
RocketMQ存储设计精髓
点击关注公众号,Java干货及时送达
另外在进行消息消费的时候,RocketMQ如何能借助自身的存储设计快速检索到对应的消息也是非常重要的,因此本文主要对RocketMQ存储设计进行了设计分析。
存储结构
RocketMQ对应的存储文件主要包括三类,分别是Commitlog文件、ConsumeQueue文件以及Index文件,每一个文件都有其特殊的使命。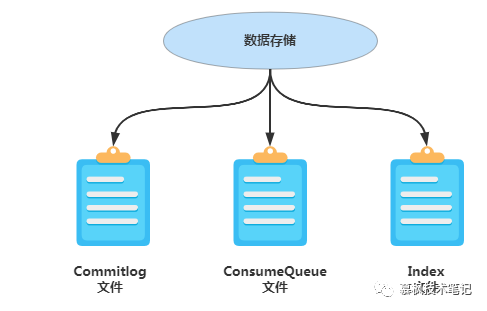
Commitlog文件
当生产者将消息发送到RocketMQ的Broker之后,需要将消息进行持久化存储,防止消息数据丢失。RocketMQ将消息数据写入存储文件CommitLog中,按照消息的发送顺序写入文件当中,每个文件的大小约为1G,当达到文件大小限制后,就会创建新的CommitLog文件。RocketMQ作为消息中间件来说,最主要的数据流程就是基于主题的发布-订阅模式进行消息的发布以及消费,那么当消费者根据自己订阅的Topic进行消息消费的时候,Broker怎么在那么多的CommitLog文件中找到对应Topic的消息数据呢?
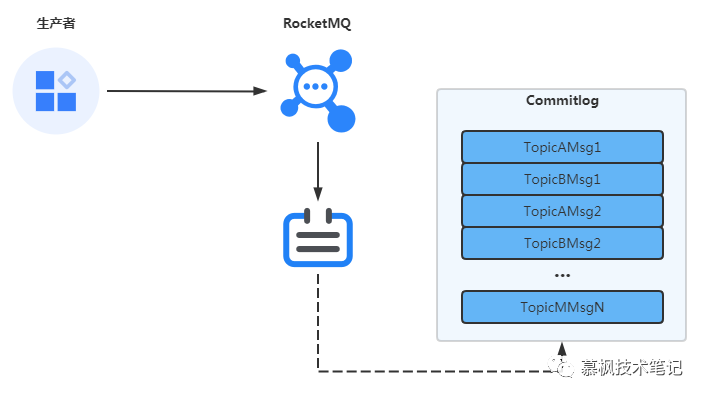
大家可以想一想,CommitLog文件中的消息数据是一条一条顺序写的,最笨的方法就是遍历文件,作为一款高性能的消息中间件,显然这不是一个好的解决方案。
就像从数据库查询数据的时候,遍历的效率肯定是很低的。那么我们可不可以借助数据库提升数据查询的方式,使用索引来加快消息数据的查询呢?答案是肯定的。就像Mysql中的索引本身需要文件保存一样,在RocketMQ中也有单独保存索引的文件,就是ConsumerQueue文件。
ConsumerQueue文件
在RocketMQ中,每个Topic对应多个MessageQueue,每个MessageQueue对应一组ConsumerQueue文件索引文件。ConsumerQueue文件中存储了消息相对于CommitLog文件的offset偏移量,CommitLog文件本身实际上也是通过偏移量来进行命名如第一个文件是0000000000000,那么第二文件就是消息总量之和00000001232321,往后新的文件再进行累计。为什么这么做呢?主要就是在进行消息查找的时候根据消息的偏移量通过二分查找快速定位具体的CommitLog文件,提升消息查找效率。需要说明的是,Broker在进行消息写入CommitLog文件中就会异步将其对应的偏移量写入ConsumerQueue文件中。
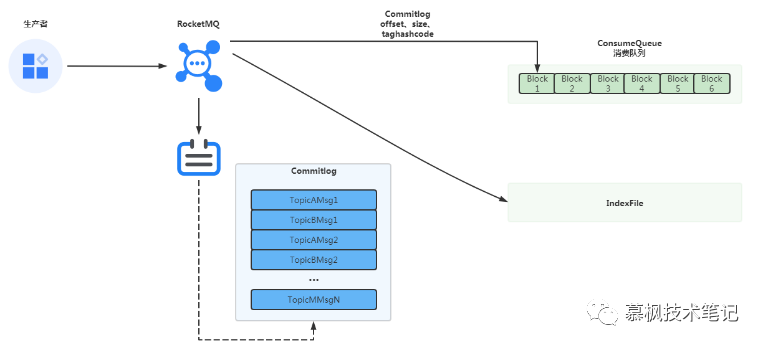
在ConsumerQueue文件中实际存储了CommitLog文件的offset偏移量、消息长度以及tag的hashcode,组成20字节的block块。其在Broker上面的存储路径大致是:.../store/consumequeue/{topic}/{queueid}/{file}。
其中topic就是生产中订阅的主题,因此消费者在消费消息的时候,Broker会根据其对应的Topic找到对应的 ConsumerQueue文件,进而找到其索引位置,再到CommitLog文件中直接定位具体的消息。
