
Go 每日一库之 tunny
简介
之前写过一篇文章介绍了ants这个 goroutine 池实现。当时在网上查看相关资料的时候,发现了另外一个实现tunny。趁着时间相近,正好研究一番。也好比较一下这两个库。那就让我们开始吧。
快速开始
本文代码使用 Go Modules。
创建目录并初始化:
$ mkdir tunny && cd tunny
$ go mod init github.com/darjun/go-daily-lib/tunny
使用go get从 GitHub 获取tunny库:
$ go get -u github.com/Jeffail/tunny
为了方便地和ants做一个对比,我们将ants中的示例重新用tunny实现一遍:还是那个分段求和的例子:
const (
DataSize = 10000
DataPerTask = 100
)
func main() {
numCPUs := runtime.NumCPU()
p := tunny.NewFunc(numCPUs, func(payload interface{}) interface{} {
var sum int
for _, n := range payload.([]int) {
sum += n
}
return sum
})
defer p.Close()
// ...
}
使用也非常简单,首先创建一个Pool,这里使用tunny.NewFunc()。
第一个参数为池子大小,即同时有多少个 worker (也即 goroutine)在工作,这里设置成逻辑 CPU 个数,对于 CPU 密集型任务,这个值设置太大无意义,反而有可能导致 goroutine 切换频繁而降低性能。
第二个参数传入一个func(interface{})interface{}的参数作为任务处理函数。后续传入数据就会调用这个函数处理。
池子使用完需要关闭,这里使用defer p.Close()在程序退出前关闭。
然后,生成测试数据,还是 10000 个随机数,分成 100 组:
nums := make([]int, DataSize)
for i := range nums {
nums[i] = rand.Intn(1000)
}
处理每组数据:
var wg sync.WaitGroup
wg.Add(DataSize / DataPerTask)
partialSums := make([]int, DataSize/DataPerTask)
for i := 0; i < DataSize/DataPerTask; i++ {
go func(i int) {
partialSums[i] = p.Process(nums[i*DataPerTask : (i+1)*DataPerTask]).(int)
wg.Done()
}(i)
}
wg.Wait()
调用p.Process()方法,传入任务数据,池子中会选择空闲的 goroutine 来处理这个数据。由于我们上面设置了处理函数,goroutine 会直接调用该函数,将这个切片作为参数传入。
tunny与ants不同的是,tunny的任务处理是同步的,即调用p.Process()方法之后,当前 goroutine 会挂起,直到任务处理完成之后才会被唤醒。由于是同步的,所以p.Process()方法可以直接返回处理结果。这也是上面程序在分发任务的时候,启动多个 goroutine 的原因。如果不是每个任务都启动一个 goroutine,p.Process()方法会一直等待任务完成,那么后面的任务要等到前面的任务全部执行完之后才能执行。这样就发挥不了并发的优势了。
这里注意一个小细节,我将for循环变量作为参数传给 goroutine 函数了。如果不这样做,所有 goroutine 都共用外层的i,而且 goroutine 开始运行时,for循环大概率已经结束了,这时i = DataSize/DataPerTask,索引nums[i*DataPerTask : (i+1)*DataPerTask]会越界触发 panic。
最后统计数据,验证结果:
var sum int
for _, s := range partialSums {
sum += s
}
var expect int
for _, num := range nums {
expect += num
}
fmt.Printf("finish all tasks, result is %d expect:%d\n", sum, expect)
运行:
$ go run main.go
finish all tasks, result is 5010172 expect:5010172
超时
默认情况下,p.Process()会一直阻塞直到任务完成,即使当前没有空闲 worker 也会阻塞。我们也可以使用带超时的Process()方法:ProcessTimed()。传入一个超时时间间隔,如果超过这个时间还没有空闲 worker,或者任务还没有处理完成,就会终止,并返回一个错误。
超时有 2 种情况:
等不到空闲的 worker:所有 worker 一直处理繁忙状态,正在处理的任务比较耗时,无法短时间内完成; 任务本身比较耗时。
下面我们编写一个计算斐波那契的函数,使用递归这种低效的实现方法:
func fib(n int) int {
if n <= 1 {
return 1
}
return fib(n-1) + fib(n-2)
}
我们先看任务比较耗时的情况,创建Pool对象。为了观察更明显,在处理函数中添加了time.Sleep()语句:
p := tunny.NewFunc(numCPUs, func(payload interface{}) interface{} {
