
推荐系统经典面试题(附答案和解析)!

问题1:召回分支的作用是什么?
解析:快速帮助用户找到可能感兴趣的候选物品;减少排序模型的候选输入,降低系统RT。
问题2:如何离线评价召回阶段各种模型算法的好坏?由于没有明确的召回预期值,所以无论rmse还是auc都不知道该怎么做?
解析:召回最直接的评估就是召回率,也就是召回集里正样本的比例;也可以不同的召回算法+同一个排序算法,还是用排序之后的AUC和RMSE来评估。
问题3:简述Multi-task learning(MLT)多任务学习
解析:在机器学习中,我们通常关心优化某一特定指标,不管这个指标是一个标准值,还是企业KPI。为了达到这个目标,我们训练单一模型或多个模型集合来完成指定得任务。
然后,我们通过精细调参,来改进模型直至性能不再提升。尽管这样做可以针对一个任务得到一个可接受得性能,但是我们可能忽略了一些信息,这些信息有助于在我们关心的指标上做得更好。
具体来说,这些信息就是相关任务的监督数据。通过在相关任务间共享表示信息,我们的模型在原始任务上泛化性能更好。这种方法称为多任务学习(Multi-Task Learning)
问题4:特征选择的方法有哪些?
Filter:过滤法,按照发散性或者相关性对各个特征进行行行评分,设定阈值或者待选择阈值的个数,选择特征。
Wrapper:包装法,根据目目标函数(通常是预测效果评分),每次选择若干干特征,或者排除若干干特征。
Embedded:嵌入入法,先使用用某些机器器学习的算法和模型进行行行训练,得到各个特征的权值系数,根据系数从大大到小小选择特征。类似于Filter方方法,但是是通过训练来确定特征的优劣。
问题5:特征交叉(特征组合)方式有哪些?
1.Dense特征组合
将一个特征与其本身或其他特征相乘(称为特征组合)(二阶或者高阶);
两个特征相除;对连续特征进行分桶,以分为多个区间分箱。
2.ID特征之间的组合
笛卡尔积:假如拥有一个特征A,A有两个可能值{A1,A2}。拥有一个特征B,存在{B1,B2}等可能值。然后,A&B之间的交叉特征
如下:{(A1,B1),(A1,B2),(A2,B1),(A2,B2)},比如经纬度,一个更好地诠释好的交叉特征的实例是类似于(经度,纬度)。
一个相同的经度对应了地图上很多的地方,纬度也是一样。但是一旦你将经度和纬度组合到一起,它们就代表了地理上特定的一块区域,区域中每一部分是拥有着类似的特性。
问题6:阿里最新开源的X-Deep Learning为Online Learning提供了哪些解决方案?
去ID化的稀疏特征学习:传统的机器学习框架一般要求对稀疏特征进行ID化表征(从0开始紧凑编码),以此来保证训练的高效性。XDL则允许直接以原始的特征进行训练,大幅简化了特征工程的复杂度,极大地增加了全链路数据处理效率,这一特性在实时在线学习场景下显得更加有意义。
实时特征频控:用户可以设置一个特征过滤的阈值,例如出现次数大于N次的特征才纳入模型训练,系统会自动的采用自动概率丢弃的算法进行特征选择,这样可以大幅降低无效超低频特征在模型中的空间占用。
过期特征淘汰:长周期的在线学习时,用户也可以通过打开过期特征淘汰功能,系统会自动的对影响力弱且长周期没有碰触到的特征参数进行自动淘汰。
问题7:FTRL在准备训练数据(特征工程)和训练模型时有哪些trick ?
(1)特征工程
特征预处理:ID化、离散化、归一化等;
特征选择:方差、变异系数、相关系数、Information Gain、Information Gain-Ratio、IV值等;特征交叉和组合特征:根据特征具有的业务属性特征交叉,利用FM算法、GBDT算法做高维组合特征等。
(2) Subsampling Training Data
正样本全采样,负样本使用一个比例r采样,并在模型训练的时候,对负样本的更新梯度乘以权重1/r;负采样的方式:随机负采样、Negative sampling、邻近负采样、skip above负采样等。
(3) 在线丢弃训练数据中很少出现的特征(probabilistic feature inclusion)
Poisson Inclusion:对某一维度特征所来的训练样本,以p的概率接受并更新模型;
Bloom Filter Inclusion:用bloom filter从概率上做某一特征出现k次才更新。
问题8:普通的逻辑回归能否用于大规模的广告点击率预估 ,为什么?
不能
第一,数据量太大。传统的逻辑回归参数训练过程都依靠牛顿法(Newton's Method)或者 L-BFGS 等算法。这些算法并不太容易在大规模数据上得以处理。
第二,不太容易得到比较稀疏(Sparse)的答案(Solution)。也就是说,虽然数据中特征的总数很多,但是对于单个数据点来说,有效特征是有限而且稀疏的。
问题9:怎样将知识图谱引入推荐系统 ?
基于特征的知识图谱辅助推荐,核心是知识图谱特征学习的引入。一般而言,知识图谱是一个由三元组<头节点,关系,尾节点> 组成的异构网络。由于知识图谱天然的高维性和异构性,首先使用知识图谱特征学习对其进行处理,从而得到实体和关系的低维稠密向量表示。这些低维的向量表示可以较为自然地与推荐系统进行结合和交互。
基于结构的推荐模型,更加直接地使用知识图谱的结构特征。具体来说,对于知识图谱中的每一个实体,我们都进行宽度优先搜索来获取其在知识图谱中的多跳关联实体从中得到推荐结果。
问题10:Collaborative Knowledge Base Embedding使用哪三种知识的学习?
结构化知识学习:TransR。TransR是一种基于距离的翻译模型,可以学习得到知识实体的向量表示
文本知识学习:去噪自编码器。去噪自编码器可以学习得到文本的一种泛化能力较强的向量表示
图像知识学习:卷积-反卷积自编码器。卷积-反卷积自编码器可以得到图像的一种泛化能力较强的向量表示

