
AlphaCode 惊世登场!编程版“阿法狗”悄悄参赛,击败一半程序员
Java后端技术
共 5437字,需浏览 11分钟
· 2022-02-14
往期热门文章:
1、被阿里P8面了两个小时,技术、业务有来有回...... 2、再见丑陋的 SwaggerUI,这款API文档生成神器界面更炫酷,逼格更高! 3、员工春节加班猝死!反转了,B站深夜发长文回应! 4、1 个月崩 3 次!盘点一下 2021 年的 10 个宕机名场面 5、这类视频遭破解,大量上传B站,行为恶劣!
来源:机器之心
世界本来已经很卷,有了 AI 加入之后,卷上加卷……

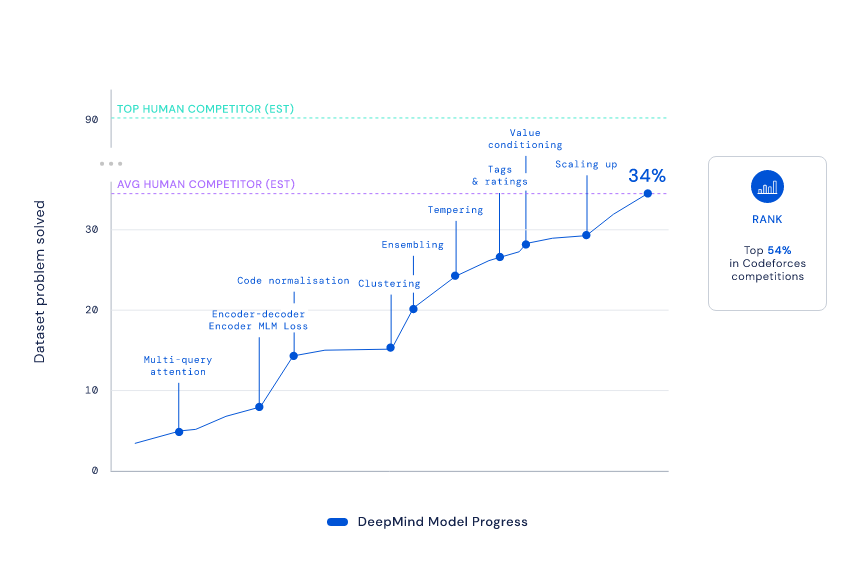