n := payload.(int)
result := fib(n)
time.Sleep(5 * time.Second)
return result
})
defer p.Close()
生成与池容量相等的任务数,调用p.ProcessTimed()方法,设置超时为 1s:
var wg sync.WaitGroup
wg.Add(numCPUs)
for i := 0; i < numCPUs; i++ {
go func(i int) {
n := rand.Intn(30)
result, err := p.ProcessTimed(n, time.Second)
nowStr := time.Now().Format("2006-01-02 15:04:05")
if err != nil {
fmt.Printf("[%s]task(%d) failed:%v\n", nowStr, i, err)
} else {
fmt.Printf("[%s]fib(%d) = %d\n", nowStr, n, result)
}
wg.Done()
}(i)
}
wg.Wait()
因为处理函数中 sleep 5s,所以任务在执行过程中就超时了。运行:
$ go run main.go
[2021-06-10 16:36:26]task(7) failed:job request timed out
[2021-06-10 16:36:26]task(4) failed:job request timed out
[2021-06-10 16:36:26]task(1) failed:job request timed out
[2021-06-10 16:36:26]task(6) failed:job request timed out
[2021-06-10 16:36:26]task(5) failed:job request timed out
[2021-06-10 16:36:26]task(0) failed:job request timed out
[2021-06-10 16:36:26]task(3) failed:job request timed out
[2021-06-10 16:36:26]task(2) failed:job request timed out
都在同一秒中超时。
我们将任务数量翻倍,再将处理函数中的 sleep 改为 990ms,保证前一批任务能顺利完成,后续任务或者由于等不到空闲 worker,或者由于执行时间过长而超时返回。运行:
$ go run main.go
[2021-06-10 16:42:46]fib(11) = 144
[2021-06-10 16:42:46]fib(25) = 121393
[2021-06-10 16:42:46]fib(27) = 317811
[2021-06-10 16:42:46]fib(1) = 1
[2021-06-10 16:42:46]fib(18) = 4181
[2021-06-10 16:42:46]fib(29) = 832040
[2021-06-10 16:42:46]fib(17) = 2584
[2021-06-10 16:42:46]fib(20) = 10946
[2021-06-10 16:42:46]task(5) failed:job request timed out
[2021-06-10 16:42:46]task(14) failed:job request timed out
[2021-06-10 16:42:46]task(8) failed:job request timed out
[2021-06-10 16:42:46]task(7) failed:job request timed out
[2021-06-10 16:42:46]task(13) failed:job request timed out
[2021-06-10 16:42:46]task(12) failed:job request timed out
[2021-06-10 16:42:46]task(11) failed:job request timed out
[2021-06-10 16:42:46]task(6) failed:job request timed out
context
context 是协调 goroutine 的工具。tunny支持带context.Context参数的方法:ProcessCtx()。当前 context 状态变为Done之后,任务也会停止执行。context 会由于超时、取消等原因切换为Done状态。还是拿上面的例子:
go func(i int) {
n := rand.Intn(30)
ctx, cancel := context.WithCancel(context.Background())
if i%2 == 0 {
go func() {
time.Sleep(500 * time.Millisecond)
cancel()
}()
}
result, err := p.ProcessCtx(ctx, n)
if err != nil {
fmt.Printf("task(%d) failed:%v\n", i, err)
} else {
fmt.Printf("fib(%d) = %d\n", n, result)
}
wg.Done()
}(i)
其他代码都一样,我们调用p.ProcessCtx()方法来执行任务。参数是一个可取消的Context。对于序号为偶数的任务,我们启动一个 goroutine 在 500ms 之后cancel()掉这个Context。代码运行结果如下:
