
《SQL必知必会》万字精华!
本文是《SQL必知必会》一书的精华总结,帮助读者快速入门SQL或者MySQL,主要内容包含:
数据库基础知识 库表的相关操作 检索数据的方法等

思维导图
下面的思维导图中记录了这本书的整体目录结构,包含内容有:
数据的检索 汇总数据 分组数据 …….
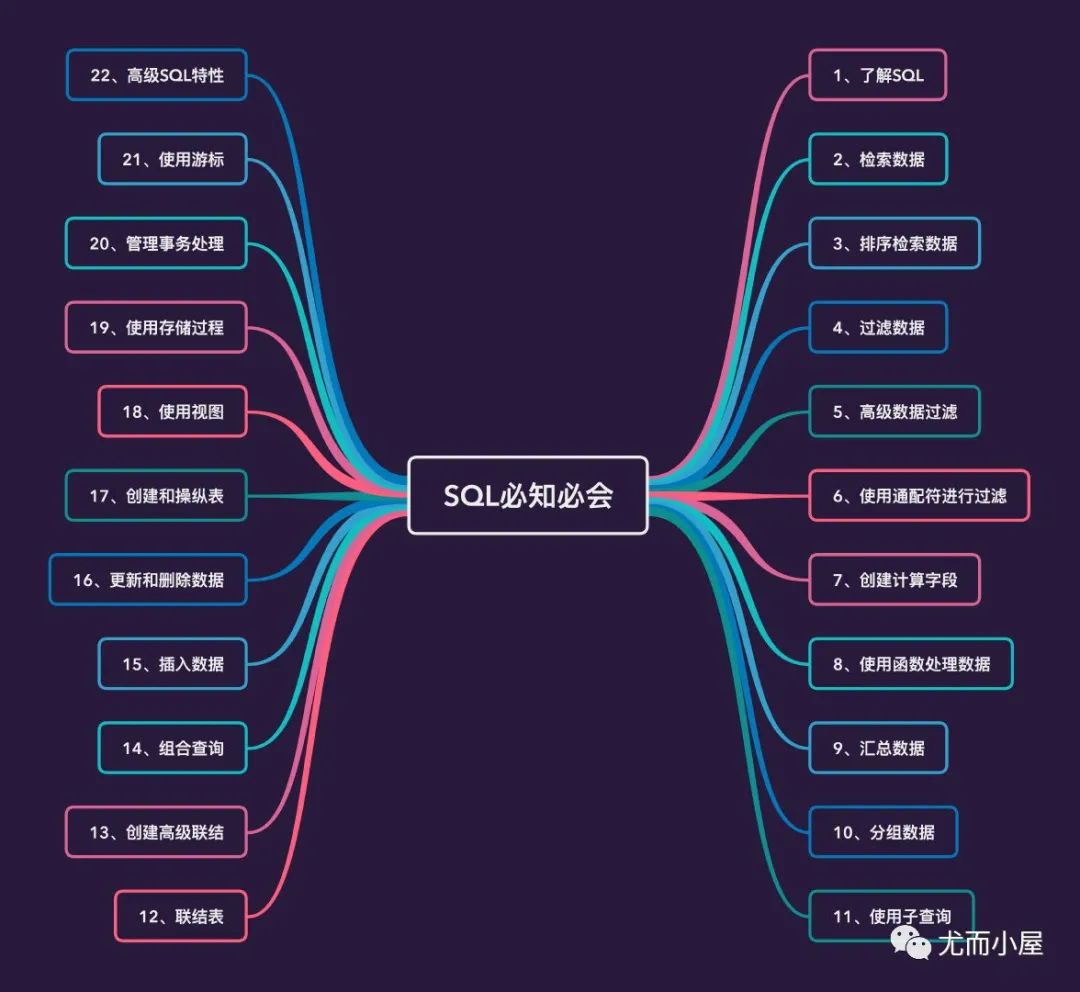
个人增加了一章:Python操作游标
一、了解SQL
本章中主要是介绍了数据库和SQL相关的基本知识和术语。
数据库
数据库是一个以某种有组织的方式存储的数据集合。数据库是一个保存有组织的数据容器,通常是一个文件或者一组文件
表
表示一种结构化的文件,可以用来存储某种特定的数据类型。表是某种特定类型数据的结构化清单。
存储在表中的数据是同一种类型的数据或者清单
数据库中的每个表都有自己的名字,并且这个表是唯一的。
列
表是由列组成的,列存储表中某部分的信息。列是表中的某个字段。所有的表都是由一个或者多个列组成的。
数据库中的每个列都应该是具有的相同数据类型datatype。数据类型定义了列可以存储哪些数据类型。
行
表中的数据是按照行来进行存储的,所保存的每个记录存储在自己的行内。如果把表想象成一个网格,那么网格中垂直的列则为表列,水平则为表行。
行表示的是一个记录。行有时候也称之为记录。
主键
表中每一行都应该都有一列或者几列来唯一标识自己。主键用来表示一个特定的行。
主键:一列或者几列,其值能够标识表中每行。
如果表中的列可以作为主键,则它必须满足:
任意两行都不具有相同的主键值(主键列不允许NULL值) 每行都必须有一个主键值 主键列中的值不允许修改或者更新 主键值不能重用(如果某行从表中删除,则它的主键不能赋给以后的行记录)
什么是SQL
首先我们看一段来自百度百度的解释:
结构化查询语言(Structured Query Language)简称SQL,是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。
SQL是一种专门和数据库沟通的语言
SQL特点
1、SQL不是某个特定数据库供应商专有的语言,几乎所有的DBMS都是支持SQL
2、SQL简单易学。它的语句都是由简单的、具有描述性的英文单词组成的
3、SQL虽然简单,但是实际上是一种很强有力的语言,灵活使用去语言元素,可以进行复杂和高级的数据库操作
二、检索数据
本章中介绍的是如何使用select语句从表中检索一个或者多个数据列。
每个SQL语句多有一个或者多个关键字组成,最经常使用的就是select关键字。它的用途是从一个或者多个表中检索出来信息。为了使用select检索数据,必须至少给出两个信息:
检索什么(字段,列) 从哪里检索(表)
检索单个列
SELECT prod_name -- 检索什么
FROM Products; -- 从哪里检索
下面关于SQL的语句做几点笔记:
多条SQL语句必须是以分号 ;结尾;如果是单条不加分号也是可以的,但是最好加上SQL语句不区分大小写,即: SELECT和select是相同的。但是一般规范的写法是:SQL关键字进行大写,列名和表名是小写的在处理SQL语句的时候,其中所有的空格都是忽略的;但是分行写,语句更清晰,更好理解
-- 写法1
SELECT prod_name -- 检索什么
FROM Products; -- 从哪里检索
-- 写法2
SELECT prod_name FROM Products;
-- 写法3
SELECT
prod_name
FROM
Products;
-- 写法:个人习惯写法
SELECT
prod_name
FROM Products;
检索多个列
SELECT pro_id,prod_name,prod_price
FROM Products;
-- 个人写法
SELECT
pro_id,
prod_name,
prod_price
FROM Products;
检索所有列
SELECT * -- *代表所有列
FROM Products;
检索不同的值
SELECT DISTINCT vend_id
FROM products;
SQL中的
DISTINCT关键字表示的是去重,只返回不同的值。它必须放在列的前面。不能部分使用
DISTINCT关键字。它是作用于所有的列
SELECT DISTINCT vend_id, prod_price -- DISTINCT作用于所有的列,并不仅仅是后面的列
限制结果
如果不加限制条件,SQL返回的是全部数据。如果我们想只显示部分数据,该如何实现?
