
Elasticsearch 7.X data stream 深入详解
直接从一个新概念的认知过程说下 elasticsearch data stream。
记得第一次听到 data stream 的时候,还是去年下半年在公交大巴车上早 8 点听魏彬老师的直播,后来就一直没用。
等使用的时候,去翻看文档和资料前,从认知的角度,不免会有如下的疑问:
没有 data stream 的时候,如何管理时序型数据? 什么是 data stream? data stream 的特点有哪些? 为什么要有 data stream? data stream 能做什么? data stream 应用场景? data stream 和 索引 index 的关系? data stream 和 索引生命周期管理 ILM 的关系? data stream 实操有哪些注意事项?
带着这些问题,我们开始下面的解读。
PS:说明一下:后面所有博文的参考内容(含官方文档)都会写明详尽的参考地址,以便大家参考学习。
0、认知前提
0.1 时序性数据
指那种每天新增数据量非常大、且包含时间戳特性、有时效性特点的数据。
时效性体现在:用户往往更倾向关注最新、最热、最实时的数据。
比如:日志数据、大数据舆情数据等。
0.2 rollover
滚动索引,可以基于:时间间隔、文档数、分片大小进行滚动。
0.3 ILM
ILM = 索引生命周期管理的英文首字母组合。
1、没有 data stream 的时候,如何管理时序型数据?
实战一把,说的清楚。
1.1 基于 rollover 滚动索引机制管理时序数据
时序性索引数据,5.X 版本推出的rollover 滚动索引机制操作步骤如下:
步骤1:创建日期序列索引。
PUT /%3Cmylogs-%7Bnow%2Fd%7D-1%3E
{
"aliases": {
"mylogs_write": {}
}
}
GET mylogs-2021.07.24-1
步骤2:插入一条数据
PUT mylogs_write/_doc/1
{
"message": "a dummy log"
}
步骤3:导入数据
POST mylogs_write/_bulk
{"index":{"_id":4}}
{"title":"test 04"}
{"index":{"_id":2}}
{"title":"test 02"}
{"index":{"_id":3}}
{"title":"test 03"}
步骤4:指定RollOver规则(必须手动指定)
POST mylogs_write/_rollover
{
"conditions": {
"max_docs": 3
}
}
步骤5:再次导入批量数据
POST mylogs_write/_doc/14
{"title":"test 14"}
POST mylogs_write/_bulk
{"index":{"_id":5}}
{"title":"test 05"}
{"index":{"_id":6}}
{"title":"test 06"}
{"index":{"_id":7}}
{"title":"test 07"}
{"index":{"_id":8}}
{"title":"test 08"}
{"index":{"_id":9}}
{"title":"test 09"}
{"index":{"_id":10}}
{"title":"test 10"}
早期生产环境使用 rollover,有个比较麻烦的地方就在于——需要自己结合滚动的三条件,在给定的时间点(比如凌晨0:00)定时脚本执行一下 rollover,滚动才能生效。
看似脚本处理很简单,实际会有这样那样的问题,用过你就知道有多苦。
rollover 优点:实现了最原始的索引滚动。
rollover 缺点:需要手动或者脚本定时 rollover 非常麻烦。
这时候,读者不禁要问,ILM 索引生命周期管理操作时序数据呢?
1.2 ILM 索引生命周期管理时序数据
篇幅原因,不再举例。可以参考:干货 | Elasticsearch 索引生命周期管理 ILM 实战指南。
ILM 是模板、别名、生命周期 policy 的综合体。
ILM 优点:一次配置,索引生命周期全自动化。 ILM 适用场景:更适合和冷热集群架构结合的业务场景。 ILM 缺点:ILM是普适的概念,强调大而全,不是专门针对时序数据特点的方案,且需要为 ilm 配置 index.lifecycle.rollover_alias 设置(对时序数据场景,这非常麻烦)。
上述 rollover、ILM 机制实现:都涉及到多索引和别名的关系。
官方强调:别名在 Elasticsearch 中的实现方式存在一些不足(官方没有细说哪些不足。我实战环境发现:一个别名对应多个索引,一个索引对应多个别名,索引滚动关联别名也可能滚动,开发者可能很容易出错和混淆),使用起来很混乱。
相比于别名具有广泛的用途,而数据流将是针对时序数据的解决方案。
2、什么是 data stream?
data:数据。
stream:流。
data stream:数据流。
我X,这英语翻译,小学生也会。没劲!能不能通俗点说?
