
2020 年美国大选:一个生动的统计学课堂
↑↑↑点击上方蓝字,回复资料,10个G的惊喜
作者:杨笛笛
主页:https://www.zhihu.com/people/yang-di-di-62/posts
2016年美国大选,民调机构的预测滑铁卢了
今年大选,民调机构几乎是再次吃瘪,为什么民调数据总会出现偏差呢?
杨笛笛老师这篇文章生动地回答了这个问题
文末赠书福利
我想描述的总体是所有上海顾客。 我要测量的是他们接不接受现在的辣度。 最后得到一个yes or no的答案。 我决定在顾客用餐的时候安排服务员逐一发放问卷。
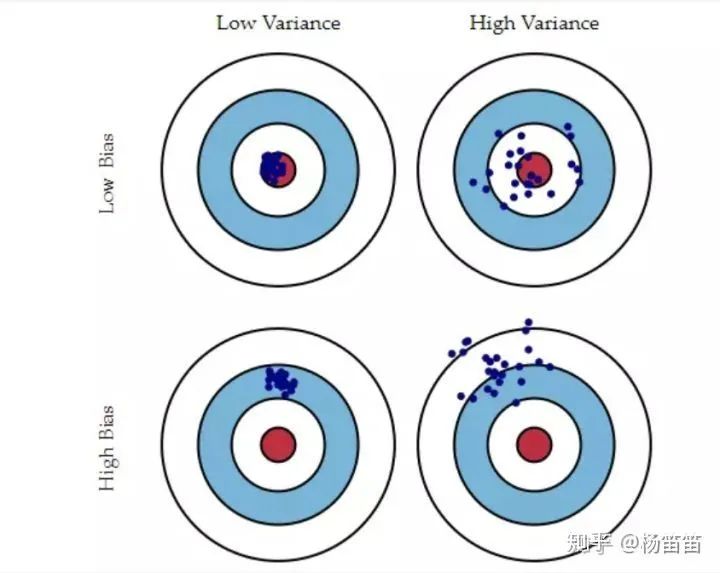
一共只有10份问卷导致方差(variance)或者说随机性太大。 有可能是服务员运气好刚好找到的都是喜欢辣味的顾客。 如果同样的抽样再做一次,说不定就只有5个人喜欢吃辣了。 就好像你扔一个公平硬币(正面概率0.5)10次,有时候3个正面有时候6个正面,这就是随机性。 那这个问题怎么解决呢? 最粗暴的方法就是增加样本量(sample size),扔10次硬币能得到4-6个正面概率只有65%左右,而扔1000次硬币得到400-600个正面的概率就几乎100%了。 除了增加样本量,还有一些其他的方法降低随机性,比如采用分层抽样等更高级的抽样手段。
其他的偏差主要来源还有:
赠书福利

感谢北京大学出版社赞助,共2本
赠书方式:后台回复999参与抽奖
11月8日(周日) 晚8点开奖

老铁,三连支持一下,好吗?↓↓↓
评论