1、SQL Server 和 Access
SELECT TOP 5 prod_name -- 最多返回5行
FROM Products;
2、DB2
SELECT prod_name
FROM Products
FETCH FIRST 5 ROWS ONLY; -- 字面意思:显示前5行
3、Oracle
SELECT prod_name
FROM Products
WHERE ROWNUM <= 5;
4、MySQL、MariaDB、PostgreSQL、SQLite
使用关键字limit
SELECT prod_name
FROM Products
LIMIT 5; -- 使用LIMIT5
关于LIMIT的笔记:
SELECT prod_name
FROM Products
LIMIT 4 OFFSET 5; -- 第5行开始显示4行数据
-- 简化版本
SELECT prod_name
FROM Products
LIMIT 5,4 -- 效果同上
第一个数字表示显示多少行数据 第二个数字表示从哪里开始显示
SQL注释问题
SQL中的注释分为两种:单行注释和多行注释
单行注释使用—符号,后面跟上注释的内容:
SELECT prod_name -- 这里是一条注释,你可以写点注释
FROM Products
LIMIT 4 OFFSET 5;
多行注释使用一对/*,符号之间的内容就是注释:
/*
注释1:SQL语句的作用是什么
注释2:SQL语句谁在什么时候写的
*/
SELECT prod_name
FROM Products
LIMIT 4 OFFSET 5;
三、排序检索数据
排序数据(单个列)
本节中介绍的是如何利用order by子句来对select检索的结果进行排序。为了明确地排序用select语句检索出来的数据,可使用order by子句取一个或者多个列的名字,来对输出结果进行排序。
使用关键词order by 排序的结果默认是升序ASC,降序是DESC
SELECT prod_name
FROM Products
ORDER BY prod_name; -- 根据产品名称的字母进行排序
笔记:我们需要注意order by子句的位置,一定要保证它是select语句的最后一条子句。如果它不是最后的子句,那么就会报错。
按多个列排序
在实际的需求中,我们经常会遇到根据多个列进行排序。比如根据员工的姓名排序,如果姓相同,再根据名字进行排序。
要按多个列进行排序,指定列名即可,列名之间使用逗号隔开。
SELECT prod_id,prod_price,prod_name -- 选择3个列
FROM Products
ORDER BY prod_price,prod_name; -- 先根据价格排序,如果有相同的价格再根据姓名排序
笔记:只有当prod_price有相同的值,才会根据prod_name进行排序
按列位置进行排序
除了可以使用列名指出排序顺序外,order by还支持使用相对位置进行排序。
SELECT
prod_id,
prod_price,
prod_name -- 选择3个列
FROM Products
ORDER BY 2,3; -- 2,3就是相对位置
2表示的是第2个列(prod_price) 3表示的是第3个列名(prod_name)

如果想在多个列上进行降序排列,则对每个列都要指定DESC关键词:
-- 正确写法
SELECT
prod_id,
prod_price,
prod_name
FROM Products
ORDER BY prod_price DESC, prod_name DESC; -- 每个列都指定DESC
-- 错误写法!!!
SELECT
prod_id,
prod_price,
prod_name
FROM Products
ORDER BY prod_price, prod_name DESC; -- DESC只对最近的prod_name起作用,那么prod_price仍然是升序排列的
四、过滤数据
本节中讲解的是使用where关键词来过滤数据。数据库中一般存在大量的数据,一般我们只需要检索表中少量的行。只检索所需数据需要指定搜索条件,搜索条件也称之为过滤条件。
使用where子句
SELECT prod_name, prod_price
FROM Products
WHERE prod_price=5; -- 指定条件
笔记:当ORDER BY 和WHERE子句同时存在的时候,ORDER BY子句应该位于WHERE子句之后。
WHERE子句操作符
常用的where子句操作符:
| 操作符 | 说明 | 操作符 | 说明 | |
|---|---|---|---|---|
| = | 等于 | > | 大于 | |
| <> | 不等于 | >= | 大于等于 | |
| != | 不等于 | !> | 不大于 | |
| < | 小于 | BETWEEN…AND... | 在指定的两个值之间 | |
| > | 大于 | IS NULL | 为NULL值 | |
| !< | 不小于 |
注:上面表格中的某些操作符是等价的。
检查单个值
SELECT prod_name, prod_price
FROM Products
WHERE prod_price <= 5; -- 指定1个条件
SELECT vend_id, prod_name, prod_price
FROM Products
WHERE vend_id <> 'DLL01' -- 指定不等于条件
笔记:
1、上面where子句中,可以看到有的只会在单引号内,但是有的没有括起来。
2、单引号用来限定字符串。如果将值和字符串类型的比较,需要使用限定符号
3、用来与数值列进行比较的值,则不用括号。
不匹配检查
SELECT vend_id, prod_name, prod_price
FROM Products
WHERE vend_id <> 'DLL01' -- 不匹配检查条件
范围值检查
要检查某个范围的值,可以使用BETWEEN操作符。BETWEEN操作符要搭配AND同时使用,指定范围的最大值和最小值:
SELECT vend_id, prod_name, prod_price
FROM Products
WHERE prod_price BETWEEN 100 AND 600 -- BETWEEN ... AND...联合使用
空值检查
当我们创建表的时候,可以指定其中的列是否包含空值。在一个列不包含值时,称其包含空值NULL。
注:NULL(无值,no value),它和字段包含0、空字符串或仅仅包含空格是不同的。
SELECT中一个特殊的WHERE子句用来检查具有NULL值的列:
SELECT prod_name, prod_price
FROM Products
WHERE prod_price IS NULL; -- 找出价格为NULL的数据
五、高级数据过滤
本节中介绍的是如何组合WHERE子句以建立功能更强、更高级的搜索条件
组合WHERE子句
操作符operator:用来联结或改变WHERE子句中的子句的关键字,也称之为逻辑操作符logical operator。
AND操作符
同时满足AND操作符两边的条件
SELECT vend_id, prod_name, prod_price
FROM Products
WHERE vend_id >= 'DLL01' AND prod_price <= 20; -- AND操作符指定2个条件
OR操作符
满足OR操作符两边的一个条件即可
SELECT vend_id, prod_name, prod_price
FROM Products
WHERE vend_id >= 'DLL01' OR prod_price <= 20; -- AND操作符指定2个条件
注:当第一个条件满足的时候,第二个条件便不会执行了。
AND和OR联用
在WHERE子句中同时使用AND和OR操作符:
⚠️:AND操作符的优先级是高于OR操作符
⚠️:AND操作符的优先级是高于OR操作符
⚠️:AND操作符的优先级是高于OR操作符
SELECT prod_name,prod_price
FROM Products
WHERE vend_id = 'DLL01' OR vend_id = 'BRS01' AND prod_price >= 10;
上面的语句原本表达的含义是先挑选满足两个vend_id的条件;但是SQL在执行的时候,AND操作符先处理。如果我们想先执行AND前面的部分,可以加上括号:
SELECT prod_name,prod_price
FROM Products
WHERE (vend_id = 'DLL01' OR vend_id = 'BRS01') AND prod_price >= 10;
括号具有比AND或者OR更高的优先级,能够消除歧义。
IN操作符
IN操作符用来指定条件范围,范围中的每个条件都可以进行匹配。
SELECT prod_name,prod_price
FROM Products
WHERE vend_id IN ('DLL01','BRS01') -- 功能类似于OR操作符
ORDER BY name:
笔记:IN操作符的主要优点
1、IN操作符的语法更清楚、更直观
2、使用了IN操作符更容易管理求值顺序
3、IN操作符一般比OR操作符执行的更快
4、在IN操作符中可以包含其他SELECT子句,能够动态地建立where子句
NOT操作符
NOT操作符只有一个功能:就是否定后面所跟的任何条件。
SELECT prod_name
FROM Products
WHERE NOT vend_id = 'DLL01' -- 找出不是DLLO1名字的数据
ORDER BY prod_name
上面的语句的功能也可以用<>来实现:
SELECT prod_name
FROM Products