$ go run main.go
task(4) failed:context canceled
task(6) failed:context canceled
task(0) failed:context canceled
task(2) failed:context canceled
fib(27) = 317811
fib(25) = 121393
fib(1) = 1
fib(18) = 4181
我们看到偶数序号的任务都被取消了。
源码
tunny的源码更少,除去测试代码和注释,连 500 行都不到。那么就一起来看一下吧。Pool结构如下:
// src/github.com/Jeffail/tunny.go
type Pool struct {
queuedJobs int64
ctor func() Worker
workers []*workerWrapper
reqChan chan workRequest
workerMut sync.Mutex
}
Pool结构中有一个ctor字段,这是一个函数对象,用于返回一个实现Worker接口的值:
type Worker interface {
Process(interface{}) interface{}
BlockUntilReady()
Interrupt()
Terminate()
}
这个接口不同的方法在任务执行的不同阶段调用。最重要的当属Process(interface{}) interface{}方法了。这个就是执行任务的函数。tunny提供New()方法创建Pool对象,这个方法需要我们自己构造ctor函数对象,使用多有不便。tunny提供了另外两个默认实现closureWorker和callbackWorker:
type closureWorker struct {
processor func(interface{}) interface{}
}
func (w *closureWorker) Process(payload interface{}) interface{} {
return w.processor(payload)
}
func (w *closureWorker) BlockUntilReady() {}
func (w *closureWorker) Interrupt() {}
func (w *closureWorker) Terminate() {}
type callbackWorker struct{}
func (w *callbackWorker) Process(payload interface{}) interface{} {
f, ok := payload.(func())
if !ok {
return ErrJobNotFunc
}
f()
return nil
}
func (w *callbackWorker) BlockUntilReady() {}
func (w *callbackWorker) Interrupt() {}
func (w *callbackWorker) Terminate() {}
tunny.NewFunc()方法使用的就是closureWorker:
func NewFunc(n int, f func(interface{}) interface{}) *Pool {
return New(n, func() Worker {
return &closureWorker{
processor: f,
}
})
}
创建的closureWorker直接将参数f作为任务处理函数。
tunny.NewCallback()方法使用callbackWorker:
func NewCallback(n int) *Pool {
return New(n, func() Worker {
return &callbackWorker{}
})
}
callbackWorker结构中没有处理函数,只能给它发送无参无返回值的函数对象作为任务,它的Process()方法就是执行这个函数。
创建Pool对象后,都是调用它的SetSize()方法,设置 worker 数量。在这个方法中会启动相应数量的 goroutine:
func (p *Pool) SetSize(n int) {
p.workerMut.Lock()
defer p.workerMut.Unlock()
lWorkers := len(p.workers)
if lWorkers == n {
return
}
for i := lWorkers; i < n; i++ {
p.workers = append(p.workers, newWorkerWrapper(p.reqChan, p.ctor()))
}
// 停止过多的 worker
for i := n; i < lWorkers; i++ {
p.workers[i].stop()
}
// 等待 worker 停止
for i := n; i < lWorkers; i++ {
p.workers[i].join()
// -----------------
}
p.workers = p.workers[:n]
}
SetSize()其实在扩容和缩容的时候也会调用。对于扩容,它会创建相应数量的 worker。对于缩容,它会将多余的 worker 停掉。与ants不同,tunny的扩容缩容都是即时生效的。
代码中,我用-----------------标出来的地方我觉得有点问题。对于缩容,因为底层的数组没有变化,workers切片长度缩小之后,数组中后面的元素实际上就访问不到了,但是数组还持有它的引用,算是一种内存泄漏吧。所以稳妥起见最好加上p.workers[i] = nil?
