
ge-to-Image Translat卡内基梅隆大学新作!基于MLP架构的Imaion
点击下方“AI算法与图像处理”,关注一下
重磅干货,第一时间送达

CVPR2021 很多成果基于之前大火的transformer,但是由于transformer的计算量太大了,最近基于 MLP 架构的模型又重新进入大众的视野,后续可能会有更多相关研究。后续会继续分享相关内容,欢迎持续关注哈!
CVPR2021论文下载链接:
CVPR 2021 全部论文链接公布!最新1660篇论文合集!附下载链接
论文链接:https://arxiv.org/pdf/2105.14110.pdf
摘要
虽然基于注意的 transformer 网络在几乎所有语言任务中都取得了无与伦比的成功,但是大量的标记加上二次激活记忆的使用使得它们对于视觉任务来说是望而却步的。因此,虽然语言到语言的转换因transformer模式而发生了革命性的变化,卷积网络仍然是图像到图像转换的事实上的解决方案。最近提出的 MLP-Mixer 架构缓解了一些与基于注意的网络相关的速度和内存问题,同时仍然保留了使transformer模型成为理想的远程连接。利用这种有效的替代自我注意的方法,我们提出了一种新的非配对图像到图像的转换模型MixerGAN:一种更简单的基于MLP的体系结构,它考虑了像素之间的远距离关系,而不需要昂贵的注意机制。定量和定性分析表明,MixerGAN实现了竞争的结果相比,以前的卷积为基础的方法。
主要贡献
表明MLP-Mixer 体系结构可以适应于有效地执行未配对图像到图像的转换,同时以比transformer模型低得多的成本考虑长范围的依赖性。

MixerGAN
我们表明,MLP-Mixer 块提供了一种执行未配对图像到图像转换的替代方法,该方法考虑了普通卷积块不可能实现的全局关系,并且在计算上比transformer块少。
形式上,我们的目标是训练两个基于 Mixer 的生成器G:X→ Y 和 F: Y→X, 在两个之间“转换”图像。我们通过同时训练两个判别器Dx和Dy来区分真实图像和生成图像,从而实现了与原始CycleGAN相同的方法。
训练目标
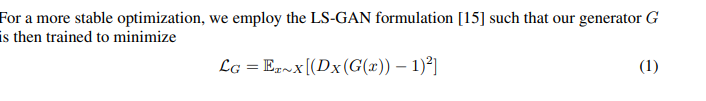
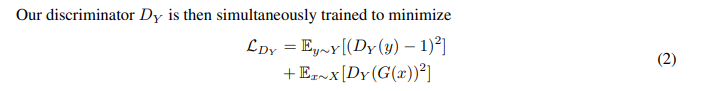

