
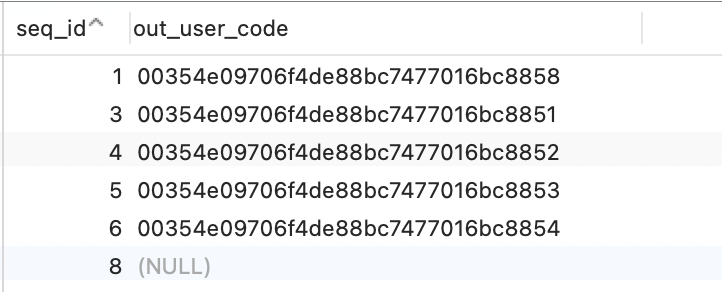
SQL如何删除重复的记录,只保留一条?
一、关于mysql表中数据重复
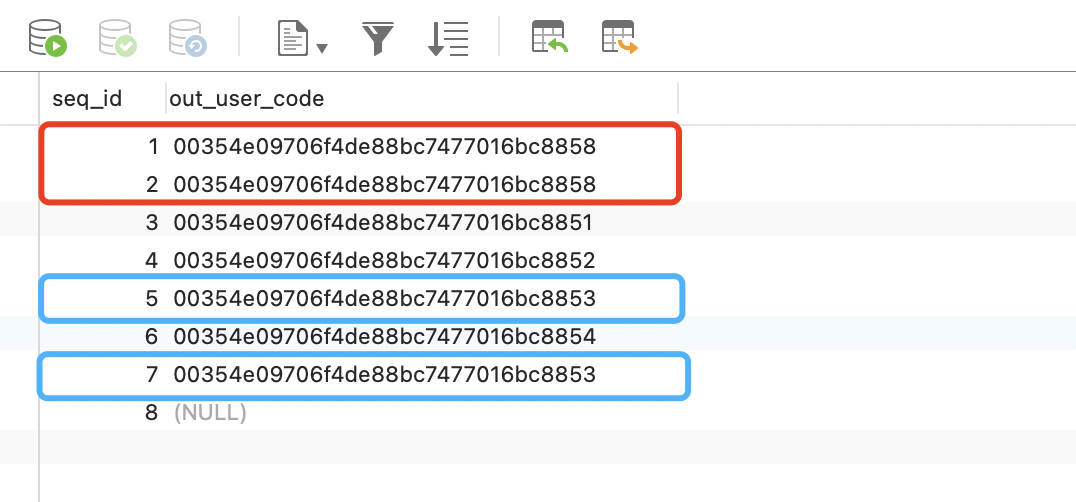
SELECT
seq_id,
out_user_code,
COUNT( out_user_code ) count
FROM
test
WHERE
is_deleted = 0
AND out_user_code IS NOT NULL
GROUP BY
out_user_code
HAVING
count( out_user_code )> 1
二、聚合函数min(id)+not in
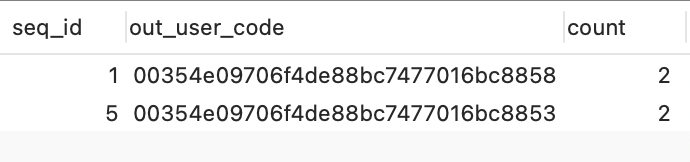
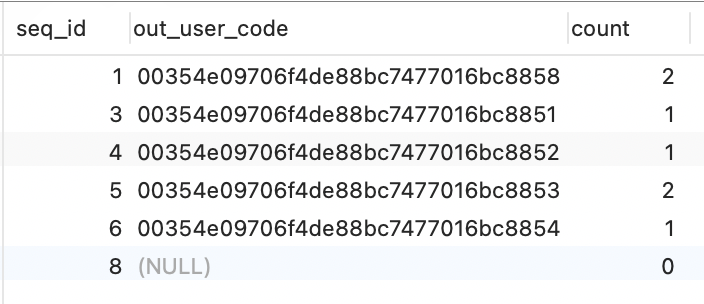
SELECT
min(seq_id) seq_id,
out_user_code,
COUNT( out_user_code ) count
FROM
test
GROUP BY
out_user_code
DELETE from test where r.seq_id not in (
SELECT
min(t.seq_id) seq_id
FROM
test t
GROUP BY
t.out_user_code
) r
DELETE from test where seq_id not in (
SELECT r.seq_id from (
SELECT
min(t.seq_id) seq_id
FROM
test t
GROUP BY
t.out_user_code
) r
) and out_user_code is not null
DELETE from test
where
out_user_code in (select * from (select out_user_code from test del group by out_user_code HAVING count(out_user_code) >1)a)