这里创建的 worker 实际上是包装了一层的workerWrapper结构:
// src/github.com/Jeffail/worker.go
type workerWrapper struct {
worker Worker
interruptChan chan struct{}
reqChan chan<- workRequest
closeChan chan struct{}
closedChan chan struct{}
}
func newWorkerWrapper(
reqChan chan<- workRequest,
worker Worker,
) *workerWrapper {
w := workerWrapper{
worker: worker,
interruptChan: make(chan struct{}),
reqChan: reqChan,
closeChan: make(chan struct{}),
closedChan: make(chan struct{}),
}
go w.run()
return &w
}
workerWrapper结构创建之后会立刻调用run()方法启动一个 goroutine:
func (w *workerWrapper) run() {
jobChan, retChan := make(chan interface{}), make(chan interface{})
defer func() {
w.worker.Terminate()
close(retChan)
close(w.closedChan)
}()
for {
w.worker.BlockUntilReady()
select {
case w.reqChan <- workRequest{
jobChan: jobChan,
retChan: retChan,
interruptFunc: w.interrupt,
}:
select {
case payload := <-jobChan:
result := w.worker.Process(payload)
select {
case retChan <- result:
case <-w.interruptChan:
w.interruptChan = make(chan struct{})
}
case _, _ = <-w.interruptChan:
w.interruptChan = make(chan struct{})
}
case <-w.closeChan:
return
}
}
}
每个 worker goroutine 都在尝试向w.reqChan通道中发送一个workRequest结构数据,发送成功之后,从jobChan中获取任务数据,然后调用Worker.Process()方法执行任务,最后将结果发送到retChan通道中。这里其实有好几个交互。需要结合Process()方法来看才更清晰:
func (p *Pool) Process(payload interface{}) interface{} {
request, open := <-p.reqChan
request.jobChan <- payload
payload, open = <-request.retChan
return payload
}
删掉无相关的代码,最后就是上面这样。我们在调用池对象的Process()方法时,尝试从通道reqChan中接收数据,然后将任务数据发送到jobChan通道中,最后从retChan通道中接收结果。与上面的run流程结合来看,实际上在正常执行一个任务时,Pool与workerWrapper有 3 次交互。
观察Pool创建到workerWrapper创建的流程,我们可以看到实际上Pool结构中的reqChan与workerWrapper结构中的reqChan是同一个通道。即workerWrapper启动后,会阻塞在向reqChan通道发送数据上,直到调用了Pool的Process*()方法,从通道reqChan取出数据。Process()方法得到workRequest会向它的jobChan通道中发送任务数据。而workerWrapper.run()方法成功发送数据到reqChan之后就开始等待从jobChan通道中接收数据,这时接收到Process()方法发送过来的数据。开始执行w.worker.Process()方法,然后向retChan通道发送结果数据,Process()方法在成功发送数据到jobChan之后,就开始等待从retChan通道中接收数据。接收成功之后,Process()方法返回,workerWrapper.run()继续阻塞在w.reqChan <-这条语句上,等待处理下一个任务。注意jobChan和retChan都是workerWrapper.run()方法中创建的通道。
那么超时是怎么实现的呢?看方法ProcessTimed()的实现:
func (p *Pool) ProcessTimed(
payload interface{},
timeout time.Duration,
) (interface{}, error) {
tout := time.NewTimer(timeout)
var request workRequest
select {
case request, open = <-p.reqChan:
