
时序数据库(NTSDB)在网易的实践
共 3055字,需浏览 7分钟
·
2021-04-10 11:21
配套资料下载:关注网易有数,回复关键词【时序数据库】,领取网易时序数据库用户手册。
什么是时序数据业务?
哪些业务是时序数据业务呢?简单的说,如果你的数据记录中有一个字段是时间字段,而且大多数查询都需要基于时间区间进行过滤查询分析(也就是你只关心某个时间段的查询统计结果),这个业务基本就可以认定为时序数据业务了。典型的时序数据业务有类监控业务、业务指标统计分析业务以及物联网设备数据分析业务等。
比如监控类业务,监控服务器主机的CPU资源使用情况,采集器每次采集服务器的CPU使用率进行存储都必须带有时间字段,用以表征给定时间点的CPU使用率,用户查询也是基于时间字段查询最近一小时或者最近三小时的CPU使用率曲线,或者做一些统计分析,比如分析对比最近一小时多台服务器的CPU平均使用率,看哪个CPU的平均使用率最高。这类监控业务除了服务器硬件监控,还有各种业务指标监控,开源系统集群监控等等。
哪些业务不是时序数据业务呢?比如交易订单数据、商品库存数据,用户信息(标签)数据,歌单信息数据等等,这些数据本身并不需要时间字段,用户也不会根据时间区间去执行过滤查询。
NTSDB为什么适合时序数据业务?
1.网易时序数据库系统架构
NTSDB系统主要由3个部分构成:NTSDB客户端、Master节点以及ShardServer节点。如下图所示:
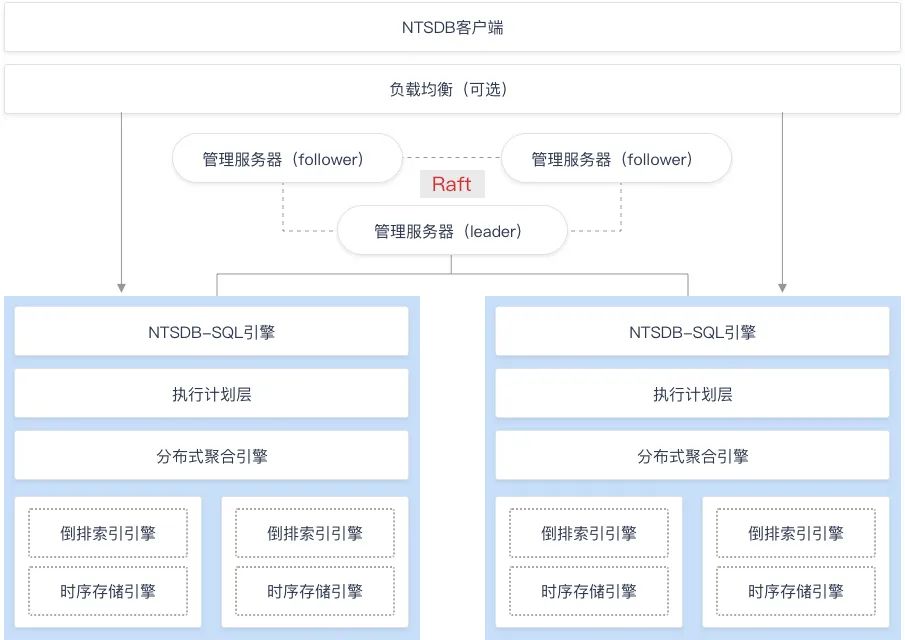
NTSDB客户端:包括Shell命令行客户端、Java SDK、Python SDK等,不同客户端满足不同业务需求。
Master节点:负责管理集群元数据信息,处理集群节点故障恢复,执行负载均衡等管理操作。Master采用Raft三副本机制保证服务高可用、元数据高可靠,避免单点故障。
ShardServer节点:计算存储引擎ShardServer负责用户的读写请求。ShardServer由SQL引擎层、执行计划层、分布式聚合层、倒排索引引擎以及时序存储引擎等多个模块组成。其中SQL引擎负责将用户输入的SQL语句解析为系统可执行语句;执行计划层负责执行计划的制定,主要根据用户输入的时间范围选择对应的数据分片作为实际数据源;分布式聚合层负责将各个分片读取到的原始数据进行聚合计算;倒排索引引擎负责根据用户输入的维度条件进行索引检索,加快多维条件过滤查询;时序存储引擎负责存储实际的时序数据,这些时序数据会按照时间顺序按照列式进行存储,每个数据列会根据数据类型进行相应的数据压缩,减少存储空间。
2.网易时序数据库核心功能
(1)读写高性能
高吞吐量写入保证:LSM技术保证高吞吐量写入性能。单机每秒可写入30w+个点。
高效查询扫描保证:时序存储引擎针对时序数据定制文件格式,极大提升时序数据的查找扫描效率。10亿数据集中查找数据50ms以内返回。
高效聚合分析保证:时间分片、列式存储、分布式聚合等功能,极大提升数据聚合能力。亿条数据秒级聚合。
多维条件查询保证:倒排索引功能保证高效多维条件查询性能。
(2)简单易用
提供类SQL语法查询
Free Schema特性保证用户可随意增加删除表字段
TTL功能自动过期久远数据
数据可方便地执行更新
(3)分布式集群能力
多副本技术保证数据高可靠、服务高可用。避免服务单点
扩容只需简单增加节点即可
由此可见,网易时序数据库针对时序数据定制了时序存储引擎,并增加了倒排索引功能、SQL引擎功能以及分布式集群管理功能,是一款针对性极强的存储解决方案。
