12张图带你彻底理解分布式事务产生的场景和解决方案!!

写在前面
写这篇文章的背景是有个跟我关系不错的小伙伴去某大型互联网公司面试,面试官问了他关于分布式事务的问题,不巧的是他确实对分布式事务掌握的不是很深入,面试的结果挺遗憾的。不过,这位小伙伴还是挺乐观的,让我写写关于【分布式事务】的系列文章,想提升自己关于分布式事务的短板,那我就写一个【分布式事务】专题吧,专题的内容计划是从原理、框架源码到企业级实现,这篇文章也算是整个专题的开篇吧。希望能够为小伙伴们带来实质性的帮助。
本地事务
本地事务流程
在介绍分布式事务之前,我们先来看看本地事务。首先,我们先来一张图。
由上图,我们可以看出,本地事务由资源管理器(比如DBMS,数据库管理系统)在本地进行管理。
本地事务的优缺点
本地事务具备相应的优点,也有其不足。
优点:
支持严格的ACID属性。 可靠,事务实现的效率高(只是在本地操作)。 可以只在RM(资源管理器)中操作事务。 编程模型简单。
缺点:
缺乏分布式事务的处理能力。 数据隔离的最小单元由RM(资源管理器决定),开发人员无法决定数据隔离的最小单元。比如:数据库中的一条记录等。
ACID属性
说起事务,我们不得不提的就是事务的ACID属性。
A(Atomic):原子性,构成事务的所有操作,要么都执行完成,要么全部不执行,不可能出现部分成功部分失 败的情况。 C(Consistency):一致性,在事务执行前后,数据库的一致性约束没有被破坏。比如:张三向李四转100元, 转账前和转账后的数据的正确状态叫作一致性,如果出现张三转出100元,李四账户没有增加100元这就出现了数 据错误,就没有达到一致性。 I(Isolation):隔离性,数据库中的事务一般都是并发的,隔离性是指并发的两个事务的执行互不干扰,一个事 务不能看到其他事务运行过程的中间状态。通过配置事务隔离级别可以避脏读、重复读等问题。 D(Durability):持久性,事务完成之后,该事务对数据的更改会被持久化到数据库,且不会被回滚。
分布式事务
随着业务的快速发展,网站系统往往由单体架构逐渐演变为分布式、微服务架构,而对于数据库则由单机数据库架构向分布式数据库架构转变。此时,我们会将一个大的应用系统拆分为多个可以独立部署的应用服务,需要各个服务之间进行远程协作才能完成事务操作。
我们可以使用下图来表示刚开始我们系统的单体架构。
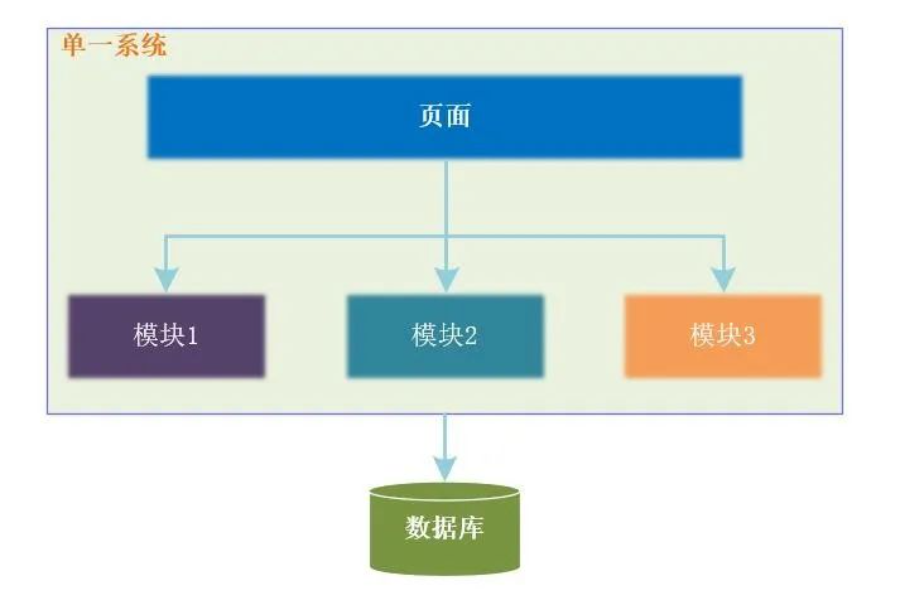
上图中,我们将同一个项目中的不同模块组织成不同的包来进行管理,所有的程序代码仍然是放在同一个项目中。
后续由于业务的发展,我们将其扩展为分布式、微服务架构。此时,我们将一个大的项目拆分为一个个小的可以独立部署的微服务,每个微服务都有自己的数据库,如下所示。
又比如,在我们的程序中,经常会在同一个事务中执行类似如下的代码来完成我们的需求。
@Transactional(rollbackFor = Exception.class)
public void submitOrder() {
orderDao.update(); // 更新订单信息
accountService.update(); // 修改资金账户的金额
pointService.update(); // 修改积分
accountingService.insert(); // 插入交易流水
merchantNotifyService.notify(); // 通知支付结果
}
上述代码中的业务,仅仅在submitOrder()方法上添加了一个@Transactional注解,这能够在分布式场景下避免分布式事务的问题吗?很显然是不行的。
如果上述代码所对应的:订单信息、资金账户信息、积分信息、交易流水等信息分别存储在不同的数据里,而支付完成后,通知的目标系统的数据同样是存储在不同的数据库中。此时就会产生分布式事务问题。
分布式事务产生的场景
跨JVM进程
当我们将单体项目拆分为分布式、微服务项目之后,各个服务之间通过远程REST或者RPC调用来协同完成业务操作。典型的场景就是:商城系统中的订单微服务和库存微服务,用户在下单时会访问订单微服务,订单微服务在生成订单记录时,会调用库存微服务来扣减库存。各个微服务是部署在不同的JVM进程中的,此时,就会产生因跨JVM进程而导致的分布式事务问题。
跨数据库实例
单体系统访问多个数据库实例,也就是跨数据源访问时会产生分布式事务。例如,我们的系统中的订单数据库和交易数据库是放在不同的数据库实例中,当用户发起退款时,会同时操作用户的订单数据库和交易数据库,在交易数据库中执行退款操作,在订单数据库中将订单的状态变更为已退款。由于数据分布在不同的数据库实例,需要通过不同的数据库连接会话来操作数据库中的数据,此时,就产生了分布式事务。
多服务单数据库
多个微服务访问同一个数据库。例如,订单微服务和库存微服务访问同一个数据库也会产生分布式事务,原因是:多个微服务访问同一个数据库,本质上也是通过不同的数据库会话来操作数据库,此时就会产生分布式事务。
注意:跨数据库实例场景和多服务单数据库场景,本质上都是因为会产生不同的数据库会话来操作数据库中的数据,进而产生分布式事务。这两种场景是大家比较容易忽略的。
分布式事务解决方案
知道了分布式事务产生的场景后,接下来,我们就聊聊分布式事务具体有哪些解决方案。
2PC方案
2PC即两阶段提交协议,是将整个事务流程分为两个阶段,准备阶段(Prepare phase)、提交阶段(commit phase),2是指两个阶段,P是指准备阶段,C是指提交阶段。
这里,我们用MySQL数据库举例,MySQL数据库支持两阶段提交协议,可以分为成功和失败两种情况。
成功情况