WHERE vend_id <> 'DLLO1' -- 不等于,效果同上
ORDER BY prod_name
六、使用通配符进行过滤
什么是通配符
通配符wildcard是用来匹配值的一部分的特殊字符;利用通配符,可以创建比较特定数据的搜索模式。
笔记:由字面值、通配符或者两者组合构成的搜索条件。
为了在搜索子句中使用通配符,必须使用LIKE操作符
⚠️通配符搜索只能用于文本字段(字符串),对于非文本数据类型不能使用通配符搜索。
百分号%
功能:匹配任意字符出现的任意次数,即任意内容
SELECT prod_id, prod_name
FROM Products
WHERE prod_name LIKE "Fish%" -- 找出所有Fish开头的产品,不管后面是什么内容
通配符可以在任意位置使用,可以使用多次:
SELECT prod_id, prod_name
FROM Products
WHERE prod_name LIKE "%bean bag%" -- 匹配名字中包含bean bag的任意名字的数据,不管前后
通配符出现在中间:
SELECT prod_name
FROM Products
WHERE prod_name LIKE 'F%y' -- 找出F开头y结尾的数据
⚠️:百分号%能够匹配任意位置的0个、1个或者多个字符,但是不能匹配NULL
下划线_
下划线通配符的用途和百分号类似,但是它只能匹配一个字符,百分号是匹配多个字符,这是二者的区别。
SELECT prod_id, prod_name
FROM Products
WHERE prod_name LIKE '__ inch teddy bear' -- 前面是两个下划线_
-- 结果
prod_id prod_name
------- ---------
BR02 12 inch teddy bear -- 12或者18刚好是两个字符
BR03 18 inch teddy bear
一个下划线刚好只能匹配一个字符,不能多也不能少
方括号[]
方括号[]通配符用来指定一个字符集,它必须匹配指定位置的一个字符。
SELECT cust_contact
FROM Customers
WHERE cust_contact LIKE '[JM]%' -- 匹配JM当中一个字母开头,后面是任意字符的内容
ORDER BY cust_contact
[JM]:匹配其中一个字符 %:匹配任意内容
取反字符^
使用取反符号^来否定内容:
SELECT cust_contact
FROM Customers
WHERE cust_contact LIKE '[^JM]%' -- 匹配不是JM开头的任意内容
ORDER BY cust_contact;
使用NOT操作符可以得到类似上面的结果:
SELECT cust_contact
FROM Customers
WHERE NOT cust_contact LIKE '[JM]%' -- 匹配不是JM开头的任意内容;NOT表示取反,否定内容
ORDER BY cust_contact;
通配符使用技巧
⚠️通配符使用的几点注意事项:
不要过度使用通配符 如果确实需要使用通配符,尽可能不要将它们放在搜索模式的开始位置。通配符处于开始处,搜索是最慢的。 仔细注意通配符的位置。如果放错地方,可能得不到我们想要的结果。 通配符应该要细心使用,不要过度使用。
七、创建计算字段
计算字段
存储在数据库表中的字段一般不是应用程序中所需要的格式。我们需要直接从数据库中检索出来进行转换、计算或者格式化过的数据。计算字段并不实际存在于数据库表中。计算字段是运行时在select语句内创建的。
拼接字段
将多个字段联结在一起构成单个字段。根据不同的DBMS,使用+或者||来进行联结。但是在MySQL中必须使用特殊的函数来进行操作。
拼接字段函数Concat的使用:
SELECT
Concat(vend_name, ' (', vend_country, ')')
FROM Vendors
ORDER BY vend_name;
代码解释:
存在列vend_name列中的名字 包含一个空格和一个左圆括号的字符串 存在vend_country列中的国家 包含一个右圆括号的字符串
小知识:MySQL中如何去掉空格?
RTRIM(col) -- 去掉值右边的所有空格
LTRIM(col) -- 去掉值左边的所有空格
TTRIM(col) -- 去掉字符串左右两边的所有空格
使用别名
别名(alias)是一个字段或者值的替换明,别名是使用关键词AS来赋予的。
SELECT
Concat(vend_name, ' (', vend_country, ')') AS vend_title -- 使用别名
FROM Vendors
ORDER BY vend_name;
笔记:AS关键词语是可选的,但是最好使用
执行算术运算
计算字段的另一个常见运算是对检索出来的数据进行算术运算。
SELECT
prod_id
,quantity
,item_price
,quantity * item_price AS expanded_price -- 计算字段执行算术运算,并使用别名
FROM OrderItems
WHERE order_num = 2008;
SQL算术操作符
SQL中支持的算术操作符:
| 操作符 | 说明 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
八、使用函数处理数据
常用函数
与其他计算机语言一样,SQL中也提供函数来处理数据。
用于处理文本字符串:删除或填充值、转换值或者大小写转化 用于在数值数据上进行算术操作:返回绝对值、代数运算等 用于处理日期和时间,并从中提取出特定成分的日期和时间函数等 返回DBMS正使用的特殊信息的系统函数
文本处理函数
| 函数 | 说明 |
|---|---|
| LEFT() | 返回字符串左边的字符 |
| LENGTH() | 返回字符串的长度 |
| LOWER() | 将字符串转换为小写 |
| LTRIM() | 去掉值左边的所有空格 |
| RIGHT() | 返回字符串右边的字符 |
| RTRIM() | 去掉值右边的所有空格 |
| SOUNDEX() | 返回字符串的SOUNDEX值 |
| UPPER() | 将字符串转换为大写 |
SOUNDE(X)是一个将任何文本串转成描述其语音表示的字母数字模式的算法。
SELECT
cust_name
,cust_contact
FROM Customers
WHERE SOUNDEX(cust_contact) = SOUNDEX('Michael Green') -- 转化成对应的值
日期和时间处理函数
日期和时间采用相应的数据类型存储在表中,以特殊的格式来存储。
SELECT
order_num
FROM Orders
WHERE YEAR(order_date) = 2012; -- 提取年份
数值处理函数
MySQL中常用的数值处理函数:
| 函数 | 说明 |
|---|---|
| ABS() | 返回一个数的绝对值 |
| COS() | 返回一个角度的余弦值 |
| EXP() | 返回一个数的指数值 |
| PI() | 返回圆周率 |
| SIN() | 返回一个角度的正弦 |
| SQRT() | 返回一个数的平方根 |
| TAN() | 返回一个角度的正切值 |
九、汇总数据
聚集函数
聚集函数指的是对某些行运行的一个函数,并且返回一个值,常用的聚集函数有:
| 函数 | 作用 |
|---|---|
| AVG() | 返回列的平均值 |
| COUNT() | 返回列的函数 |
| MAX() | 返回列的最大值 |
| MIN() | 返回列的最小值 |
| SUM() | 返回某列值之和 |
1、AVG()函数
SELECT AVG(prod_price) AS avg_price -- 求平均值
FROM Products;
上面求解的是所有行各自的平均值,也可以指定某个特定的行来求解:
SELECT AVG(prod_price) AS avg_price -- 求平均值
FROM Products
WHERE vend_id = 'DLLO1'; -- 指定特定的行
笔记:AVG()函数会忽略掉值NULL的行
2、COUNT()函数
COUNT()函数进行计数,可以使用它来确定表中的函数或者符合特定条件的行的数目,两种使用情况:
count(*):不管是空值(NULL)还是非空值,都会统计进去 count(column):对特定的列进行计数,会忽略表该列的NULL值
SELECT COUNT(*) AS num_cust
FROM Customers;
num_cust
--------
5
SELECT COUNT(cust_email) AS num_cust
FROM Customers;
num_cust
--------
3
笔记:如果指定列名,则COUNT()函数会忽略指定列的值为空的行,但是如果COUNT()函数使用的是星号,则不会忽略
3、MAX()/MIN()函数
返回指定列中的最大值或者最小值
SELECT MAX(prod_price) AS MAX_price -- 求最大值
SELECT MAX(prod_price) AS MIN_price -- 求最小值
FROM Products;
笔记:上面的两个最值函数会自动忽略掉值为NULL的行
4、SUM()函数
返回指定列值的和(总计)
SELECT SUM(quantity) AS items_ordered
FROM OrderItems
WHERE order_num = 20005;
SUM()函数也可以用来合计计算值:
SELECT SUM(item_price * quantity) AS total_price -- 返回所有物品的价钱之和