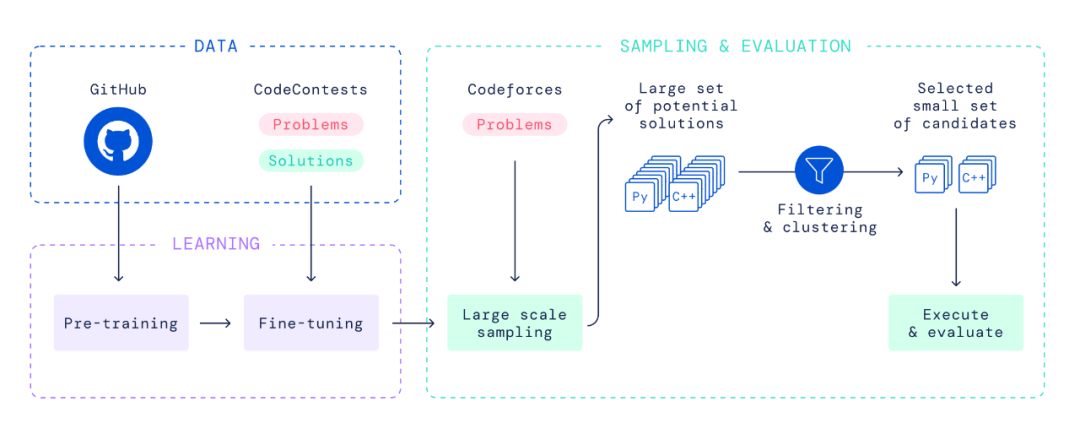
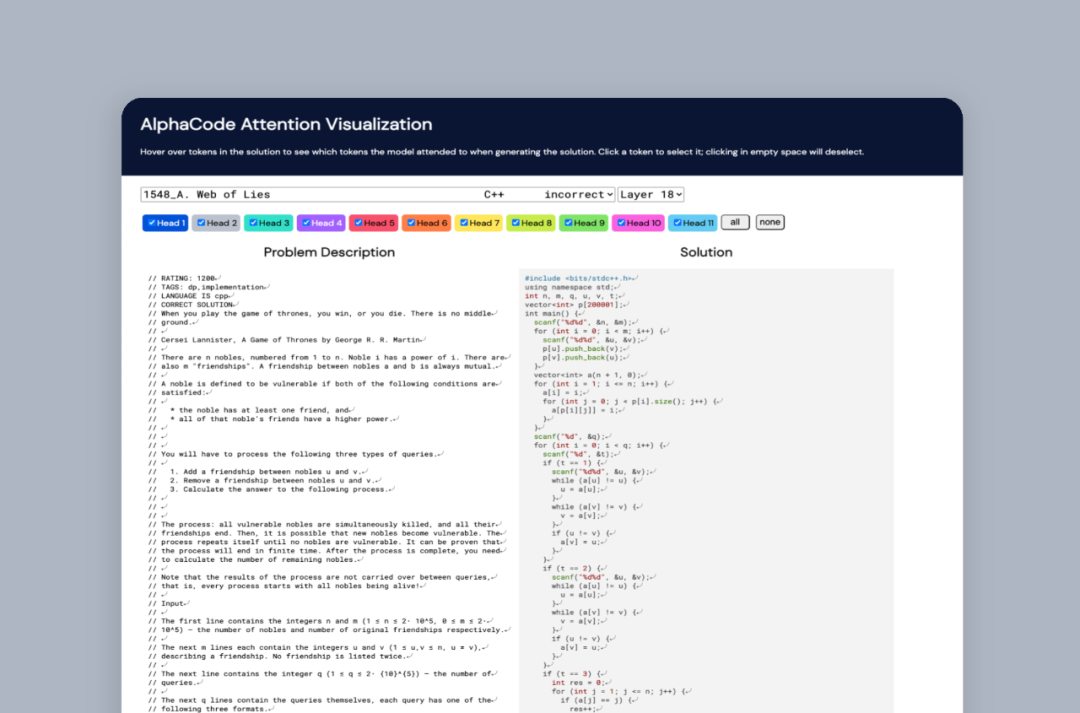

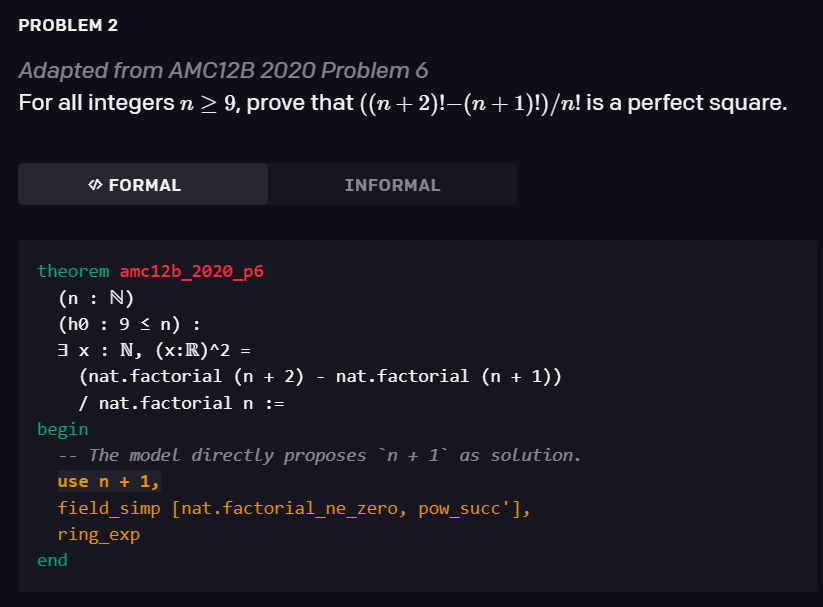
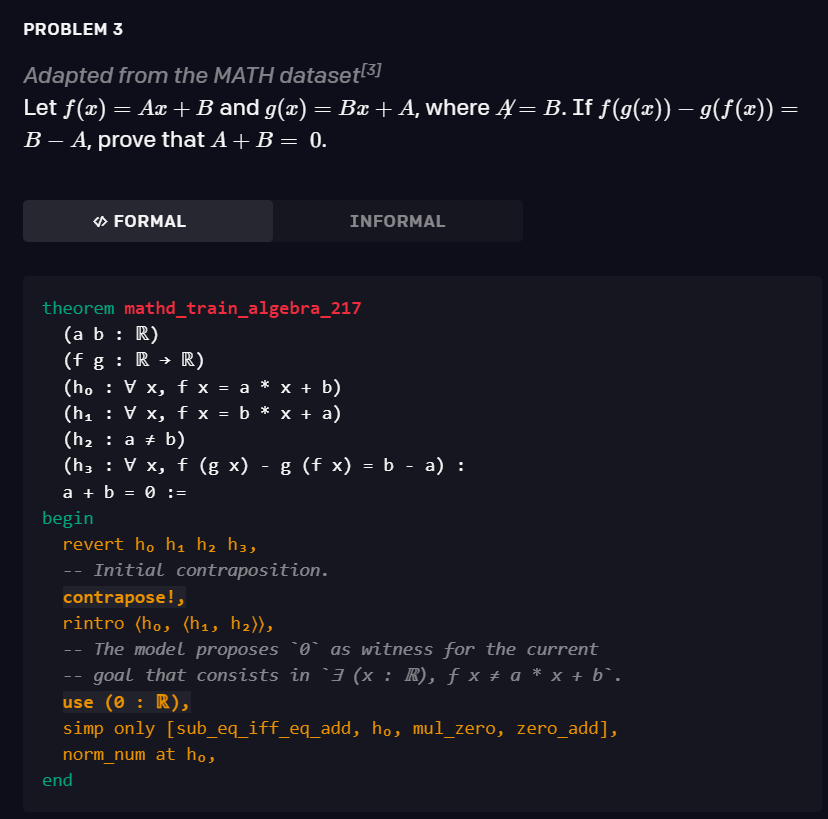
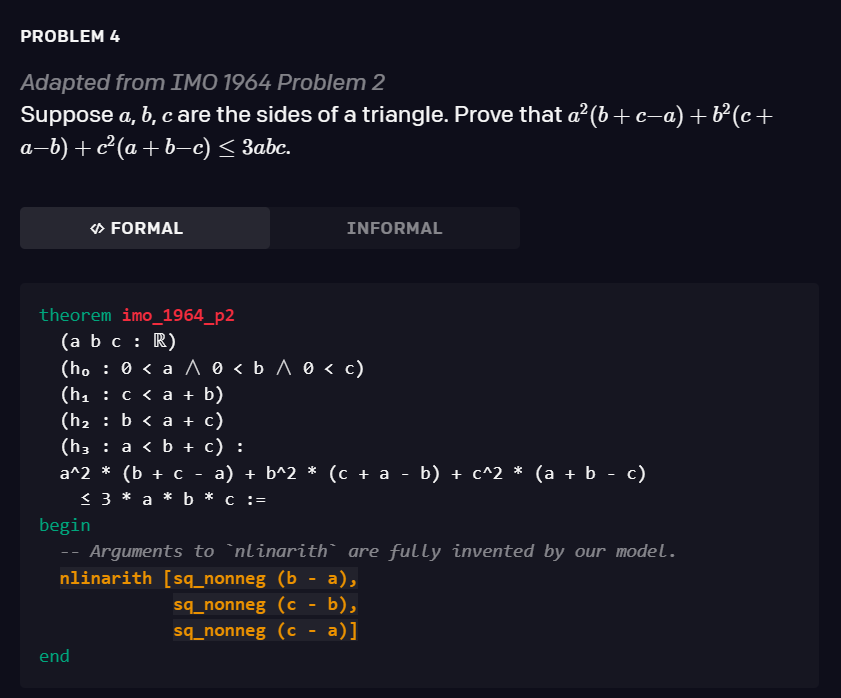
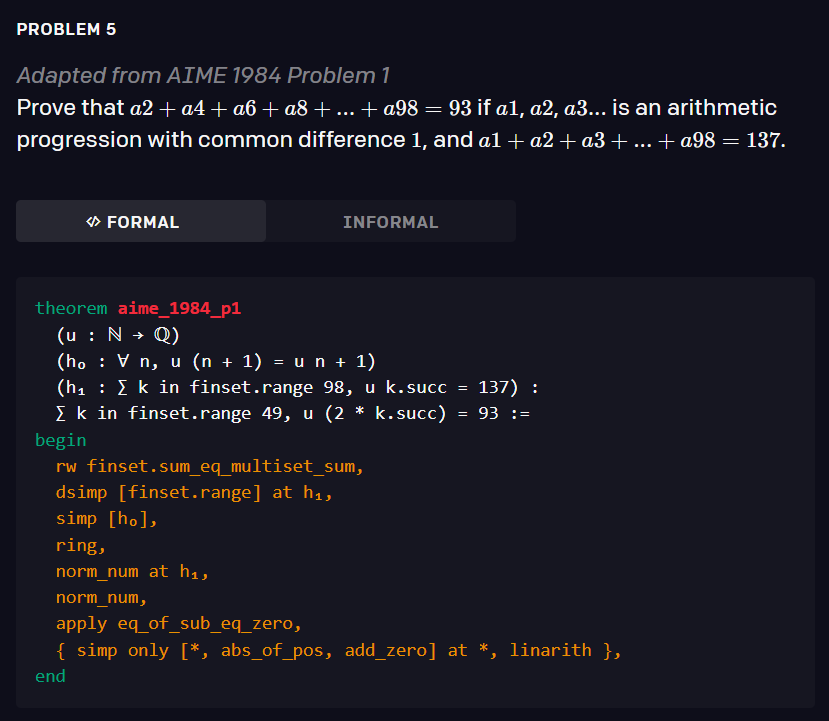
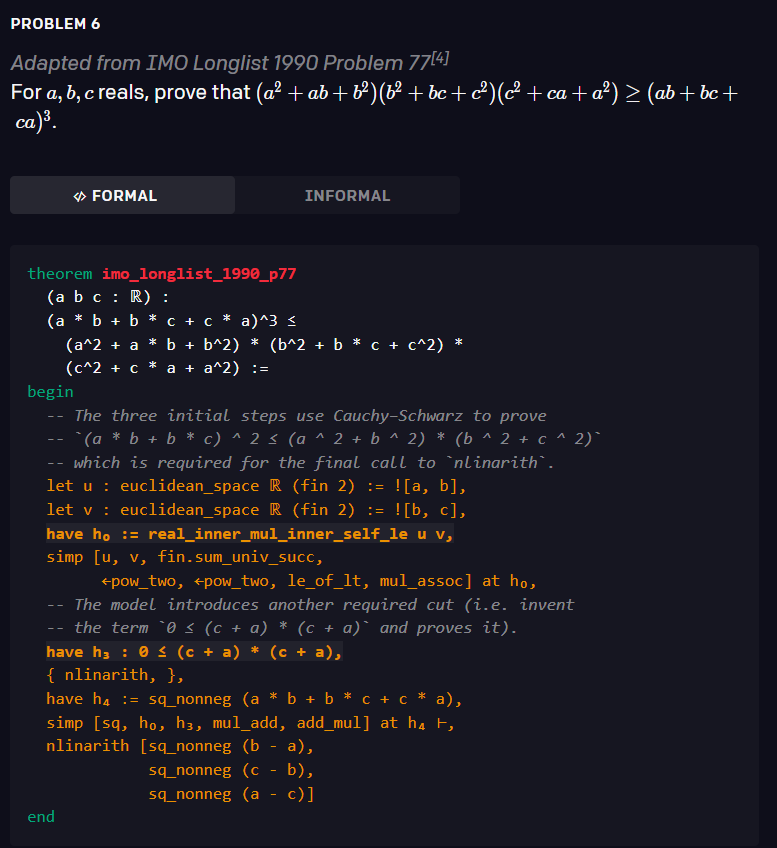

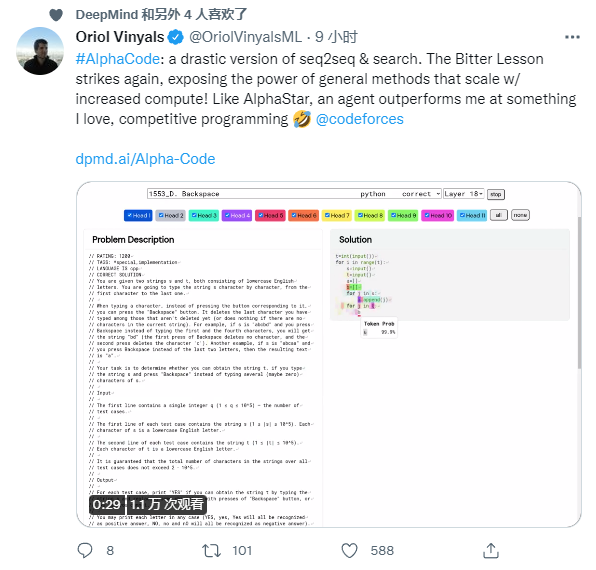