Index文件
另外RocketMQ的特性功能就是可以实现按照消息的属性进行消息搜索,即建立了索引 Key 的 hashcode 与物理偏移量的映射关系,根据 key 先快速定义到 commitlog 文件。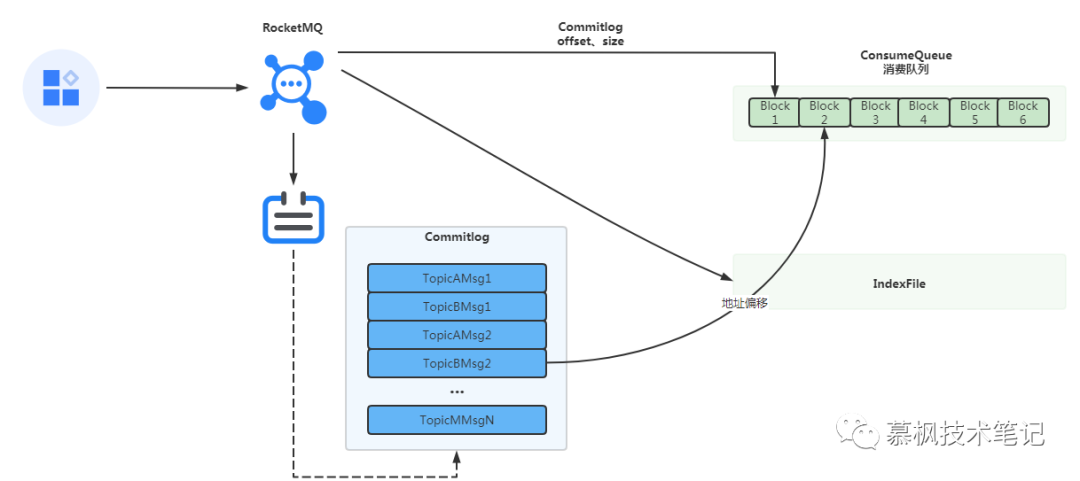
存储性能设计精髓
上文中为大家阐述了RocketMQ关于存储结构的设计,优秀的存储设计师实现高性能读写的前提。那么除了存储结构的设计,RocketMQ也使用了一些性能优化手段来实现其强大的消息吞吐能力。消息顺序写
前文中说过,消息进入RocketMQ之后,消息数据是通过顺序写的方式落到CommitLog文件中的。那么这里面就涉及两个问题,为什么进行顺序写以及是不是直接写磁盘文件。
1、为什么要顺序写?
当新的数据到来时,只要在之前的文件末尾进行数据追加就可以,这样的数据写入效率要比随机写入的效率高。2、每次数据写入的时候是直接写磁盘文件吗?
我们可以反过想,如果每次都是落盘写入的话实际效率是不高的,无法满足消息中间件这种高吞吐的性能要求,因此RocketMQ实际是借助操作系统的page cache来提升写入效率的,消息并不是直接写入磁盘,而是先写入操作系统的page cache,然后再通过异步刷盘的方式,写入CommitLog文件中,这样借助顺序写以及系统的page cache可以时间近乎内存的数据写入效率。同步刷盘和异步刷盘
异步刷盘
刚才所说的异步写入,其实就是RocketMQ的异步刷盘模式,但是大家想想这个模式有没有什么问题。为了提升数据吞吐量,消息数据过来后,并没有直接写盘,而是在系统中的page cache中。那么此时如果Broker宕机了,那么此时的消息数据是容易丢失的。所以虽然异步刷盘的写入效率高但是也存在数据丢失的风险。同步刷盘
在同步刷盘的场景下,当Broker接受到对应的消息之后,Broker将会把这条消息刷入磁盘的CommitLog中,才会返回确认消息给生产者。如果在进行消息写入的时候Broker挂了,那么生产者会感受到消息投递失败,一般都会都有消息重新发送的重试逻辑。这样看消息似乎不会丢失了,但是由于每次都是先落盘,就会导致数据写入性能下降。MMAP
在RocketMQ中使用了mmap技术来实现Conmmitlog文件的高性能读写,mmap就是一种内存映射文件的方法,对于传统的文件IO交互来说,需要经过多次的数据复制过程才能将用户进程的数据写入硬盘或者读入程序。而mmap可以直接将虚拟内存中的文件与硬盘中文件地址进行映射,减少了数据拷贝的过程,从而提升了数据写入的效率。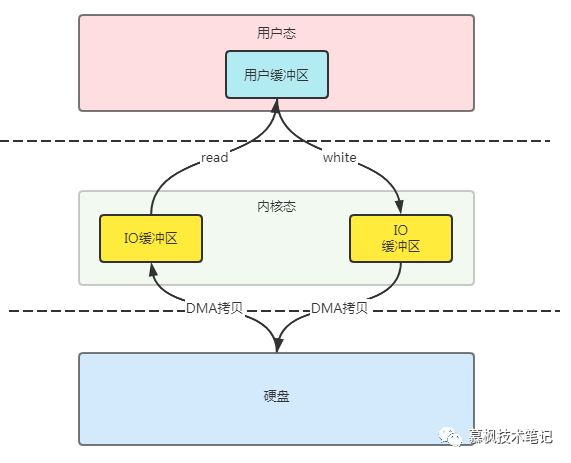
总结
本文主要对RocketMQ的存储设计进行了分析,围绕如何实现高性能消息写入和查询展开了阐述,希望在分析这些优秀中间的具体实现过程中,我们可以将这些优秀设计融入到具体的项目实践中,当我们遇到类似的问题的时候可以借助于这些设计思想来解决实际的问题。往期推荐
2、销量5年暴增25倍的TWS耳机你买了吗?售价或会再跌20%
4、Windows重要功能被阉割,全球用户怒喷数月后微软终于悔改
5、牛逼!国产开源的远程桌面火了,只有9MB 支持自建中继器!

点分享

点收藏

点点赞

点在看
评论