,以及Dockerfile是否合理的设计,最大化的将不可变的layer集中的开始阶段; 检查执行构建的节点资源是否充足,能否在任务量大时做弹性伸缩,减少等待和执行时间。

提升测试的稳定性,比如用mock替代不稳定的源。 采用Pipeline的重试功能,或者采用稳定的镜像源,或者提前构建好基础镜像。 引入Pipeline的插件保证任务不会并行执行。

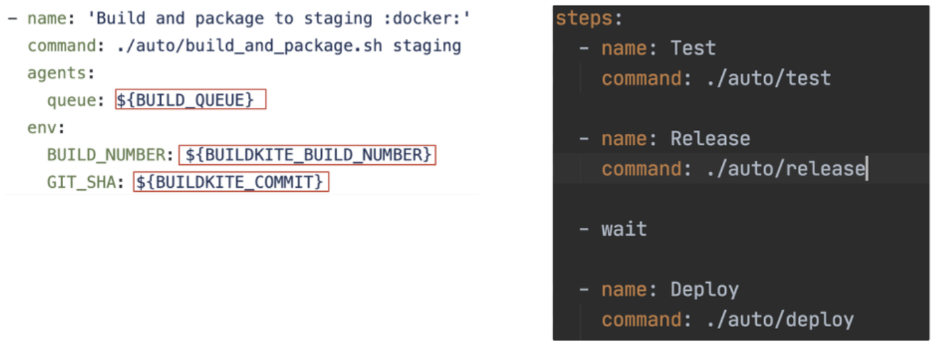
Pipeline的定义跟构建工具紧密耦合,包含了Pipeline工具特有的参数以及CLI命令。比如在配置中使用BUILDKITE_BUILD_NUMBER,BUILDKITE_QUEUE等等。结果就是本地运行的方式或结果和Pipeline上运行的方式以及结果不一致。 在Pipeline的任务中写了一大段脚本,或者直接使用命令加上一堆参数,以至于在本地想跑测试需要在Pipeline的配置中找命令并且在本地粘贴。 不做环境隔离, 测试,编译,部署等都依赖于运行时环境。可能出现Pipeline 因依赖的软件/库等版本不一致而导致的不一致的情况,通常还很难排查。
最后


评论