FROM OrderItems
WHERE order_num = 20005;
笔记:SUM()函数会自动忽略值为NULL的行
聚集不同值
上面的5个聚集函数都可以如下使用:
对所有的行执行计算,指定ALL参数或不指定参数(因为ALL是默认行为) 只包含不同的值,指定DISTINCT参数,表示去重之后再进行计算
笔记:ALL参数不需要指定,是默认行为
SELECT AVG(DISTINCT prod_price) AS avg_price -- 去重之后再求平均值
FROM Products
WHERE vend_id = 'DLLO1'; -- 指定特定的行
笔记:
1、DISTINCT不能用于COUNT(*);如果指定列名,则DISTINCT只能用于COUNT()
2、DISTINCT必须使用列名,不能用于计算或者表达式
3、DISTINCT用于MAX()和MIN()意义不大,因为最值不管是否考虑去重,都是一样的
组合聚集函数
在SELECT子句中是可以包含多个聚集函数
SELECT
AVG(prod_price) AS avg_price -- 求平均值
,MAX(prod_price) AS max_price -- 求最大值
,MIN(prod_price) AS min_price -- 求最小值
,COUNT(*) AS num_items -- 物品的数目
FROM Products;
十、分组数据
分组使用的是两个子句:
GROUP BY() HAVING()
创建分组
分组是使用SELECT子句的GROUP BY子句建立的,看个例子:
SELECT
vend_id
,COUNT(*) AS num_prods
FROM Products
GROUP BY vend_id; -- 分组的列
GROUP BY子句使用时候的常见规定:
GROUP BY子句可以包含任意数目的列,可以对分组进行嵌套 GROUP BY子句中列出的每一列都是检索列或者有效的表达式(但是不能是聚集函数) 如果在SELECT中使用表达式,则必须在GROUP BY子句中使用相同的表达式,而不是使用别名 除了聚集函数外,SELECT语句中的每列都必须在GROUP BY子句中列出 如果分组中包含具有NULL的行,则NULL将作为一个分组返回;如果列中出现多个NULL,它们将分成一个组 GROUP BY子句必须在WHERE子句之后,ORDER BY子句之前 GROUP BY子句中可以使用相对位置:GROUP BY 2, 1 表示先根据第二个列分组,再根据第一个列分组
过滤分组
在WHERE子句中指定过滤的是行而不是分组;实际上WHERE种并没有分组的概念。在SQL使用HAVING来实现过滤分组;
笔记:WHERE过滤行,HAVING过滤分组
SELECT
cust_id
,COUNT(*) AS orders
FROM Orders
GROUP BY cust_id
HAVING COUNT(*) >= 2; -- 过滤分组
WHERE和HAVING的区别:
WHERE在数据过滤前分组,排除的行不在分组统计中 HAVING在数据分组后进行过滤
SELECT
vend_id
,COUNT(*) AS num_prods
FROM Products
WHERE prod_price >= 4 -- 分组前先执行,找出符合条件的数据
GROUP BY vend_id
HAVING COUNT(*) >= 2; -- 分组后再执行,找出数目大于2的数据
分组和排序
ORDER BY 和GROUP BY的差异:
| ORDER BY | GROUP BY |
|---|---|
| 对产生的输出排序 | 对行分组,但输出可能不是分组的顺序 |
| 任意列都可以使用(非选择的列也可以使用) | 只可能使用选择列或者表达式列,而且必须使用每个选择列表达式 |
| 不一定需要 | 如果和聚集函数一起使用列,则必须使用 |
SELECT
order_num
,COUNT(*) AS items
FROM OrderItems
GROUP BY order_num
HAVING COUNT(*) >= 3
ORDER BY items, order_num; -- 先分组再过滤,最后排序输出
SELECT子句顺序
在这里总结一下SELECT子句的相关顺序:
| 子句 | 说明 | 是否必须使用 |
|---|---|---|
| SELECT | 要返回的列或者表达式 | 是 |
| FROM | 从中检索数据的表 | 仅在从表选择数据时使用 |
| WHERE | 行级过滤 | 否 |
| GROUP BY | 分组说明 | 仅在按照组计算聚集时使用 |
| HAVING | 组级过滤 | 否 |
| ORDER BY | 输出排序顺序 | 否 |
十一、使用子查询
任何SELECT语句都是查询,SQL还允许在查询中嵌套查询。
SELECT cust_id -- 再根据子查询中的order_num找出符合要求的cust_id
FROM Orders
WHERE order_num IN (SELECT order_num -- 先根据WHERE条件找出满足符合要求的order_num
FROM OrderItems
WHERE prod_id = 'RGAN01');
笔记:子查询总是从内向外处理
SELECT Customers -- 最后根据找出的cust_id查询Customers
FROM cust_id IN(SELECT cust_id -- 再根据子查询中的order_num找出符合要求的cust_id
FROM Orders
WHERE order_num IN (SELECT order_num -- 先根据WHERE条件找出满足符合要求的order_num
FROM OrderItems
WHERE prod_id = 'RGAN01'));
作为计算字段使用子查询
使用子查询的另一个方法是创建计算字段
SELECT
cust_name
,cust_state
,(SELECT COUNT(*) -- 将子查询作为一个计算字段输出:统计每个cust_id的数量
FROM Orders
WHERE Orders.cust_id = Customers.cust_id) AS orders -- Orders.cust_id = Customers.cust_id 使用完全限定列名来避免歧义
FROM Customers
ORDER BY cust_name;
十二、 联结表
SQL最强大的功能就是数据查询的过程中使用联结表(join)。
创建联结
通过指定要联结的表和它们的联结方式即可创建联结。
SELECT
vend_name,
prod_name,
prod_price
FROM Vendors, Products
WHERE Vendors.vend_id = Products.vend_id; -- 指定联结条件
如果上面的代码中没有WHERE子句来指定联结条件,则返回的是笛卡尔积,返回出来数的行就是第一个表中的行乘以第二个表中的行。
笔记:返回笛卡尔积的联结,也称做叉联结cross join
内联结inner join
使用最广泛的联结是等值联结,也称之为内联结inner join。实现上面语句的内联结代码:
SELECT
vend_name,
prod_name,
prod_price
FROM Vendors
INNER JOIN Products -- 内联结
ON Vendors.vend_id = Products.vend_id; -- 指定联结条件
联结多个表
SELECT
vend_name,
prod_name,
prod_price
FROM OrderItems, Products, Vendors
WHERE Products.vend_id = Vendors.vend_id -- 多个表的联结
AND OrderItems.prod_id = Products.prod_id
AND order_num = 20007;
我们通过联结方式来实现子查询的结果:
-- 子查询
SELECT Customers -- 最后根据找出的cust_id查询Customers
FROM cust_id IN(SELECT cust_id -- 再根据子查询中的order_num找出符合要求的cust_id
FROM Orders
WHERE order_num IN (SELECT order_num -- 先根据WHERE条件找出满足符合要求的order_num
FROM OrderItems
WHERE prod_id = 'RGAN01'));
-- 内联结
SELECT
cust_name,
cust_contact
FROM Customers, Orders, OrderItems
WHERE Customers.cust_id = Orders.cust_id -- 多个表联结查询
AND OrderItems.order_num = Orders.order_num
AND prod_id = 'RGAN01'
十三、创建高级联结
使用表别名
在SQL语句中可以给表取别名:
SELECT
cust_name,
cust_contact
FROM Customers AS C, Orders AS O, OrderItems AS OI -- 取别名,看上去更简洁
WHERE C.cust_id = O.cust_id -- 多个表联结查询
AND OI.order_num = O.order_num
AND prod_id = 'RGAN01'
使用不同类型的联结
介绍3种不同的联结:
自联结self join 自然联结natural join 外联结outer join
1、自联结self join
-- 子查询
SELECT cust_id,cust_name,cust_contact