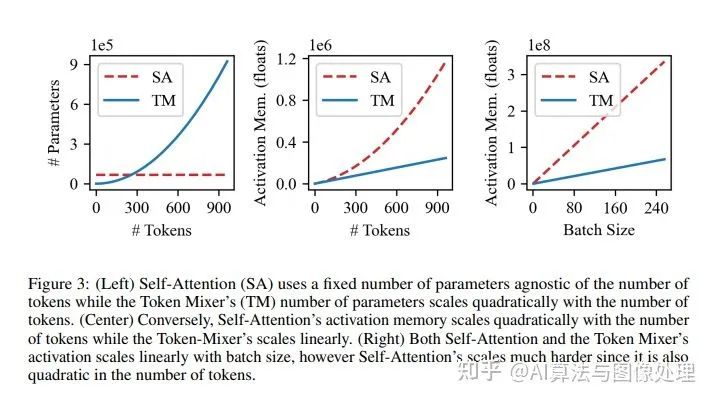
计算上的优势
1、如开创性论文[24]所述,MLP-Mixer的核心是一个具有非常具体的结构参数。因此,MLP-Mixer 可以利用现有的GPU 允许以极高效率执行卷积运算的体系结构和实现,而基于注意的网络目前受到gpu执行未优化注意运算的速度的限制
2、MLP Mixer和transformer块的内存使用情况不同
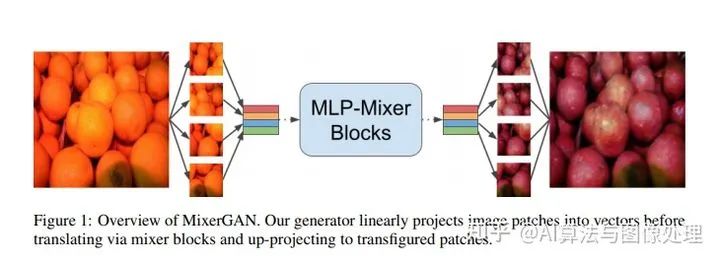
模型架构
网络与原始 CycleGAN 又相似的大小。虽然 mixer 模块比卷积模块有更多的参数,但我们的mixer模型仍然具有相同数量的非线性,并且即使不是低维的潜在空间,也具有可比性。
根据最初的CycleGAN,我们基于mixer的生成器由单层卷积干和两个阶梯卷积层组成,用于学习下采样。生成器的变换部分由9个各向同性混合块组成。最后,变换部分之后是两个上采样转置卷积和一个最终卷积,以将表示重新映射到源维度。对于我们的鉴别器,我们用vanilla PatchGAN[9]和mixer 增强网络进行了实验。
mixer 块本身直接遵循MLP-mixer 论文[24]中给出的公式。在patch projection步骤之后,标记被堆叠为列,使得表示X现在仅是二维的。mixer块本身由两个多层感知器组成:一个用于token mixing,另一个用于channel mixing。token mixing MLP作用于表示的列,而channel mixing MLP作用于其通道。注意,典型的transformer架构包含channel mixing MLP,但是执行自注意操作来代替令牌混合MLP。MLP-mixer 块的总体架构如图1所示。
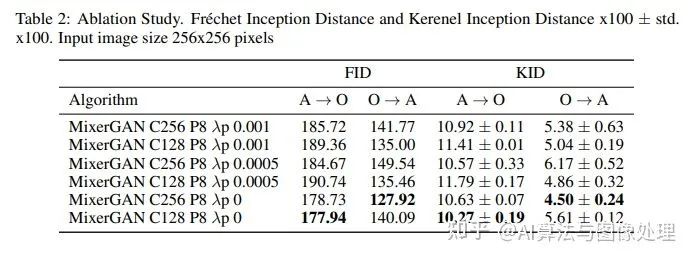
实验部分
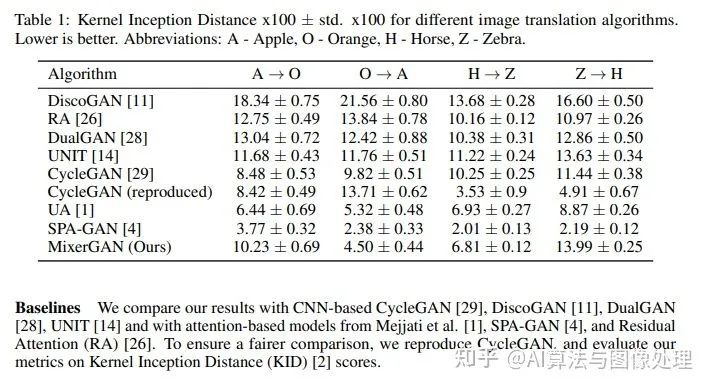
结果

Failure Modes and Limitations
MixerGAN模型的最大限制因素似乎来自于 patch projection 步骤。
考虑到patch projection步骤的局限性,我们有时会在生成的图像中发现“patch”伪影,如图6所示。我们假设,在patch projection步骤之后,更多的通道将有助于通过阻止此时的信息丢失来缓解这种伪影问题。在转换阶段,一个不太完整的表达在理想情况下会导致更少的压缩和更具表现力的模型。不幸的是,由于我们有限的计算能力,我们无法在这个时候试验更广泛的网络。
结论
在这项工作中,我们已经证明了MLP混合器也是一种有效的生成模型体系结构,特别是非配对图像到图像的转换。我们假设增加潜在空间中的通道数将减少任何补丁伪影,并希望在未来获得计算资源来评估这一点。
像所有的图像合成应用程序一样,MixerGAN有可能被用于潜在的恶意目的,比如deepfakes[18]。因此,合成图像检测仍然是其自身的一个重要领域。然而,这不应阻止我们继续研究图像合成,因为打击威胁的最佳方法是彻底了解它。
经过几十年的卷积神经网络(以及最近的transformer网络)主导了计算机视觉领域,一个简单的加权mlp序列可以有效地执行相同的任务,这是值得注意的。既然我们已经证明MLP-mixer器在生成目标上取得了成功,那么改进这种技术并将基于MLP的体系结构扩展到进一步的图像合成任务的大门就敞开了。
努力分享优质的计算机视觉相关内容,欢迎关注:
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021
在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看