失败情况

具体流程如下:
准备阶段(Prepare phase): 事务管理器给每个参与者发送Prepare消息,每个数据库参与者在本地执行事 务,并写本地的Undo/Redo日志,此时事务没有提交。(Undo日志是记录修改前的数据,用于数据库回滚,Redo日志是记录修改后的数据,用于提交事务后写入数 据文件)
提交阶段(commit phase): 如果事务管理器收到了参与者的执行失败或者超时消息时,直接给每个参与者 发送回滚(Rollback)消息;否则,发送提交(Commit)消息;参与者根据事务管理器的指令执行提交或者回滚操 作,并释放事务处理过程中使用的锁资源。
使用2PC方案时,需要注意的是:必须在最后阶段释放锁资源。
可靠消息最终一致性方案
可靠消息最终一致性方案是指当事务发起方执行完成本地事务后并发出一条消息,事务参与方(消息消费者)一定能 够接收消息并处理事务成功,此方案强调的是只要消息发给事务参与方最终事务要达到一致。
事务发起方(消息生产方)将消息发给消息中间件,事务参与方从消息中间件接收消息,事务发起方和消息中间件 之间,事务参与方(消息消费方)和消息中间件之间都是通过网络通信,由于网络通信的不确定性会导致分布式事 务问题。 所以,我们在具体方案中会引入消息确认服务和消息恢复服务。
使用可靠消息最终一致性方案时需要注意几个问题:
本地事务与消息发送的原子性问题。 事务参与方接收消息的可靠性问题。 消息重复消费的问题(需要实现幂等)。
TCC方案
TCC分为三个阶段:
Try 阶段 是做业务检查(一致性)及资源预留(隔离),此阶段仅是一个初步操作,它和后续的Confirm 一起才能 真正构成一个完整的业务逻辑。 Confirm 阶段 是做确认提交,Try阶段所有分支事务执行成功后开始执行 Confirm。通常情况下,采用TCC则 认为 Confirm阶段是不会出错的。即:只要Try成功,Confirm一定成功。若Confirm阶段真的出错了,需引 入重试机制或人工处理。 Cancel 阶段 是在业务执行错误需要回滚的状态下执行分支事务的业务取消,预留资源释放。通常情况下,采 用TCC则认为Cancel阶段也是一定成功的。若Cancel阶段真的出错了,需引入重试机制或人工处理。
使用TCC分布式解决方案时需要注意空回滚、幂等、悬挂等问题。
最大努力通知型方案
此种方案主要用于多个不同系统之前保证数据的最终一致性,大体如下图所示。
使用最大努力通知型方案需要注意幂等和数据的回查操作。
好了,今天就到这儿吧,后续我们会针对每种分布式事务解决方案进行具体介绍,下期见!!