FROM Customers
WHERE cust_name = (SELECT cust_name
FROM Customers
WHERE cust_contact = 'Jim Jones');
-- 内联结
SELECT c1.cust_id, c2.cust_name, c1.cust_contact
FROM Customers AS c1, Customers AS c2 -- 相同的表使用两次
WHERE c1.cust_name = c2.cust_name
AND c2.cust_contact = 'Jim Jones';
上面使用了Customers表两次,为了避免歧义,必须使用不同的别名加以区分。
2、自然联结
无论何时对表进行联结,应该至少有一列不止出现在一个表中(被联结的列)。自然联结排除多次出现,是每一列只返回一次。
SELECT
C.*
,O.order_num
,O.order_date
,OI.prod_id
,OI.quantity
,OI.item_price
FROM Customers AS C, Orders AS O, OrderItems AS OI
WHERE C.cust_id = O.cust_id -- 多个表联结查询
AND OI.order_num = O.order_num
AND prod_id = 'RGAN01'
3、外联结
有时候我们需要将一个表中的行和另一个表中行相关联,但是有时候也需要包含那些没有关联行的行记录,比如下面的场景中:
对每个顾客下的订单数进行统计,包含那些至今尚未下单的顾客 列出所有产品以及订购数量,包含没有人订购的产品 计算平均销售规模,包含那些至今尚未下订单的顾客
当联结中包含了那些在相关表中没有关联行的行,这种联结称之为外联结。比如:检索出包括没有订单顾客在内的所有顾客。
SELECT
C.cust_id
,O.order_num
FROM Customers AS C
LEFT OUTER JOIN Orders AS O -- 外连接
ON Customers.cust_id = Orders.cust_id
上面的代码中表示包含左边所有行的记录;如果是右边,使用RIGHT OUTER。因此外联结实际上有两种形式,它们之间可以互换
左外联结 右外联结
还有一种比较特殊的外联结,叫做全外联结full outer join,它检索的是两个表中的所有行并关联那些可以关联的行。全外联结包含两个表的不关联的行
SELECT
C.cust_id
,O.order_num
FROM Customers AS C
FULL OUTER JOIN Orders AS O -- 外连接
ON Customers.cust_id = Orders.cust_id
带有聚集函数的联结
检索所有顾客及每个顾客所有的订单数:
SELECT
C.cust_id
,COUNT(O.order_num) AS num_ord -- 使用聚集函数统计订单数
FROM Customers AS C
INNER JOIN Orders
ON C.cust_id = O.cust_id -- 关联两个表
GROUP BY Customers.cust_id -- 分组
使用联结和联结条件
总结一下联结和使用要点:
注意使用联结的类型:一般是使用内联结,有时候外联结有有效 要保证使用正确的联结条件,否则会返回不正确的数据 记得提供联结条件,否则返回的是笛卡尔积 一个联结中可以包含多个表,甚至可以对不同的表使用不同的联结类型。要注意测试每个联结
十四、组合查询UNION
什么是组合查询
SQL允许执行多个查询(多条SELECT语句),并将结果作为一个查询结果集返回,这些组合通常称为并union或者复合查询;通常两种情况下需要使用组合查询:
在一个查询中从不同的表返回结构数据 对一个表执行多个不同的查询,按照一个查询返回数据
创建组合查询
可以用UNION操作符来组合数条SQL查询。
-- 语句1
SELECT cust_name, cust_contact,cust_email
FROM Customers
WHERE cust_state IN ('IL','IN','MI');
-- 语句2
SELECT cust_name, cust_contact,cust_email
FROM Customers
WHERE cust_name = 'Fun4ALL';
通过组合查询将上面两个查询组合在一起:
-- 组合查询
SELECT cust_name, cust_contact,cust_email
FROM Customers
WHERE cust_state IN ('IL','IN','MI')
UNION -- 关键字
SELECT cust_name, cust_contact,cust_email
FROM Customers
WHERE cust_name = 'Fun4ALL';
我们也可以使用多个WHERE条件来实现:
-- 语句1
SELECT cust_name, cust_contact,cust_email
FROM Customers
WHERE cust_state IN ('IL','IN','MI')
AND cust_name = 'Fun4ALL';
UNION使用规则
总结UNION使用规则:
UNION必须由两条或者两条以上的SELECT语句组成;语句之间通过UNION关键字隔开 UNION中的每个查询必须包含相同的列、表达式或者聚集函数 列数据类型必须兼容:类型不必完全相同 UNION从查询结果集中会自动消除重复的行;但是如果想保留所有的行,使用UNION ALL 实现
对组合结果进行排序
SELECT语句的输出用ORDER BY子句排序。
-- 组合查询
SELECT cust_name, cust_contact,cust_email
FROM Customers
WHERE cust_state IN ('IL','IN','MI')
UNION -- 关键字
SELECT cust_name, cust_contact,cust_email
FROM Customers
WHERE cust_name = 'Fun4ALL'
ORDER BY cust_name, cust_contact; -- 组合之后再进行排序
十五、插入数据
插入数据
INSERT用来将行插入(或者添加)到数据库表中,3种插入方式:
插入完整的行 插入行的一部分 插入某些查询的结果
下面通过实际的例子来说明:
1、插入完整的行
INSERT INTO Customers
VALUES('1000000006',
'Tony',
'123 Any Street',
'New York',
'NY',
'1111',
'USA',
NULL,
NULL
)
将上面的数据插入到Customers表中,每列对应一个值。如果值不存在,则用NULL代替。同时插入数据的顺序必须和表中定义的相同。
安全写法:列出每个字段名称
INSERT INTO Customers(cust_id, -- 明确列出列名
cust_name,
cust_address,
cust_city,
cust_state,
cust_zip,
cust_country,
cust_contact,
cust_email
)
VALUES('1000000006', -- 和上面的列名一一对应
'Tony',
'123 Any Street',
'New York',
'NY',
'1111',
'USA',
NULL,
NULL
)
上面列名和下面插入的数据必须一一对应,我们改变插入顺序:
INSERT INTO Customers(cust_id, -- 明确列出列名
cust_zip,
cust_country,
cust_contact,
cust_email,
cust_name,
cust_address,
cust_city,
cust_state
)
VALUES('1000000006', -- 和上面的列名一一对应
'1111',
'USA',
NULL,
NULL,
'Tony',
'123 Any Street',
'New York',
'NY'
)
2、插入部分数据
上面的例子中我们插入的是全部列名的数据,现在指定部分列名进行插入:
INSERT INTO Customers(cust_id, -- 明确列出列名
cust_zip,
cust_country,
cust_name,
cust_address,
cust_city,
cust_state
)
VALUES('1000000006', -- 和上面的列名一一对应
'1111',
'USA',
'Tony',
'123 Any Street',
'New York',
'NY'
)
3、插入检索出来的数据
INSERT的另一种使用是将SELECT检索出来的结果插入到表中,使用INSERT SELECT语句
INSERT INTO Customers(cust_id, -- 2、将SELECT检索的结果插进来
cust_zip,
cust_country,
cust_contact,
cust_email,
cust_name,
cust_address,
cust_city,
cust_state
)
SELECT cust_id, -- 1、SELECT先检索结果
cust_zip,
cust_country,
cust_contact,
cust_email,
cust_name,
cust_address,
cust_city,
cust_state
FROM CustNew;
INSERT SELECT中SELECT语句也是可以包含WHERE子句,以便过滤插入的数据。
从一个表复制到另一个表