case <-tout.C:
return nil, ErrJobTimedOut
}
select {
case request.jobChan <- payload:
case <-tout.C:
request.interruptFunc()
return nil, ErrJobTimedOut
}
select {
case payload, open = <-request.retChan:
case <-tout.C:
request.interruptFunc()
return nil, ErrJobTimedOut
}
tout.Stop()
return payload, nil
}
同样地,删除不相干的代码。首先,创建一个timer,超时时间由传入参数指定。后面有 3 个select语句:
等待从 p.reqChan取数据,即等待有 worker 空闲;等待发送数据到 jobChan,即等待 worker 从jobChan取出任务数据;等待从 retChan取数据,即等待 worker 将结果发送到retChan。
第一种情况,如果超时了,说明 worker 都处于繁忙状态,直接返回任务超时。后面两种情况实际上是任务已经开始执行了,但是在规定的时间内没有完成。这两种情况,需要终止任务的执行。我们看到上面调用了workerRequest.interruptFunc()方法,也就是workerWrapper.interrupt()方法:
func (w *workerWrapper) interrupt() {
close(w.interruptChan)
w.worker.Interrupt()
}
这个方法就是简单关闭了interrupteChan通道,然后调用worker对象的Interrupt()方法,默认实现中这个方法都是空的。
interruptChan通道关闭后,goroutine 中等待从jobChan接收数据和等待向retChan发送数据的操作都会取消:
select {
case payload := <-jobChan:
result := w.worker.Process(payload)
select {
case retChan <- result:
case <-w.interruptChan:
w.interruptChan = make(chan struct{})
}
case _, _ = <-w.interruptChan:
w.interruptChan = make(chan struct{})
}
ProcessCtx()实现也是类似的。
最后调用workerWrapper.stop()会关闭closeChan通道,这会导致workerWrapper.run()方法中的for循环跳出,进而执行defer函数中的close(retChan)和close(closedChan):
defer func() {
w.worker.Terminate()
close(retChan)
close(w.closedChan)
}()
这里需要关闭retChan通道是为了防止Process*()方法在等待retChan数据。
closedChan通道关闭后,workerWrapper.join()方法就返回了。
func (w *workerWrapper) join() {
<-w.closedChan
}
Worker几个方法的调用时机:
Process():执行任务时;Interrupt():任务因为超时会被 context 取消时;BlockUntilReady():每次执行新任务前,可能需要准备一些资源;Terminate():workerWrapper.run()中的 defer 函数中,即停止 worker 后。
这些时机在代码中都能清晰地看到。
基于源码,我画了一个流程图:
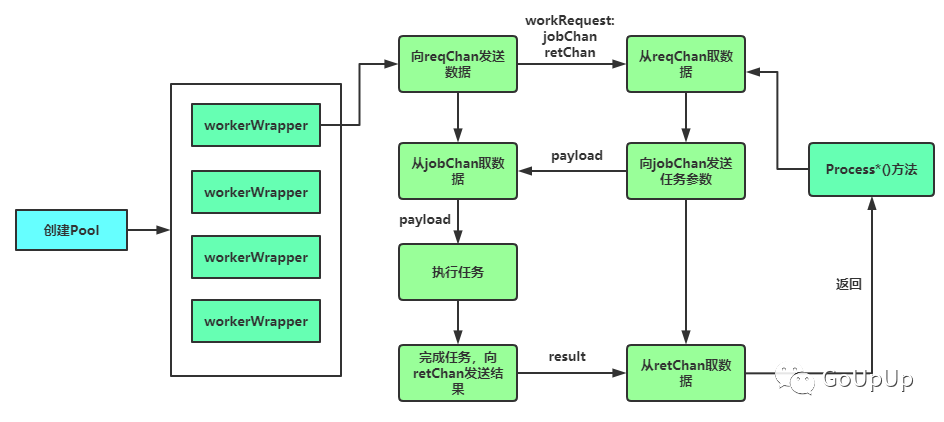
图中省略了中断的流程。
tunny vs ants
tunny设计的思路与ants有较大的区别:
tunny只支持同步的方式执行任务,虽然任务在另一个 goroutine 执行,但是提交任务的 goroutine 必须等待结果返回或超时。不能做其他事情。正是由于这一点,导致tunny的设计稍微一点复杂,而且为了支持超时和取消,设计了多个通道用于和执行任务的 goroutine 通信。一次任务执行的过程涉及多次通信,性能是有损失的。从另一方面说,同步的编程方式更符合人类的直觉。
ants完全是异步的任务执行流程,相比tunny性能是稍高一些的。但是也因为它的异步特性,导致没有任务超时、取消这些机制。而且如果需要收集结果,必须要自己编写额外的代码。
总结
本文介绍了另一个 goroutine 池的实现tunny。它以同步的方式来处理任务,编写代码更加直观,对任务的执行流程有更强的控制,如超时、取消等。当然实现也复杂一些。tunny代码不走 500 行,非常建议读一读。
大家如果发现好玩、好用的 Go 语言库,欢迎到 Go 每日一库 GitHub 上提交 issue😄
参考
tunny GitHub:https://github.com/Jeffail/tunny ants GitHub:github.com/panjf2000/ants Go 每日一库 GitHub:https://github.com/darjun/go-daily-lib
推荐阅读