我把 data stream 比如:存储时序数据的多个索引的抽象集合,简称为:数据流(data stream)。
数据流可以跨多个后备索引存储仅追加(append-only,下文有详细解释)的时间序列数据,同时对外提供一个同一访问入口。
上面 data stream 的定义和别名的定义貌似一致,国外博主把它戏称为“超能力别名”,我认为非常生动和贴切。
和别名不同的是:别名关联多个索引,写入的时候需要指定 “is_write_index",而 data stream 相对黑盒,这些细节用户无需关注。
所以,它是索引、模板、rollover、ilm 基于时序性数据的综合产物。
3、data stream 的特点有哪些?
3.1 关联后备支撑索引(backing indices)
data stream 作为“带头大哥”在外抛头露面,实际后面一堆“小弟”在全力支撑。
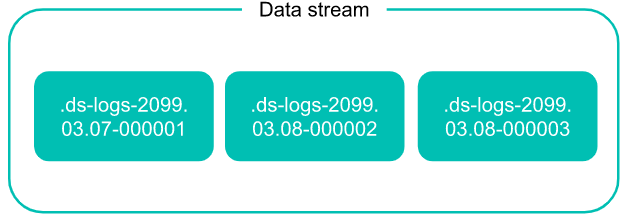
图片来自官方文档
“带头大哥”指的是:数据流。它的特点:抛头露面、光鲜亮丽。
“小弟”:指 backing indices,后备索引。它的特点:相对隐身、默默无闻。其实出力的都是它,除非大哥出事(一些特定约束搞不定),小弟们才会站出来。
3.2 @timestamp 字段不可缺
每个写入到 dataSteam 的文档必须包含 @timestamp 字段。 @timestamp 字段必须是:date 类型(若不指定,默认:date 类型)或者 date_nanos 类型。
3.3 data stream 后备索引规范
创建后备索引时,索引使用以下约定命名:
.ds-<data-stream>-<yyyy.MM.dd>-<generation>
举例索引真实名称:data-stream-2021.07.25-000001。
.ds:前缀开头不可少。 data-stream: 自定义的数据流的名称。 yyyy.MM.dd:日期格式 generation:rollover 累积值:—— 默认从:000001 开始。
3.4 Append-only 仅追加
仅追加:指只支持 op_type=create 的索引请求,我理解的是仅支持向后追加(区别于对历史数据的删除、更新操作)。
数据流只支持:update_by_query 和 delete_by_query 实现批量操作,单条文档的更新和删除操作只能通过指定后备索引的方式实现。
对于频繁更新或者删除文档的业务场景,用 data stream 不合适,而相反的,使用:模板+别名+ILM更为合适。
4、为什么要有 data stream?
原有实现由于别名的缺陷实现不了时序数据的管理或实现起来会繁琐、麻烦,data stream 是更为纯粹的存储仅追加时序数据的方式。
5、data stream 能做什么?
data stream 支持直接的写入、查询请求。 data stream 会自动将客户端请求路由至关联索引,以用来存储流式数据。 可以使用索引生命周期管理 ILM 自动管理这些关联索引。
6、data stream 的适用场景
日志(logs)、事件(events)、指标(metrics)和其他持续生成的数据。
两大核心特点:
时序性数据。 数据极少更新(或者没有更新)。
7、data stream 和索引有什么异同?
7.1 相同点
绝大多数命令一致。
7.2 不同点
数据流相对实体索引,有点“抽象层“的概念,其核心数据还是存储在 .ds 前缀的后备索引中。
以下操作,只适用于数据流。
数据流对应映射必须包含日期类型的 @timestamp 字段。 数据流删除和更新只支持 “_update_by_query” 和 “_delete_by_query”操作。 不能基于.ds 前缀的后备索引创建文档,但可以基于:以.ds前缀的后备索引更新和删除文档。
我不听,我非要指定后备索引写入一条数据,咋办?试试吧:
POST .ds-my-data-stream-2021.07.25-000001/_doc/2
{
"@timestamp": "2099-05-06T16:21:15.000Z",
"message": "192.0.2.42 - - [06/May/2099:16:21:15 +0000] \"GET /images/bg.jpg HTTP/1.0\" 200 24736"
}
会有如下的报错提示:不支持指定后备索引写入,只能基于数据流写入。
"reason" : "index request with op_type=index and no if_primary_term and if_seq_no set targeting backing indices is disallowed, target corresponding data stream [my-data-stream] instead"
也就是说:只能基于数据流写入数据。
不能对后备索引执行:clone, close, delete, freeze, shrink 和 split 操作。
8、data stream 和 模板的关系?
相同的索引模板可以用来支撑多个 data streams。可以类比为:1:N 关系。
不能通过 删除 data Stream 的方式删除索引模板。
9、data stream 和 ilm 的关系?