还有一种数据插入不需要使用INSERT语句,要将一个表的内容复制到另一个表,可以使用SELECT INSERT语句
SELECT *
INTO CustCopy
FROM Customers;
需要注意4点:
在复制的过程中,任何SELECT选项和子句都可以使用,包含WHERE 和GROUP BY子句 可以利用联结从多个表插入数据 不管从多少个表中检索数据,数据最终只能插入到一个表中 INSERT INTO是插入数据;SELECT INSERT是导出数据
十六、更新和删除数据
更新数据
更新(修改)表中的数据,可以使update语句。常见的有两种update方式:
更新表中特定的行 更新表中所有的行
update语句的3个组成部分:
要更新的表 列名和它们的新值 确定要更新哪些行的过滤条件
UPDATE Customers -- 1、待更新的表
SET cust_email = '28173497@gmail.com' -- 2、需要更细的列名和它的新值
WHERE cust_id = '10000000005'; -- 3、过滤条件
同时更新多个值:
UPDATE Customers -- 1、待更新的表
SET -- 2、同时更新多个值
cust_email = '28173497@gmail.com',
cust_contact = 'Sam Roberts'
WHERE cust_id = '10000000005'; -- 3、过滤条件
在更新多个列的值时,只需要使用提交SET命令,每个列=值对之间通过逗号隔开,最后一个列不同。
如果想删除某个列的值,可以将其设置成NULL(假如表定义允许NULL值)。
空字符串用 ''表示,是一个值NULL是没有值的
UPDATE Customers
SET cust_email = NULL
WHERE cust_id = '100000000005';
删除数据
从表中删除数据使用DELETE语句。有两种删除方式:
从表中删除特定的行 从表中删除所有的行
DELETE FROM Customers
WHERE cust_id = '011111111116';
DELETE是删除整行而不是删除列。要删除列请使用UPDATE语句
更新和删除的指导原则
请一定要带上WHERE子句,否则会修改全部的数据;除非我们的确是需要更新全部记录(少见) 要保证每个表都有主键,可以指定各个主键、多个值或者值的范围 在UPDATE或者DELETE语句使用WHERE语句之前,先用SELECT进行测试,保证它过滤掉的是正确的记录
十七、创建和操作表
创建表
SQL中一般有两种创建表的方法:
多数DBMS都具有交互式创建和管理数据库表的工具 表也可以直接使用SQL语句来操控;通过create table来实现
CREATE TABLE Products -- 创建表
(
prod_id CHAR(10) NOT NULL,
vend_id CHAR(10) NOT NULL,
prod_name CHAR(254) NOT NULL,
prod_price DECIMAL(8,2) NOT NULL,
prod_desc VARCHAR(1000) NULL
);
上面代码的解释:
表名紧跟CREATE TABLE 关键字 列名在圆括号中,各个列之间通过逗号隔开 每列的定义以列名开始,后紧跟数据类型 ,是否允许控制等 整条语句是以分号结束
使用NULL值
NULL值就是没有值或者缺失值。每个表中的列要么是NULL列,要么是NOT NULL列。
主键是其值唯一标识表中每一行的列。只有不允许NULL值的列可作为主键,允许NULL值的列不能作为唯一标识。
笔记:NULL是默认设置。如果不指定NOT NULL,则认为指定的就是NULL。
注意NULL和空字符串的区别:
NULL值没有值,不是空字符串 空字符串值一个有效的值,它不是无值 NULL值使用关键字NULL而不是空字符串指定
指定默认值
SQL中创建表的时候可以指定通过关键字DEFAULT来指定:
CREATE TABLE OrderItems
(
order_num INTEGER NOT NULL,
order_item INTEGER NOT NULL,
prod_id CHAR(10) NOT NULL,
quantity INTEGER NOT NULL DEFAULT 1, -- 指定默认值
item_price DECIMAL(8,2) NOT NULL
);
默认值一般是用于日期或者时间戳列。
更新表
更新表中的数据使用关键词ALTER TABLE。
ALTER TABLE Vendors
ADD vend_phone CHAR(20);
删除表
删除整个表而不是其内容,使用DROP TABLE。
DROP TABLE CustCopy; -- 执行这条语句将会永久删除该表
重命名表
通过关键字RENAME来实现
RENAME TABLE old_name TO new_name;
旧表(old_name)必须存在,新表(new_name)必须不存在。如果新表new_name存在,则该语句将失败。
十八、视图VIEW
什么是视图
视图是虚拟的表,与包含数据的表不一样,视图只包含使用时动态检索数据的查询。之前的例子:检索订购了某种产品的顾客
SELECT
cust_name,
cust_contact
FROM Customers AS C, Orders AS O, OrderItems AS OI
WHERE C.cust_id = O.cust_id -- 多个表联结查询
AND OI.order_num = O.order_num
AND prod_id = 'RGAN01'
现在我们将上面的结果包装成一个名ProductsCustomers的虚拟表,可以得到相同的数据:
SELECT cust_name, cust_contact
FROM ProductsCustomers
WHRE prod_id = 'RGAN01'
ProductsCustomers并不是一个表,只是一个视图,它不包含任何列或者数据,包含的是一个查询。
为什么使用视图
总结以下几点使用视图的原因:
重用SQL语句 简化复杂的SQL操作 使用表的一部分而不是整个表 保护数据。可以授予用户访问表的特定部分数据,而不是整个表的数据 更改数据格式和表示、视图可以返回和底层表的表示和格式不同的数据
笔记:视图本身不包含数据,使用的是从别处检索出来的数据。
视图规则和限制
关于视图创建和使用的一些常见规则和限制:
与表一样,视图命名必须唯一 创建视图的数目没有限制 创建视图必须具有足够的访问权限 视图是可以嵌套的 视图不能索引,也不能有关联的触发器或者默认值
创建视图
1、利用视图简化复杂的联结
CREATE VIEW ProductsCustomers AS -- 创建视图
SELECT cust_name, cust_contact
FROM Customers AS C, Orders AS O, OrderItems AS OI
WHERE C.cust_id = O.cust_id
AND OI.order_num = O.order_num
上面 代码创建了一个名为ProductsCustomers的视图,我们查询一条信息:
SELECT cust_name, cust_contact
FROM ProductsCustomers
WHRE prod_id = 'RGAN01'
2、利用视图重新格式化检索出的数据
CREATE VIEW VendorLocations AS -- 创建视图
SELECT RTRIM(vend_name) + ' (' + RTRIM(vend_country) + ')' AS vend_title
FROM Vendors;
-- 从视图中检索数据
SELECT *
FROM VendorLocations;
3、使用视图过滤数据
CREATE VIEW CustomerEmailList AS
SELECT cust_id, cust_name, cust_email
FROM Customers
WHERE cust_email IS NOT NULL;
-- 检索数据
SELECT *
FROM CustomerEmailList;
4、使用视图和计算字段
CREATE VIEW OrderItemExpanded AS -- 创建视图
SELECT
order_num,
prod_id,
quantity,
item_price,
quantity * item_price AS expanded_price
FROM OrderItems;
-- 使用视图查询数据
SELECT *
FROM OrderItemExpanded
WHERE order_num = 2008;
十九、使用存储过程
什么是存储过程
存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象。
存储过程是为了完成特定功能的SQL语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数(需要时)来调用执行。
笔记:简答来说,存储过程就是为以后使用而保存的一条或者多条SQL语句。
为什么要使用存储过程
通过把处理封装在一个易用的单元中,可以简化复杂的操作 存储过程保证里数据的一致性,降低出错可能性 简化对变动的关管理。如果表名、列名或者业务逻辑有变化,那么只需要更改存储过程中的代码,使用它的人员无需知道变化 存储过程通常是以编译过的形式进行存储,所以DBMS处理命令所需的工作量少,提高了性能
笔记:总结存储过程的3个优点:简单、安全、高性能
创建存储过程
MySQL中创建存储过程:
CREATE
[DEFINER = { user | CURRENT_USER }]
PROCEDURE sp_name ([proc_parameter[,...]])
