
采用编码器-解码器匹配语义分割的图像压缩
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


近年来,分层图像压缩被证明是一个很有前途的方向,它将输入图像编码成一个紧凑的表示形式,并应用上采样网络来重建图像。为了进一步提高重构图像的质量,一些作品将语义段与压缩后的图像数据一起传输。因此,由于需要额外的比特来传输语义段,压缩比也降低了。为了解决这一问题,我们提出了一种新的分层图像压缩框架,即编码器-解码器匹配语义分割(EDMS)。然后,在语义分割的基础上,利用一种特殊的卷积神经网络对不准确的语义段进行增强。这样,在不需要额外的比特的情况下,就可以在译码器中获得准确的语义段。实验结果表明,与目前最先进的基于语义的图像编解码器相比,所提出的EDMS框架可降低35.31%的BD-rate,节省5%的比特率和24%的编码时间。
提出了一种基于编解码器匹配语义分割(EDMS)的分层图像压缩框架。在编码器和解码器中对上采样图像采用了语义分割网络。但从上采样图像中提取的语义段不如从原始图像中提取的语义段准确。为了获得这一质量差距,进一步利用具有特殊结构的卷积神经网络(CNN)将提取的线段非线性映射到其原始分布。实验结果表明,该方法比目前最先进的基于分割的图像压缩方法具有更好的性能。
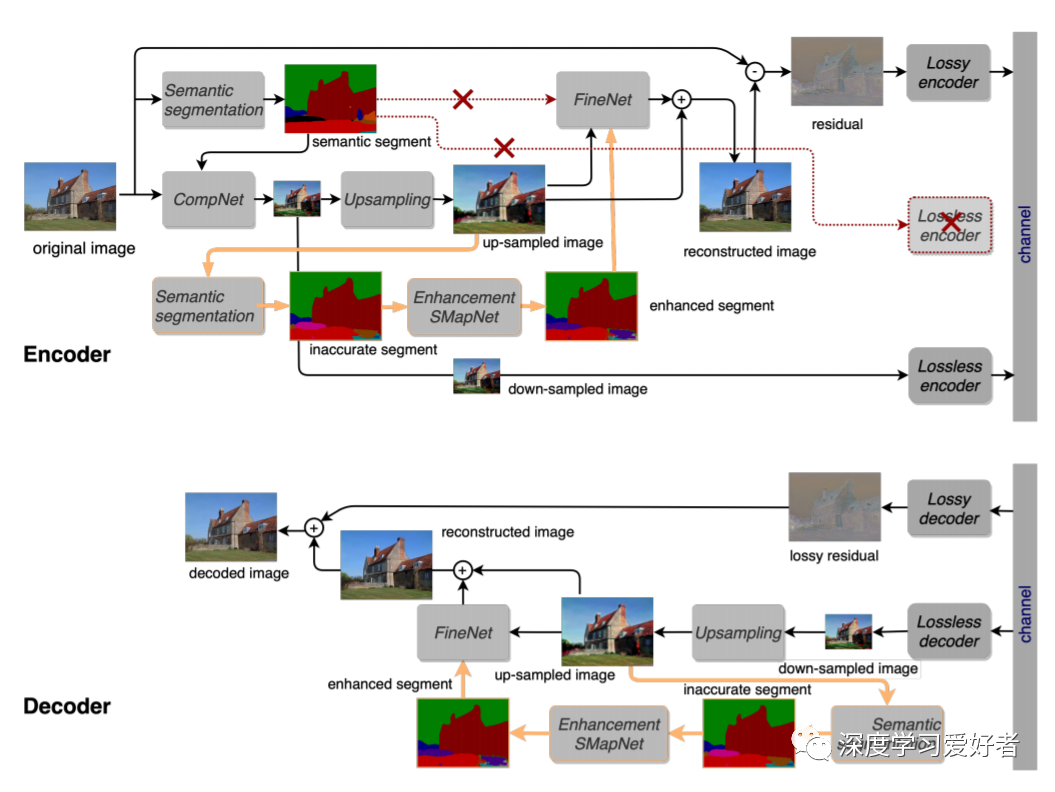
图1 我们提出的框架- EDMS与额外的分支分割增强
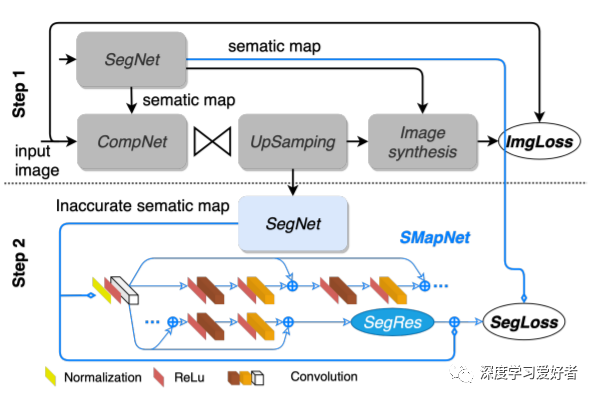
图1显示了我们的总体框架,在编码器方面,我们从上采样版本中提取片段,并使用SMapNet进行语义分割增强,并将SMapNet的输出输入到FineNet中语义段的位置。最后的残余将计算基于FineNet推进SMapNet段的输出作为输入(见图1),这残然后将由次封盖编码(先进的传统的有损图像编解码器)无损FLIF编解码器适用于图像的紧凑版本并没有额外的一些用于转移语义部分。
在解码端,我们只接收到下采样的图像和信道的损耗残差。用于重建解码后图像的语义段是从上采样的图像中进行的,并通过我们的SMapNet进行增强。接下来,FineNet使用这个增强的片段和上采样的图像作为输入来执行重建。由于我们也在编码器端执行这个过程,所以接收到的残差和重构图像之间总是存在相关性。然后将重构图像与残差相加,输出最终解码后的图像。
在我们的框架中有三个主要的网络:CompNet、FineNet和SMapNet(在本研究中提出)。图2显示了我们的SMapNet的体系结构和特定的培训过程。请参阅我们的补充文件的第1节,了解更多的培训过程和网络架构的细节。

我们的SMapNet在语义增强任务中的性能。从上采样的图像中提取不准确的语义段。

bpp/PSNR/MS-SSIM不同压缩编解码器的质量比较。注意,我们提出的方法以最小的比特率获得最好的解码质量。
本文提出了一种新的分层图像压缩框架,在不传输任何额外比特的情况下利用语义段。采用编码器-解码器匹配语义分割(EDMS)、语义段增强和特定训练程序的思想,在保证译码图像质量的同时,保留语义段传输所需的比特数。实验结果表明,与目前最先进的基于语义的图像编解码器DSSILC相比,该方法的性能优于所有传统编解码器,比特率提高5%,编码时间减少24%。由于仍然有大量的信息可以从编码器和解码器同步提取,我们的方法有潜力应用于其他未来的工作。
论文链接:https://arxiv.org/pdf/2101.09642.pdf
每日坚持论文分享不易,如果喜欢我们的内容,希望可以推荐或者转发给周围的同学。
- END -
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~