ILM 在 data stream 中起到索引生命周期管理的作用。
data stream 操作时序数据优势体现在:不再需要为 ilm 配置 index.lifecycle.rollover_alias。
10、data stream 实操指南
涉及 data stream 的创建(新增)、删除、修改、查询。
10.1 data stream 增
由于 data stream 涉及模板、索引、ILM、别名等,分步骤拆解更好理解。
步骤 1:创建索引生命周期 policy。
直接拿官方文档的示例说明。
如下的 policy 包含了:热、暖、冷、冷冻、删除等阶段。
PUT _ilm/policy/my-lifecycle-policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_primary_shard_size": "50gb"
}
}
},
"warm": {
"min_age": "30d",
"actions": {
"shrink": {
"number_of_shards": 1
},
"forcemerge": {
"max_num_segments": 1
}
}
},
"cold": {
"min_age": "60d",
"actions": {
"searchable_snapshot": {
"snapshot_repository": "found-snapshots"
}
}
},
"frozen": {
"min_age": "90d",
"actions": {
"searchable_snapshot": {
"snapshot_repository": "found-snapshots"
}
}
},
"delete": {
"min_age": "735d",
"actions": {
"delete": {}
}
}
}
}
}
步骤 2:创建模板
模板组成包括:index_patterns、指定数据流 data stream、settings、mappings。
PUT _component_template/my-mappings
{
"template": {
"mappings": {
"properties": {
"@timestamp": {
"type": "date",
"format": "date_optional_time||epoch_millis"
},
"message": {
"type": "wildcard"
}
}
}
}
}
# Creates a component template for index settings
PUT _component_template/my-settings
{
"template": {
"settings": {
"index.lifecycle.name": "my-lifecycle-policy"
}
}
}
PUT _index_template/my-index-template
{
"index_patterns": ["my-data-stream*"],
"data_stream": { },
"composed_of": [ "my-mappings", "my-settings" ],
"priority": 500
}
步骤 3:创建 data stream 。
方式一:直接创建数据流 my-data-stream。
PUT _data_stream/my-data-stream
方式二:直接批量或者逐个导入数据(会间接生成 data stream 的创建)。
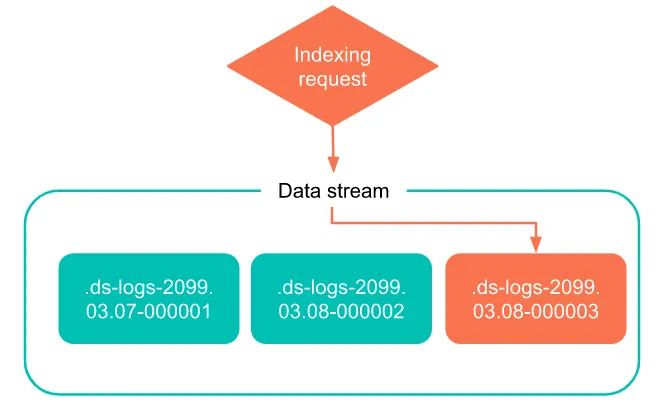
图片来自官方文档
PUT my-data-stream/_bulk
{ "create":{ } }
{ "@timestamp": "2099-05-06T16:21:15.000Z", "message": "192.0.2.42 - - [06/May/2099:16:21:15 +0000] \"GET /images/bg.jpg HTTP/1.0\" 200 24736" }
{ "create":{ } }
{ "@timestamp": "2099-05-06T16:25:42.000Z", "message": "192.0.2.255 - - [06/May/2099:16:25:42 +0000] \"GET /favicon.ico HTTP/1.0\" 200 3638" }
POST my-data-stream/_doc
{
"@timestamp": "2099-05-06T16:21:15.000Z",
"message": "192.0.2.42 - - [06/May/2099:16:21:15 +0000] \"GET /images/bg.jpg HTTP/1.0\" 200 24736"
}
两个注意的地方:
第一:批量 bulk 操作,必须使用:create 指令,而非 index(使用 index 不会报错, 会把流当做索引处理了)。
第二:文档必须包含:@timestamp 时间戳字段。
如果不包含 @timestamp 会报错如下:
"reason" : "data stream timestamp field [@timestamp] is missing"
10.2 data stream 删
删除数据流
删除 data stream 和 删除索引、删除模板语法基本一致。
DELETE _data_stream/my-data-stream