— 推荐课程 —
如果你已经拥有一定基础,要挑战高薪或提升自己,可以看下七月在线【推荐系统高级小班 第十一期】课程。
该课程从开设第一期课程开始,持续不断的提升课程质量(包含内容质量、教学质量、服务质量、结果质量:就业 转型 提升),现已迭代至第十一期。
年初抖音推荐算法被MIT评为2021十大突破技术之一,推荐算法不仅催生抖音背后的新一代巨无霸字节跳动,更广泛应用于各大电商平台、视频平台、资讯平台,做推荐的薪资因此水涨船高。
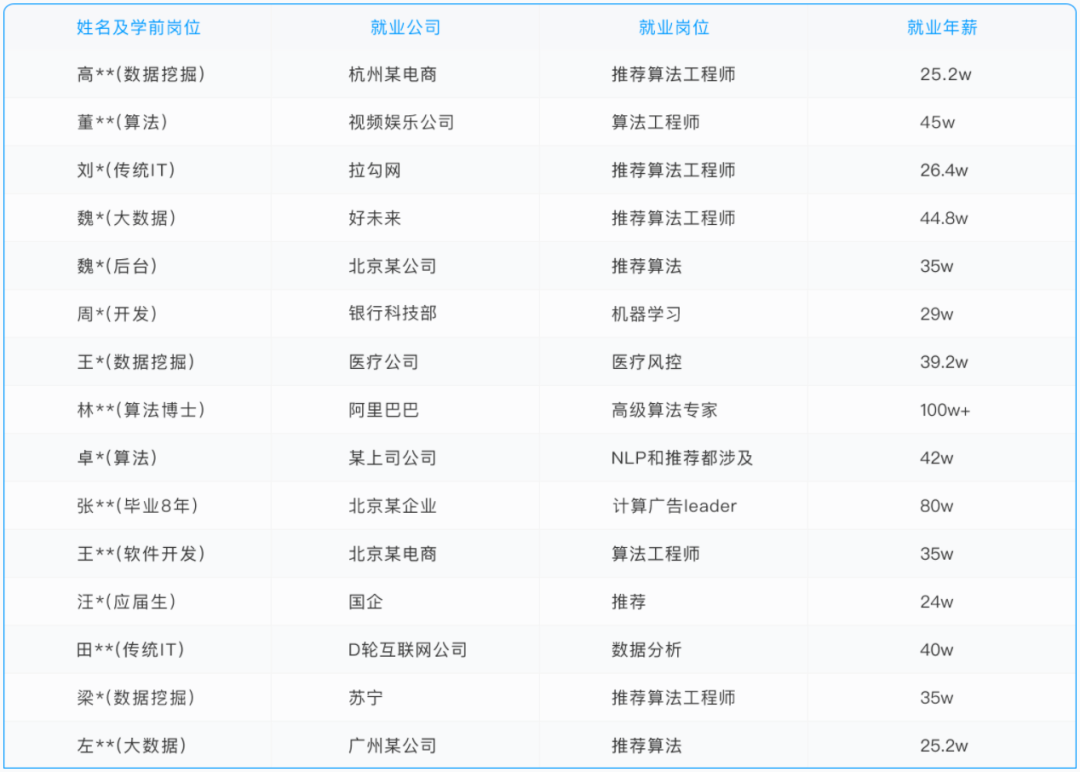
(七月在线部分高级班学员薪资展示)
考虑到网易严选和网易云音乐都有大量的推荐场景,而七月在线则迭代了10期推荐高级班,为了给学员更高的课程质量、更好的教学效果,故本期由网易和七月在线联合研发,除了维持七月在线前十期推荐高级班的三大优势:

内容全面系统:包括推荐常用算法、真实场景推荐、推荐前沿技术等四大阶段的内容;
标准化项目流程:涵盖环境和数据准备、特征工程、模型构建、模型调优、上线部署等;
多对一就业指导:单独指导每个人的就业,包括且不限于简历指导、面试辅导、就业内推;