NTSDB应用场景
1.大规模集群监控平台
系统监控业务是时序数据业务最典型的代表,可以说NTSDB就是为监控而生。监控需求是所有在线服务系统的刚需,NTSDB系统可以为监控业务提供最友好的存储技术保障。对于监控场景,NTSDB提供两种接入方式:
使用telegraf作为指标采集器部署在目标集群,将集群指标采集到之后写入NTSDB;
业务系统通过JDBC直接将指标数据写入NTSDB系统
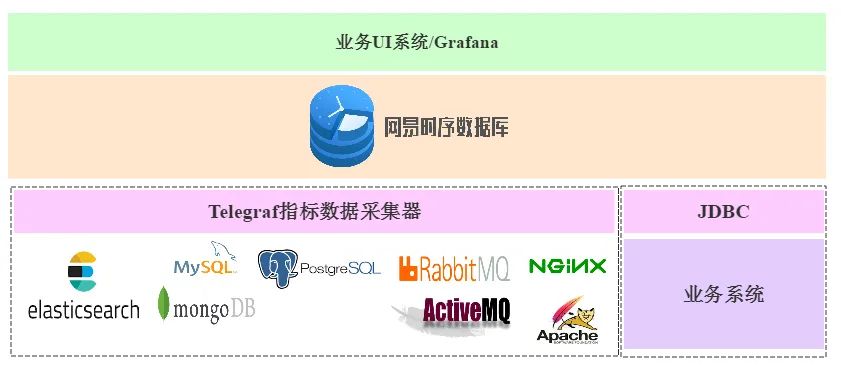
目前telegraf采集器原生支持30多种系统的指标采集,包括MySQL、SQL Server、MongoDB、Nginx、Tomcat、Elastic Search、RabbitMQ、 ceph、docker、kubernetes、redis、varnish以及zookeeper等。
(NTSDB在大规模集群监控平台的应用)
2.业务指标统计分析平台
另一个典型的时序数据业务是应用指标统计分析平台,比如广告营销分析平台、性能测试分析平台、CDN流量分析平台等等。广告营销分析平台会对指定广告主、广告位上的广告曝光量、点击量等各种指标基于时间区间进行多维度分析统计,根据统计结果指导优化广告投放策略。性能测试分析平台会对指定URL的TPS、访问成功率、访问延迟等指标基于时间区间进行多维度统计分析,形成性能测试报告。
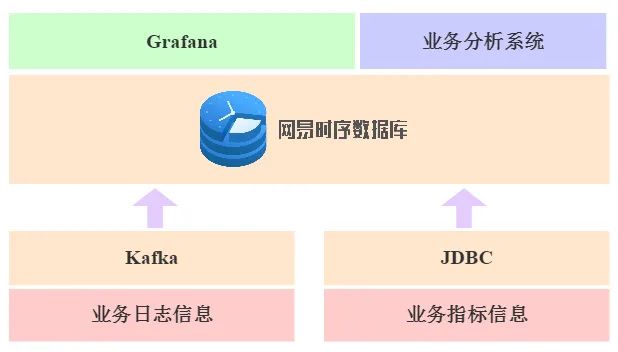
(使用NTSDB之后的典型解决方案)
业务方通过日志的形式将业务指标以json的方式发送到Kafka系统,NTSDB会从Kafka系统将对应topic的json数据拉取下来并进行存储。前端再使用Grafana作为可视化分析工具,或者业务直接调用JDBC进行数据分析。
业务方也可以通过NTSDB提供的JDBC将采集的数据直接写入NTSDB系统。前端再使用Grafana作为可视化分析工具,或者业务直接调用JDBC读取数据进行数据分析。
3.物联网平台
物联网设备(智能扫地机器人、智能音响、工厂数字机床设备等)数据可以通过网关将数据发送到IoT Hub(接入管理设备,接收设备上报的数据存储在本地队列),再通过流计算引擎将数据实时写入NTSDB,在NTSDB之上可以进行监控报警、数据分析等,基本系统架构如下:
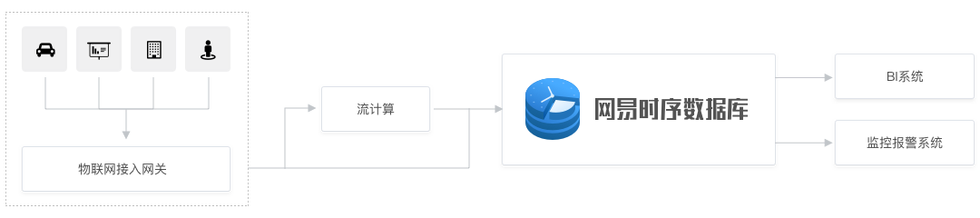
(NTSDB在物联网的应用)
写在最后
现有市场上较成熟的时序数据库主要包括Druid、InfluxDB等。网易结合各类时序数据库的优缺点,自主研发了NTSDB,支持高性能写入和读取,支持多维条件查询,支持聚合计算,且运行开销较小,可私有化、分布式部署。
目前网易有数BI已支持Druid、InfluxDB数据源,对NTSDB数据源的支持也即将上线,如果你有时序业务相关的需求,或者你对时序数据库技术细节感兴趣,欢迎来撩~

读了这篇文章,希望可以帮助大家理解这么几个非常重要的问题(对个人的技术提升、业务的方案选型非常有帮助):
1. 什么是时序数据业务?负责的业务有没有时序数据业务?
2. 如果你当前的业务是时序数据业务,目前的存储方案是否存在痛点?
3. 网易时序数据库(NTSDB)技术架构是什么?功能优势在哪里?是否可以更好地满足当前的业务需求?
子和,网易大数据开发工程师,长期从事分布式KV数据库、分布式时序数据库以及大数据底层组件等相关工作。
