
预训练图像处理Transformer
、点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
来源 | 小白学视觉
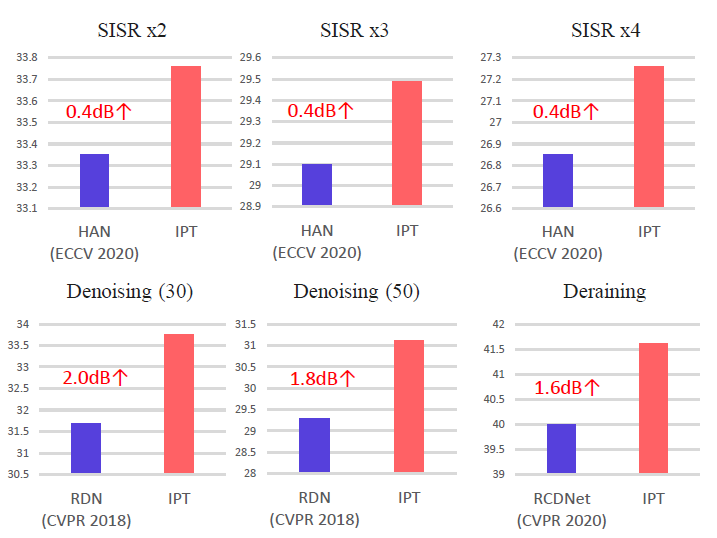
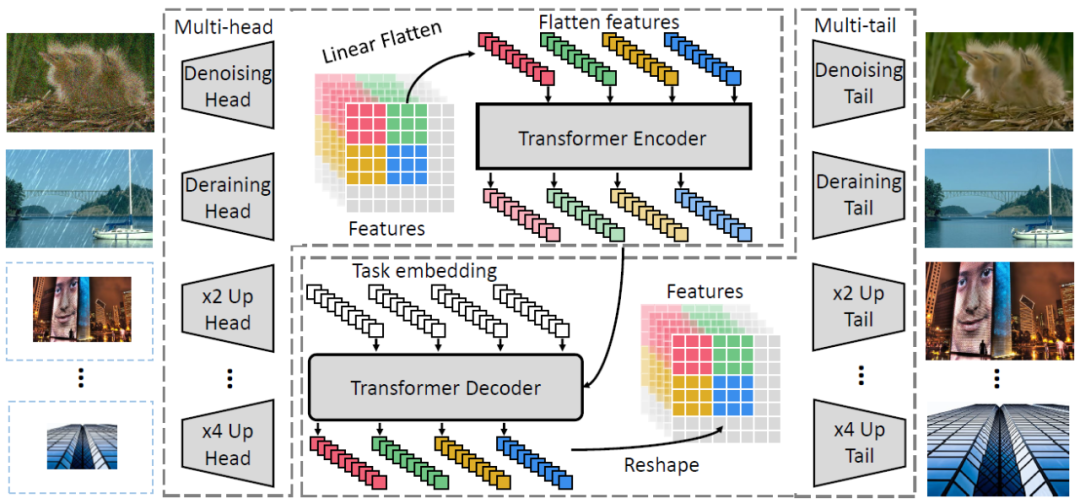
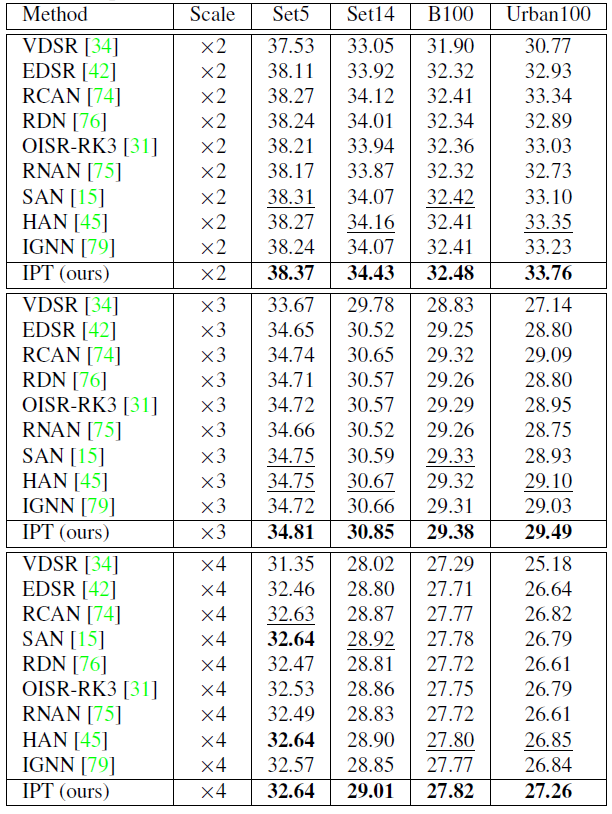
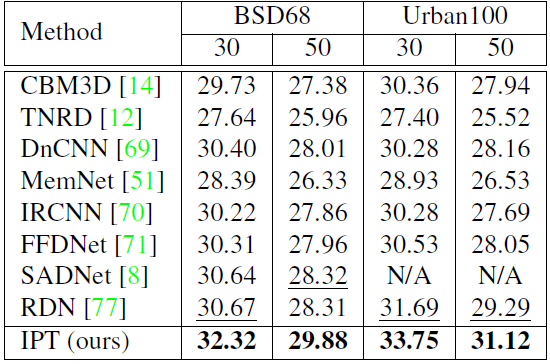
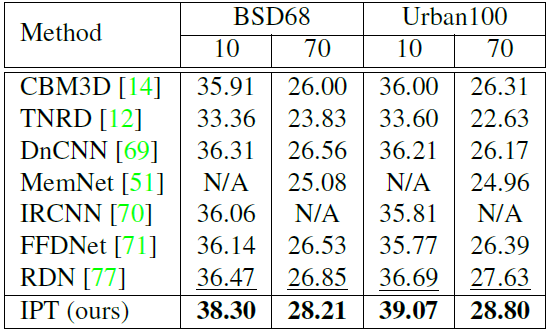
作为自然语言处理领域的主流模型,Transformer 近期频频出现在计算机视觉领域的研究中。例如 OpenAI 的 iGPT、Facebook 提出的 DETR 等,这些跨界模型多应用于图像识别、目标检测等高层视觉任务。而华为、北大、悉大以及鹏城实验室近期提出了一种新型预训练 Transformer 模型——IPT(Image Processing Transformer),用于完成超分辨率、去噪、去雨等底层视觉任务。该研究认为输入和输出维度相同的底层视觉任务更适合 Transformer 处理。



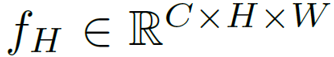
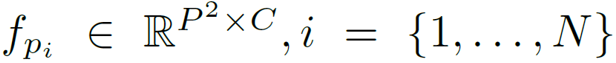


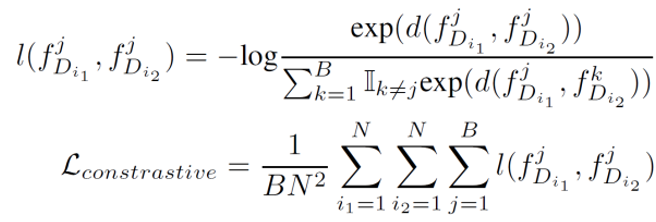



评论