数据不够,是模型表现不佳的“借口”,还是真正的问题所在?


作者 | Gianluca Gindro
深度:增加数据点的数量
广度:增加数据源的多样性
高质量:整合混乱的数据!

从数据深度上下功夫
1、A/B测试或实验
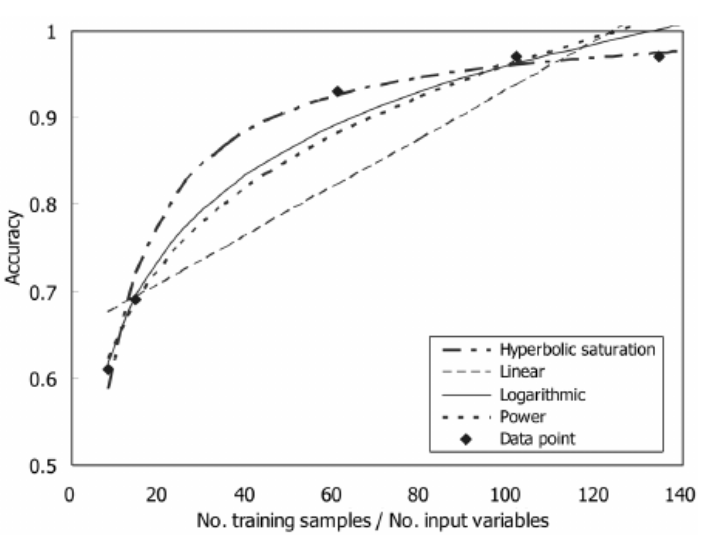
从数据广度上下功夫
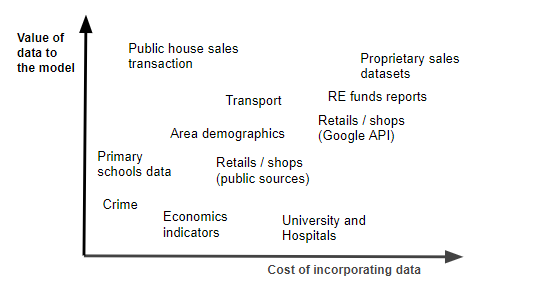
一次性获取 vs 反复获取 数据转换和存储的复杂性 数据质量和数据清理的需求 数据处理和解析
3
提高数据质量
4
总结
评论

深度:增加数据点的数量
广度:增加数据源的多样性
高质量:整合混乱的数据!