执行删除操作之后,该 data stream 以及 关联索引都会被一并删除。
单条删除文档
DELETE data-stream-2021.07.25-000001/_doc/1
批量删除文档
批量删除数据的方式如下:
POST /my-data-stream/_delete_by_query
{
"query": {
"match": {
"user.id": "vlb44hny"
}
}
}
10.3 data stream 改
单条数据修改/更新
# 插入一条数据
POST my-data-stream/_bulk
{"create":{"_id":1}}
{"@timestamp":"2099-05-06T16:21:15.000Z","message":"192.0.2.42 - - [06/May/2099:16:21:15 +0000] \"GET /images/bg.jpg HTTP/1.0\" 200 24736"}
# 获取数据流关联索引
GET /_data_stream/my-data-stream
# 执行更新
PUT .ds-my-data-stream-2021.07.25-000001/_doc/1?if_seq_no=1&if_primary_term=1
{
"@timestamp": "2099-03-08T11:06:07.000Z",
"user": {
"id": "8a4f500d"
},
"message": "Login successful"
}
# 查看验证是否已经更新(已经验证,可以更新)
GET .ds-my-data-stream-2021.07.25-000001/_doc/1
这里要强调:原来更新单条索引数据的 _update/id 的方法不适用于数据流。
批量更新
支持通过:update_by_query 批量更新数据。
POST /my-data-stream/_update_by_query
{
"query": {
"match": {
"user.id": "l7gk7f82"
}
},
"script": {
"source": "ctx._source.user.id = params.new_id",
"params": {
"new_id": "XgdX0NoX"
}
}
}
10.4 data stream 查
GET _data_stream/my-data-stream
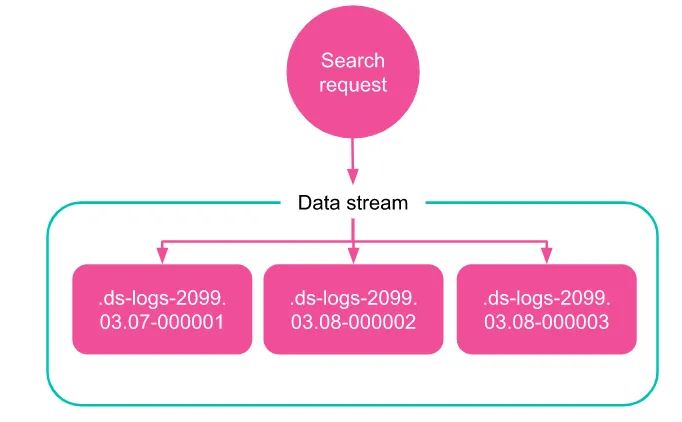
图片来自官方文档
返回结果如下:
{
"data_streams" : [
{
"name" : "my-data-stream",
"timestamp_field" : {
"name" : "@timestamp"
},
"indices" : [
{
"index_name" : ".ds-my-data-stream-2021.07.25-000001",
"index_uuid" : "Akg3-bWgStiKG_39Tk5PRw"
}
],
"generation" : 1,
"status" : "GREEN",
"template" : "my-index-template",
"ilm_policy" : "my-lifecycle-policy",
"hidden" : false
}
]
}
10.5 其他操作
reindex 操作
POST /_reindex
{
"source": {
"index": "archive"
},
"dest": {
"index": "my-data-stream",
"op_type": "create"
}
}
滚动操作
POST my-data-stream/_rollover
查看 data stream 基础信息
GET /_data_stream/my-data-stream
11、小结
在规划产品的时候,往往会细数一下产品的新功能,这些新功能可能是:集成竞品、原创更新、其他产品线功能更新等。
data stream 这个 7.9 版本才推出的新功能点,其实是基于原有实现不能满足时序数据特点,更为确切说原有实现机制相对复杂而推出的新功能。
提炼一下本文内容,划重点如下:
data stream 是时序索引的上层抽象。 data stream 是模板、索引、settings、mappings、ilm policy等综合体的概念。 data stream 相当于抛头露面的带头大哥,离不开看似隐身、默默无闻、实际埋头苦干的后备索引的支撑。 data stream 不适合频繁删除、更新的业务场景,更适合仅追加时序数据场景。 只能基于 data stream 写入数据,不能基于后备索引写入数据。 data stream 不支持单条删除或单条更新数据,只支持:update_by_query 以及 delete_by_query。
参考
https://www.elastic.co/guide/en/elasticsearch/reference/7.x/data-streams.html
https://opster.com/elasticsearch-glossary/elasticsearch-data-streams/
https://aravind.dev/elastic-data-stream/
https://github.com/elastic/elasticsearch/issues/53100
https://www.elastic.co/guide/en/elasticsearch/reference/7.13/release-notes-7.9.0.html
推荐