[characteristic ...] routine_body
proc_parameter:
[ IN | OUT | INOUT ] param_name type
characteristic:
COMMENT 'string'
| LANGUAGE SQL
| [NOT] DETERMINISTIC
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
routine_body:
Valid SQL routine statement
[begin_label:] BEGIN
[statement_list]
……
END [end_label]
MYSQL 存储过程中的关键语法
声明语句结束符,可以自定义:
DELIMITER $$
或
DELIMITER //
声明存储过程:
CREATE PROCEDURE demo_in_parameter(IN p_in int)
存储过程开始和结束符号:
BEGIN .... END
变量赋值:
SET @p_in=1
变量定义:
DECLARE l_int int unsigned default 40000;
创建MySQL存储过程、存储函数:
CREATE procedure 存储过程名(参数)
存储过程体:
CREATE function 存储函数名(参数)
创建一个实际的存储过程:
mysql> delimiter $$ -- 将语句的结束符号从分号;临时改为两个$$(可以是自定义)
mysql> CREATE PROCEDURE delete_matches(IN p_playerno INTEGER)
-> BEGIN
-> DELETE FROM MATCHES
-> WHERE playerno = p_playerno;
-> END$$
Query OK, 0 rows affected (0.01 sec)
mysql> delimiter; -- 将语句的结束符号恢复为分号
执行存储过程
EXECUTE AddNewProduct('JS01',
'Stuffed Eiffel Tower',
9.83,
'Plush stuffed toy with the text La Tour Tower'
)
关键词是 EXECUTE,后面紧跟的是存储过程的名字名字后面有4个参数 作用:这个存储过程将行添加到Products表中,并将传入的属性赋给相应的列
二十、管理事务处理
这一章介绍的是MySQL中事务的相关知识点,包含什么是事务处理,怎样利用COMMIT 和 ROLLBACK语句管理事务处理
事务处理
事务Transaction,一个最小的、不可再分的工作单元,通常一个事务对应一个完整的业务。InnoDB引擎是支持事务的,MyISAM不支持事务。事务是针对数据库中DML数据操作语言的。
事务处理(transaction processing)是一种机制,用来管理必须成批执行的SQL操作。利用事务处理,可以保证一组操作不会中途停止,要么完全执行,要么完全不执行,来维护数据库的完整性。
在MySQL中,一条SQL语句就是一个事务。 一个完整的业务需要大量的 DML(insert、update、delete)语句来共同完成。只有DML数据操作语句才有事务。事务保证一组 SQL语句要么全部执行成功,要么全部失败,以此来维护数据库的完整性。如果没有发生错误,整个语句提交到数据库表中;如果发生错误,则进行回退(撤销),将数据库恢复到某个已知且安全的状态
栗子:银行转账业务
比如在两个表中,A(原有400)给B(原有200)转200块钱,包含两个过程:
A转出200,B转进200 只有当两个过程全部完成才算真正的执行了一个完整的事务过程。
update user set fee=200 where id=1; # 语句1
-- 由于断网、安全限制、超出磁盘空间等不可控制原因,下面的语句可能无法成功执行
update user set fee=400 where id=2; # 语句2
语句1的成功执行,并不能将底层数据库中的第一个账户的数据进行修改,只是单纯地记录操作,记录在内存中完成 第二条语句成功执行之后,和底层数据库文件中的数据完成同步 若第二条数据执行失败,清空所有的历史记录
事务相关术语
事务处理相关的术语:
事务transaction:一组SQL语句。只能处理DML语句:insert、update、delete语句 回退rollback:指撤销指定SQL的语句 提交commit:指将未存储的SQL语句结果写入到数据库表;只有进行了commit操作,数据才会从内存中写入磁盘中 保留点savepoint:指事务处理过程中设置的临时占位符plaveholder,可以对它发布回退(与整个事务回退处理不同);保留点越多越好:越多的话,能够更加灵活地处理回退问题
CREATE DATABASE IF NOT EXISTS employees; -- 创建数据库
USE employees;
CREATE TABLE `employees`.`account` ( -- 数据库中创建表account
`id` BIGINT (11) NOT NULL AUTO_INCREMENT,
`p_name` VARCHAR (4),
`p_money` DECIMAL (10, 2) NOT NULL DEFAULT 0,
PRIMARY KEY (`id`) -- 设置主键
) ;
INSERT INTO `employees`.`account` (`id`, `p_name`, `p_money`) VALUES ('1', 'tim', '200'); -- 插入两条记录
INSERT INTO `employees`.`account` (`id`, `p_name`, `p_money`) VALUES ('2', 'bill', '200');
START TRANSACTION; -- 开启事务
SELECT p_money FROM account WHERE p_name="tim"; -- 三条语句必须完整执行
UPDATE account SET p_money=p_money-100 WHERE p_name="tim";
UPDATE account SET p_money=p_money+100 WHERE p_name="bill";
COMMIT TRANSACTION; -- 显式提交
事务四大特性
事务具有四大特点,简称为ACID:
原子性 Atomicity:一个事务中的语句,要么全部成功,要么全部失败。不存在只执行了部分的情况。一致性 Consistency:在事务开始之前或者结束之后,必须保持数据库的一致性。比如上面的栗子中,A减掉200,那么相应的,B一定要加上200。否则数据库中的数据不一致。隔离性 Isolation:当多个用户并发访问数据库,操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。用户的操作之间存在独立性。事务A和B之间具有隔离性。持久性 Durability:事务一旦被提交,对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。事务的成功,是硬盘数据上的更改,不仅是内存上的变化。持久性是事务的保证,是事务结束的标志。
隔离级别
| 隔离级别 | 脏读(Dirty Read) | 不可重复读(NonRepeatable Read) | 幻读(Phantom Read) | 加锁读Locked Read |
|---|---|---|---|---|
| 未提交读(Read uncommitted) | Y | Y | Y | N |
| 已提交读(Read committed) | N | Y | Y | N |
| 可重复读(Repeatable read) | N | N | Y | N |
| 可串行化(Serializable ) | N | N | N | Y |
脏读:未提交读,事务中修改即使没有提交,对其他会话也是可见的,可以读取到未被提交的数据。脏读会导致很多的问题,较少使用 提交读:不可重复读,该级别保证事务如果没有成功执行( commit),事务中的操作不会被其他会话可见。解决了脏读问题,但是会对其他session产生两次不一样的读取结果幻读:会话T1事务中执行一次查询,然后会话T2新插入一行记录,这行记录恰好可以满足T1所使用的查询的条件。然后T1又使用相同 的查询再次对表进行检索,但却看到了事务T2刚才插入的新行。这个新行就称为“幻像”。
查看隔离级别
-- 查看系统隔离级别:
select @@global.tx_isolation;
-- 查看当前会话隔离级别
select @@tx_isolation;
-- 设置当前会话隔离级别
SET session TRANSACTION ISOLATION LEVEL serializable; -- serializable 级别
-- 设置全局系统隔离级别
SET GLOBAL TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; -- READ UNCOMMITTED 可读未提交级别
事务开始和结束标志
开始标志:任何一条DML语句的执行,标志事务开始
结束的标志分为两种:成功结束的标识和失败结束的标识
1、成功结束的标志
commit:提交 将所有的 DML语句的操作历史记录和底层硬盘中的数据进行了同步。只有事务成功执行,硬盘中的数据才会进行修改更新。
2、 失败结束的标识
rollback:回滚 将所有的 DML语句的操作记录进行全部清空。
二十一、使用游标
本章节中讲解的是什么是游标,以及如何使用游标。
什么是游标
SQL检索操作返回一组称为结果集的行,这组返回的行都是与SQL语句相匹配的行(零行或者多行)。
简单地使用SELECT语句,没有办法得到第一行、下一行或者前10行的数据。但是实际中,我们需要在检索出来的行中前进或者后退一行甚至多行,这时候便可以使用游标。
游标是一个存储在DBMS服务器上的数据库存查询,它不是一条SELECT语句,而是被该语句检索出来的结果集。
使用游标
使用游标的几个步骤:
declare:在使用游标之前,必须先进行声明open:一旦声明了游标,就必须打开游标对于填有数据的游标,根据需要取出检索的各行 close:在结束的时候,必须关闭游标;有的DBMS还需要释放游标
创建游标
DECLARE关键词来定义和命名游标
DECLARE CustCursor CURSORVB -- 声明游标
FOR
SELECT * FROM Customers
WHERE cust_email IS NULL;
使用游标
1、OPEN CURSOR语句来打开游标
OPEN CURSOR CustCursor -- 打开游标
2、打开游标之后我们可以使用FETCH语句来访问游标数据了。FETCH指出要检索哪些行?从什么地方开始检索?将它们放于何处?