and seq_id not in(select * from (select min(seq_id) id from test del group by out_user_code HAVING count(out_user_code) >1)b
)f
三、窗口函数row_number()
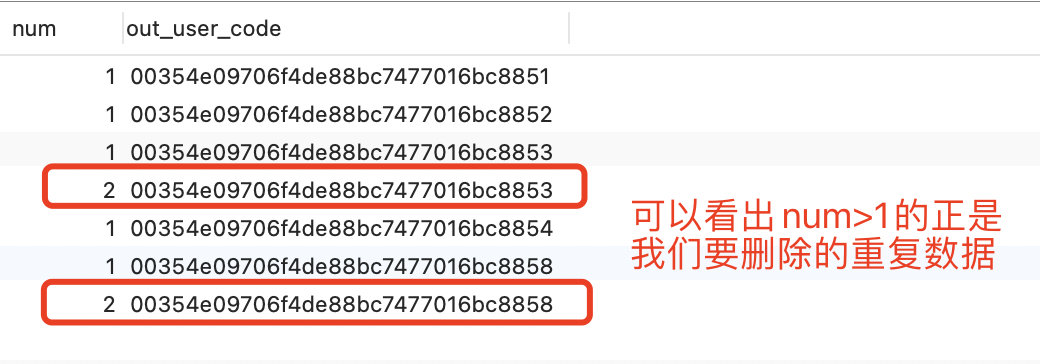
SELECT
ROW_NUMBER() OVER ( PARTITION BY out_user_code ORDER BY seq_id ) num,
out_user_code
FROM
test
WHERE
out_user_code IS NOT NULL
DELETE a
FROM (
SELECT
ROW_NUMBER() OVER (PARTITION BY out_user_code ORDER BY seq_id) num
FROM test
where out_user_code IS NOT NULL
) a
WHERE num>1
DELETE
FROM test
WHERE seq_id in (
SELECT seq_id
FROM(
SELECT *
FROM (
SELECT ROW_NUMBER() OVER w AS row_num,seq_id
FROM test where out_user_code is not null
WINDOW w AS (PARTITION BY out_user_code ORDER BY seq_id)
)t
WHERE row_num >1
)e
)
四、补充:常见的窗口函数
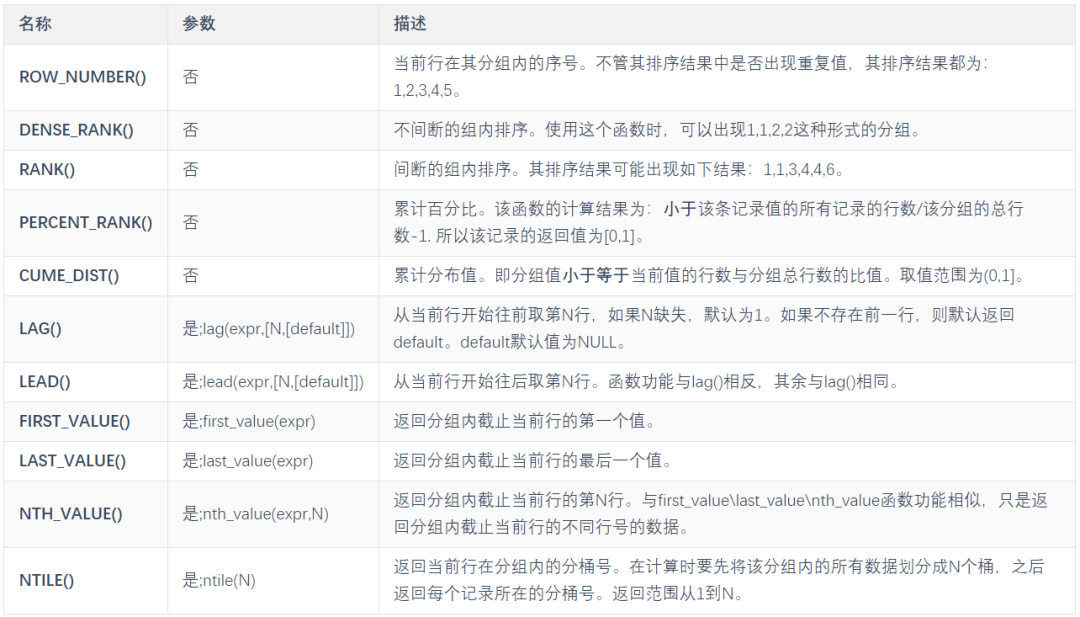
partition by子句:按照指定字段进行分区,两个分区由边界分隔,窗口函数在不同的分区内分别执行,在跨越分区边界时重新初始化。
order by子句:按照指定字段进行排序,窗口函数将按照排序后的记录顺序进行编号。可以和partition by子句配合使用,也可以单独使用。
frame子句:当前分区的一个子集,用来定义子集的规则,通常用来作为滑动窗口使用。
 关注我,分享技术干货
关注我,分享技术干货
评论