
TensorFlow 2.4 来了:新功能解读
↑↑↑点击上方蓝字,回复资料,10个G的惊喜
选自 | TensorFlow Blog 转自 | 机器之心 编辑 | 小舟、蛋酱

tape = tf.GradientTape()with tape:y_pred = model(x, training=True)loss = loss_fn(y_pred, y_true)# You can pass in the `tf.GradientTape` when using a loss `Tensor` as shown below.optimizer.minimize(loss, model.trainable_variables, tape=tape)
import tensorflow.experimental.numpy as tnp# Use NumPy code in input pipelinesdataset = tf.data.Dataset.from_tensor_slices(tnp.random.randn(1000, 1024)).map(lambda z: z.clip(-1,1)).batch(100)# Compute gradients through NumPy codedef grad(x, wt):with tf.GradientTape() as tape:tape.watch(wt)output = tnp.dot(x, wt)output = tf.sigmoid(output)return tape.gradient(tnp.sum(output), wt)
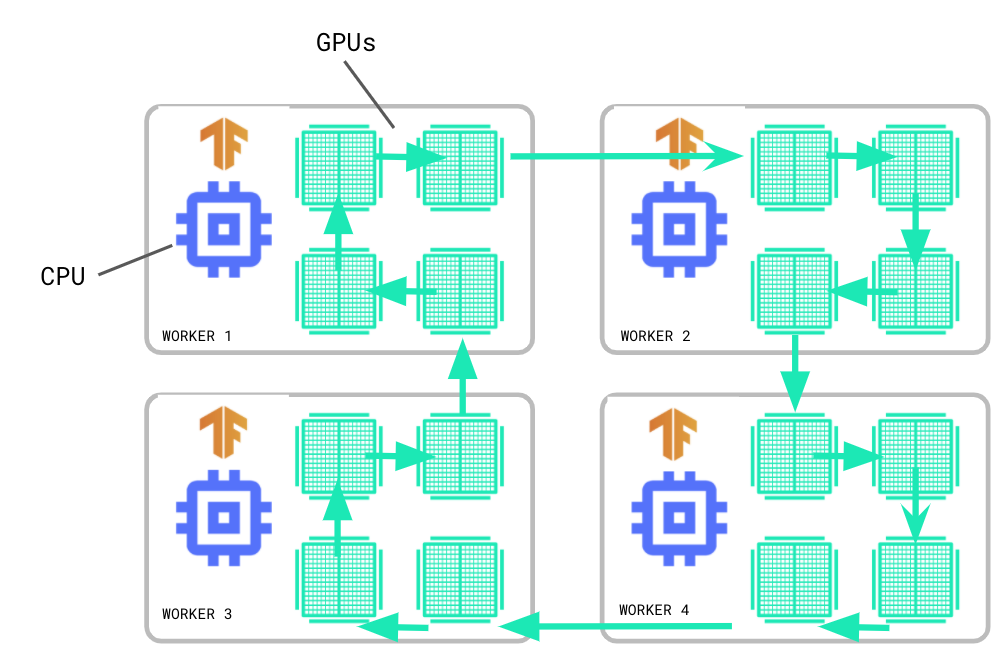
# Start a profiler server before your model runs.tf.profiler.experimental.server.start(6009)# Model code goes here....# E.g. your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you# would like to profile for a duration of 2 seconds. The profiling data will# be saved to the Google Cloud Storage path “your_tb_logdir”.tf.profiler.experimental.client.trace('grpc://10.0.0.2:6009,grpc://10.0.0.3:6009,grpc://10.0.0.4:6009','gs://your_tb_logdir',2000)
推荐阅读

评论