1、滴滴程序员被亲戚鄙视:年薪八十万还不如二本教书的... 2、IT界惊现文豪!华为领导及阿里P10遭吐槽
3、上海地铁乘车码“变红”,吓倒一众乘客,官方:为营造节日气氛…… 4、Spring Boot 项目打成 .exe 程序?实战来了! 5、Spring Boot太重,Vert.x真香! 6、中美程序员不完全对比 7、Spring Boot 3.0 M1 发布,正式弃用 Java 8,最低要求 Java 17。。。 8、一个“扛住100亿次请求”的春晚红包系统 9、你觉得HTTPS能防止重放攻击吗? 10、数据一致性,为什么不推荐双写?
评论
新场乡新场村
新场村位于新场乡政府所在地的周围,东与戛纳村为邻,西与下街村相连,南与高峰村相邻,北与仓脚村接壤。地处高寒山区,全村共有17个村民小组,总人口3825人,其中农业人口3556人,非农业人口269人。由
新场乡新场村
0
龙坪乡新场垭村
新场垭村辖区面积6.24平方公里,133户,514人,耕地面积477亩。上年度农民人均纯收入6303元。党员队伍建设情况:党员总数19人,其中妇女党员3人,25岁以下党员1人,26—35岁党员2人,3
龙坪乡新场垭村
0
龙水乡新场村
新场村是一个边远的农业大村,位于龙水乡南面,距政府所在地10公里,距开阳县城46公里,全村辖27个村民组、1338户、4448人,有耕地5014亩。村总面积24.39平方公里,平均海拔1100米,平均
龙水乡新场村
0