相比上期,本期在技术阶段新增“2021排序算法发展趋势、基于微信视频号推荐算法的多目标与GNN实战”等内容,至于项目阶段则新增网易内部的两大项目:
网易严选的商品推荐系统,实战演示作为电商APP的网易严选是如何构建推荐系统;
网易云音乐的音乐推荐系统,预测用户在播放了某首歌曲后在未来是否会再次播放,即歌曲复播率预估问题;

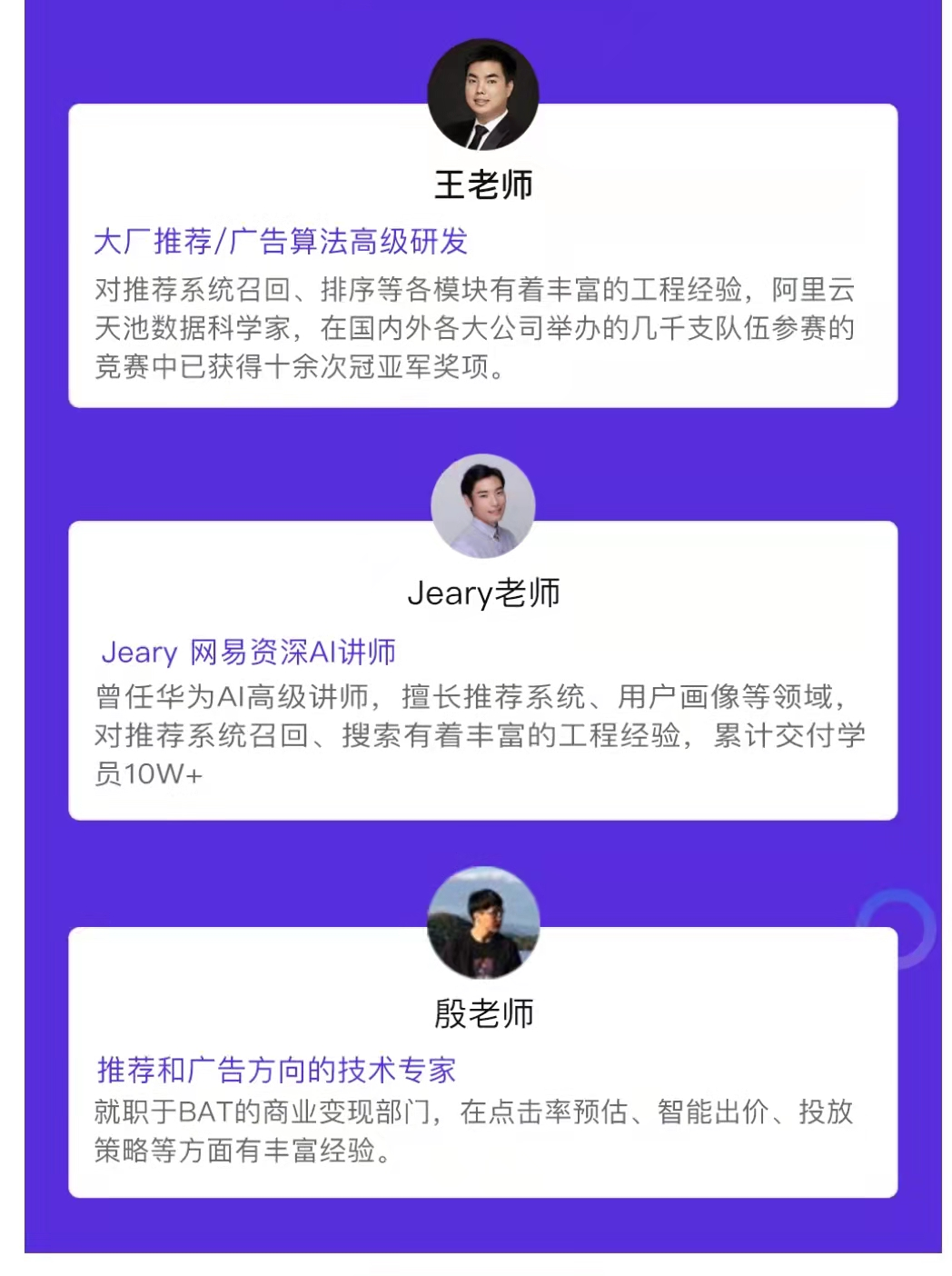
且本期集训营拥有超豪华讲师团队,讲师大多数为国内外知名互联网公司技术骨干或者顶尖院校的专业大牛,学员将在这些顶级讲师的手把手指导下完成学习。
完成项目后,针对学员入职后工作上遇到的技术方面问题,进行一个月的跟踪服务,为学员稳定就业保驾护航。
限时福利
原价21000元的课程,扫码“免费试听 + 领取面试资料《2021最新大厂AI面试题》”。
扫码“领取面试资料+课程试听”