关闭游标
关闭游标的关键词是close。
游标一旦关闭,如果不再次打开,将无法使用;第二次使用的时候,不需要声明,直接open即可
CLOSE Custcursor
二十二、Python操作游标
下面的内容是个人增加部分,讲解的是如何通过Python的第三方库pymysql操作游标。
连接数据库
使用的是pymysql模块,需要先进行导入
import pymysql
host:主机名或者 IP地址port:默认是 3306user:用户名 passwd: user账户登录mysql的密码db:创建的数据库 charset:防止中文出错,编码格式设置为 charset="utf8"
使用模块的connect()方法进行连接
import pymysql
conn = pymysql.connect(
host=“localhost”, # 主机名
port=3306, # 端口
user="root", # 用户名
passwd="123456", # 密码
db="bookdb", # 数据库名字
charset="utf8") # 指定字符集
操作数据库
Python建立了和数据库的连接,实际上就是建立了一个pymysql.connect()的实例对象,或者称之为连接对象。
Python就是通过连接对象和数据库进行对话。pymysql.connect()实例对象的方法有:
commit:提交数据rollback:如果有权限,取消当前的操作,否则会报错cursor([cursorclass]):返回连接的游标对象,执行SQL语句close():关闭连接
游标对象cur操作方法
| 名称 | 描述 |
|---|---|
| close | 关闭游标 |
| execute | 执行一条SQL语句,可以带上参数;执行之后需要conn.commit(),数据库中才会真正建立 |
| fetchone | 返回一条语句 |
| fetchall | 返回所有的语句 |
| fetchmany | 返回many条语句 |
| nextset() | 移动到下一个结果 |
插入
import pymysql # 导入模块
conn = pymysql.connect(host=“localhost”, # 建立python和数据库的连接
port=3306,
user="root",
passwd="123456",
db="bookdb",
charset="utf8")
cur = conn.cursor() # 建立游标对象cur
cur.execute("insert into users (username, passwd, email) values (%s, %s, %s)", ("python", "123456", "python@gmail.com"))
conn.commit() # 需要再执行conn.commit()
# 同时执行插入多条信息:多条信息用元组的形式表示
cur.executemany("insert into users (username, passwd, email) values (%s, %s, %s)", (("python", "123456", "python@gmail.com"), ("java", "456789", "java@gmail.com"), ("php", "123789", "php@gmail.com")))
conn.commit() # 需要再执行conn.commit()
查询
>>cur.execute("select * from users")
>>lines = cur.fetchall() # 返回所有的查询结果
>>for line in lines: # 遍历返回所有的结果
print(line)
# 只想返回一条结果
>>cur.execute("select * from users where id=1") # 查询id=1
>>cur.execute("select * from users")
>>cur.fetchone() # 返回一条结果;游标会跟着移动,直到将所有的数据取完
>>cur.fetchone()
>>cur.fetchone()
游标移动 scroll到指定位置操作存储在内存中的对象时候游标会移动,可以指定游标到某个位置:
>>cur.scroll(2) # 相对于当前位置移动2个单位
>>cur.fetchone() # 显示数据
>>cur.scroll(2, "absolute") # 加上参数,实现“绝对移动”,到第三条
绝对移动的数字不能是负数,相对移动可以是负数
Python的连接对象的游标方法中提供一个参数,将读取到的数据保存成字典形式:
>>cur = conn.cursor(pymysql.cursors.DictCursor)
>>cur.execute("select * from users")
>>conn.commit() # 需要再执行conn.commit()
>>cur.fetchall()
更新
>>cur.execute("update users set username=s% where id=2", ("mypython")) # 更新第二条语句
>>cur.execute("select * from users where id=2")
>>conn.commit() # 需要再执行conn.commit()
>>cur.fetchone()
二十三、SQL高级特性
在最后的一章中简单的介绍了SQL的3个高级特性:
约束constraint 索引index 触发器trigger
约束
约束是管理如何插入或者处理数据库数据的规则。DBMS通过在数据库表上施加约束来实施引用完整性。
1、主键
主键是一种特殊的约束,用来保证一列(或者一组列)中的值是唯一的。主键必须满足的4个条件:
任意两行的主键值不相同 每行都具有一个主键值,即列中不允许NULL值 包含主键的列从不修改或者更新 主键值不能重复用
-- 方式1
CREATE TABLE Vendors(
vend_id char(10) NOT NULL primary key, -- 添加主键
vend_name char(50) NOT NULL,
vend_address char(50) NULL,
vend_city char(50) NULL,
vend_state char(5) NULL,
vend_zip char(10) NULL,
vend_country char(50) NULL
);
-- 方式2
ALTER TABLE Vendors
ADD CONSTRAINT PRIMARY KEY (vend_id);
2、外键
外键值表中的一列,其值必须列在另一表的主键中。外键是保证引用完整性的重要部分。
通过订单信息表Orders表中的顾客ID和顾客信息表Customers的顾客ID进行关联。
CREATE TABLE Orders
(
order_num INTEGER NOT NULL PRIMARY KEY, -- 主键:订单号唯一
order_date DATETIME NOT NULL,
cust_id CHAR(10) NOT REFERENCES -- 外键:顾客id不唯一,一个顾客可能有多个订单
)
3、唯一约束
唯一约束用来保证一列中的数据是唯一的,可以通过关键词UNIQUE来定义。它和主键的区别在于:
表中可以包含多个唯一约束,但是只能有一个主键 唯一约束列可以包含NULL值 唯一约束列可以修改或者更新 唯一约束列的值可以重复使用 与主键不同,唯一约束不能用来定义外键
4、检查约束
检查约束用来保证一列(或者一组列)中的数据满足一组指定的条件,常见的用途有:
检查最大值或者最小值 指定数据的范围 只允许特定的值,例如性别字段中只允许M或者F
CREATE TABLE OrderItems
(
order_num INTEGER NOT NULL,
order_item INTEGER NOT NULL,
prod_id CHAR(10) NOT NULL,
quantity INTEGER NOT NULL CHECK (quantity>0), -- 设置检查约束,保证大于0
item_price MONEY NOT NULL
)
索引index
索引用来排序数据以加快搜索和排序操作的速度。创建索引前记住几点:
索引改善检索操作的性能,但是降低了数据插入、修改和删除的性能 索引数据可能要占用大量的存储空间 索引用于数据过滤和数据排序 可以在索引中定义多个列 索引必须唯一命名
CREATE INDEX prod_name_ind
ON Products (prod_name);
触发器trigger
触发器(trigger):监视某种情况,并触发某种操作,它是提供给程序员和数据分析员来保证数据完整性的一种方法,它是与表事件相关的特殊的存储过程,它的执行不是由程序调用,也不是手工启动,而是由事件来触发。
触发器可以与特定表上INSERT、UPDATE、DELETE操作相关联。触发器的常见用途:
保证数据一致 基于某个表的变动在其他表上执行活动 进行额外的验证并根据需要回退数据 计算计算列的值或者更新时间戳
触发器创建语法四要素:
监视地点(table) 监视事件(insert/update/delete) 触发时间(after/before) 触发事件(insert/update/delete)
笔记:触发器只能创建在永久表上,而不能对临时表创建触发器
触发器创建的基本语法如下
CREATE TRIGGER trigger_name
AFTER/BEFORE INSERT/UPDATE/DELETER ON table_name
FOR each row -- 固定语句
begin
sql语句;
end;
二十四、总结
《SQL必知必会》一本非常经典的数据库书籍,也可以说是自己入门数据库的书。算上本次万字精华整理,应该是第三次系统的阅读本书,本书主要有几个特点:
知识全面:书中囊括了很多的数据库知识,从最基础的创建库表到联结查询,再到数据库的视图、触发器等,有基础也有提升 案例丰富:本书的讲解主要是通过5个不同表来完成,结合各种案例来说明SQL的使用细节 对比性强:不同的DBMS系统的语法是有一定出入的,本书在讲解的过程中针对不同DBMS,给出不同的写法,主要还是MySQL
附录
本书中涉及到的5张表及其字段含义:

--END--
扫码即可加我微信
老表朋友圈经常有赠书/红包福利活动