
面试官:Redis存储结构体信息是用hash还是string?
共 2495字,需浏览 5分钟
·
2021-11-08 11:17
你知道的越多,不知道的就越多,业余的像一棵小草!
你来,我们一起精进!你不来,我和你的竞争对手一起精进!
编辑:业余草
blog.csdn.net/u010145219
推荐:https://www.xttblog.com/?p=5290
现在的程序员,已经越来越离不开 Redis 了。那么在使用 Redis 过程中,我需要存储一个结构体,我应该是选择使用 hash 呢?还是字符串?大家可以线思考思考再往下阅读本文。
在讲到使用 hash 还是 string 存储的选择前,先了解 Redis 的 hash 和 string 结构。
首先,string 和 hash 都是 Redis 的一种数据结构。string 结构常用来缓存用户信息,通常将用户信息结构体使用 JSON 序列化成字符串,然后将序列化后的字符串存入 Redis 进行缓存。
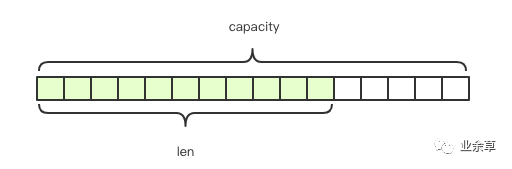
String 数据结构
Redis 的字符串是动态字符串,可以修改,内部结构类似于 Java 的 ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。如上图锁实,内部为当前字符串实际分配的空间 capacity,一般高于实际字符串长度 len。使用的指令有 set, get, mset, mge t等。
hash
Redis 的 hash 相当于 Java 的 HashMap,内部结构实现与 HashMap 一致,即数组 + 链表结构。
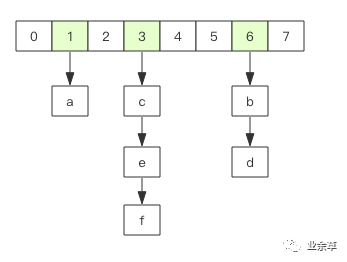
hash 数据结构
不过 Redis 的 hash 的值只能是字符串,rehash 方式不一样,为了提高性能,Redis 保留新旧两个 hash 结构,采用渐进式 rehash 策略,查询时会同事查询两个 hash 结构,在后续的定时任务中以及 hash 操作指令中,循序渐进将旧 hash 的内容迁移到 xinhash 中,直至完全取代旧 hash。hash 移除最后一个元素后会自动被删除,内存被回收。
前面说到 string 适合存储用户信息,而 hash 结构也可以存储用户信息,不过是对每个字段单独存储,因此可以在查询时获取部分字段的信息,节省网络流量。
因此就引出了这篇文章,存储结构体信息是用 hash 还是 string?
以下信息出自 StackOverflow,《Redis strings vs Redis hashes to represent JSON: efficiency?》:https://stackoverflow.com/questions/16375188/redis-strings-vs-redis-hashes-to-represent-json-efficiency
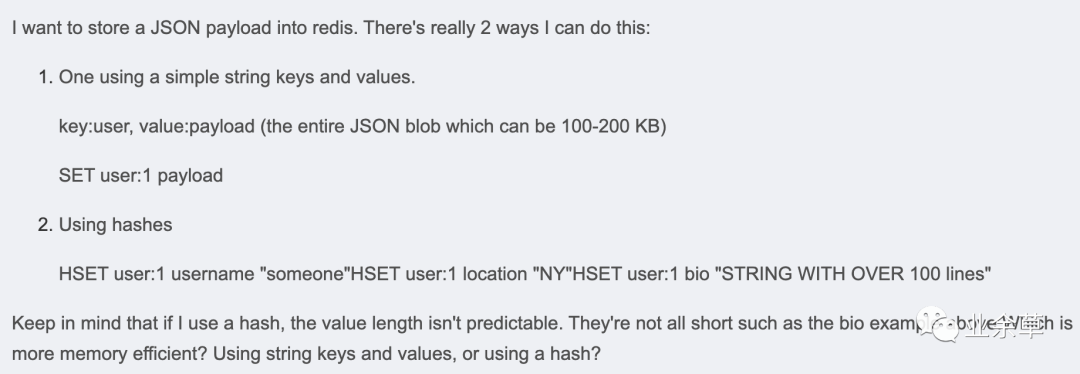
该用户也是同样的疑问,因为值的长度是不确定的,所以不知道采用 string 还是 hash 存储更有效率。
这个问题底下有个开发者回答的非常好,这里翻译出来供大家一起学习讨论,如果有更好的方案,欢迎提出来。
首先,答者建议参考 redis 官方的内存优化的文章:https://redis.io/topics/memory-optimization,用来理解官方的开发者是内存优化方面基于什么考虑。
之后,答者列出了四个方案并给出了各个方案的利弊
存储整个对象,其中 JSON 序列化过的字符串作为 key。
INCR id:users
SET user:{id} '{"name":"Fred","age":25}'
SADD users {id}
优势:可以认为是“最佳实践”,因为每个对象都是全特性的 key,JSON 解析特别块,尤其是一次性查询很多个字段的时候
劣势:如果只查询一个字段,速度就显得比较慢了。 2. 在 hash 中存储每个对象的属性
INCR id:users
HMSET user:{id} name "Fred" age 25
SADD users {id}
优势:这也可以认为是最佳时间。每个对象都是一个全特性的 key。不需要解析 JSON 字符串。
劣势:如果要查询对象的全部字段会比较慢。嵌套类型的对象(即对象里面还包着对象)无法轻易存储。
将对象转化为 JSON 字符串,用 hash 结构存储。
INCR id:users
HMSET users {id} '{"name":"Fred","age":25}'
这个方案可以仅用两个 key,不需要很多 key。但是没法对每个用户对象设置TTL(Time to Live,剩余生存时间),因为对象仅仅是 hash 中的一个字段,而不是全特性的 key。
优势:JSON 解析很快,尤其是一次查询多个字段时,对主 key 的命名空间污染更少。
劣势:如果要存储很多对象,那么内存使用和方案 1 相当。当只需要查询一个字段时,会比方案 2 速度慢。答者不认为这是一个“最佳实践”。
存储对象的每个属性作为单独的 key
INCR id:users
SET user:{id}:name "Fred"
SET user:{id}:age 25
SADD users {id}
根据上面的文章,即 redis 内存优化https://redis.io/topics/memory-optimization,这个方案不推荐(除非对象的属性需要专门设置 TTL 或者别的设置。
优势:对象的属性是全特征 key,对于应用来说比较好处理
劣势:慢,内存消耗更大,不是一个“最佳实践”。对主 key 的命名空间有很大污染
总的来说,方案 4 是最不推荐的,方案 1 和方案 2 非常相似,也很常见。答者更推荐方案 1,因为这个方案允许存储更复杂的对象(也就是说对象可以有很多层嵌套)。方案 3 通常用在对命名空间比较有要求的场景下,比如说不想要太多 key,不关心 TTL 等参数。