
AeronCluster学习笔记-高效业务逻辑
共 4390字,需浏览 9分钟
·
2022-11-18 19:45
本文我们学习如何利用AeronCluster实现高效的业务逻辑。
正确且有效地将业务逻辑添加到 Aeron Cluster 可能是一件具有挑战性的事情,但是如果我们在使用AeronCluster的时候遵守以下规则时则会相对简单地实现高效业务逻辑:
考虑Cluster集群的有界上下文 在选择集群编解码器的时候保持谨慎 使用最合适的数据结构和技术来实现业务逻辑(这不是废话么) 将验证逻辑前置到网关 将长期运行的任务外部化(比如说,一些耗时、耗费IO资源、耗费内存资源的定时任务,从核心业务系统分离出去) 使用定时器来细粒度拆分无法外部化的长时间运行的任务,让任务不要长时间占据CPU,而是按照一定频率触发 保持系统核心链路高性能,轻量级,减少遍历等耗时逻辑,优化算法,提升性能 通过分片方式进行资源隔离,提升并发度,降低锁竞争
其中许多规则与对抗利特尔定律有关 - 请参阅性能限制 https://aeroncookbook.com/aeron-cluster/performance-limits/。
!! 利特尔法则可用于一个稳定的、非占先式的系统中。其内容为:
在一个稳定的系统(L)中,长期的平均顾客人数,等于长期的有效抵达率(λ),乘以顾客在这个系统中平均的等待时间(W);或者,我们可以用一个代数式来表达:L=λW
利特尔法则可用来确定在途存货的数量。此法则认为,系统中的平均存货等于存货单位离开系统的比率(亦即平均需求率)与存货单位在系统中平均时间的乘积。
虽然此公式看起来直觉性的合理,它依然是个非常杰出的推导结果,因为此一关系式“不受到货流程分配、服务分配、服务顺序,或任何其他因素影响”。
此一理论适用于所有系统,而且它甚至更适合用于系统中的系统。举例来说,在一间银行里,顾客等待的队伍就是一个子系统,而每一位柜员也可以被视为一个等待的子系统,而利特尔法则可以>套用到任何一个子系统,也可以套用到整个银行的等待队伍之母系统。
唯一的条件就是,这个系统必须是长期稳定的,而且不能有插队抢先的情况发生,这样才能排除换场状况的可能性,例如开业或是关厂。
我的个人理解是说,排队场景下,一个很小的延时,在大量积累之后都会导致显著的耗时,或许用长尾效应解释也比较合适。
!! 还有一个额外的且牢不可破的规则:你编写的任何业务逻辑都必须是确定性的。如果没有确定性的业务逻辑,如果集群领导者失败,你可能会面临数据丢失的窘境(因为逻辑不是确定性的,即便从崩溃中恢复也无法恢复到崩溃前的状态)。
考虑集群的有界上下文(Consider the cluster's bounded context)
来自领域驱动设计的限界上下文模式是考虑Cluster的职责和逻辑的好方法。
我们要努力将Cluster中的逻辑集中在核心系统状态上——换句话说,在Cluster集群中处理无状态逻辑几乎没有价值。(Cluster本质上是基于Raft协议实现的有状态机)
当你发现需要多个有界上下文(例如,匹配功能和结算功能),请考虑将集群拆分为两个独立的集群。(上下文隔离,领域驱动设计中的做法)
因为耦合多个上下文会引入了新的复杂性,不过这可以带来更高的性能和更容易的开发和维护过程。
对于两个Cluster集群而言,你需要通过一个集群客户端网关来访问这两个集群——这需要提前考虑协议版本控制和部署的复杂性。(很好理解,这其实是微服务的架构模式,内部多套系统,对外只有一套入口也就是这里说到的网关)。
慎重选择集群编解码器(Select the cluster codec carefully)
Aeron Cluster 使用类似洋葱的架构运行,通常有 4 层:
FIX、JSON、Protobuf、Avro 或用于外部连接的任何数据格式 外部连接是通过网关进程建立的,网关进程本质上属于集群客户端 集群客户端使用集群的内部编解码器与集群进行通讯 而在这个架构中心,则是Cluster集群本身
!! 注意: 除非通过集群客户端,否则 Aeron 集群业务逻辑不应直接与任何 I/O 交互。与往常一样,这条规则也有例外(例如日志记录、指标、可观察性等场景,就不得不避免IO交互),但条规则本身是一个指导设计的良好基准。
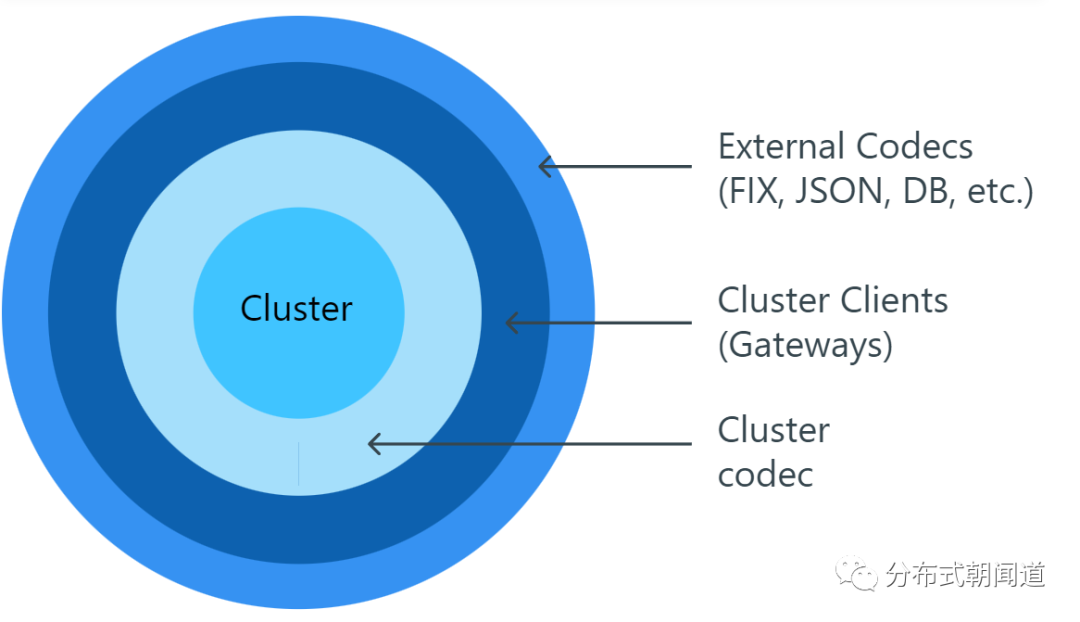
内部集群编解码器的设计和实现方式,应当保证在业务逻辑中花费最少的处理时间。
使用简单二进制编码(SBE, Simple Binary Encoding)或类似方法可以让耗时保持在一位数或两位数纳秒。
如果你在这里使用 JSON 之类的文本数据结构,即便你用的是最高效的库也仍然需要花费数百微秒来解析消息。
让我们大胆想象一下,加入我们解析一条用 JSON 格式发送的集群命令需要 600μs,那么集群吞吐量将限制在 ±1,667 个请求/秒。
如果我们使用SBE,平均在这个任务上花费 50ns,集群吞吐量将被限制在 2,000,000 个请求/秒。性能相关数据请参考 https://aeroncookbook.com/aeron-cluster/performance-limits。
使用最适合的数据结构和技术实现业务逻辑
从上文中仔细选择集群编解码器(cluster codecs)可以看出,处理命令所花费的时间对集群最大吞吐量有很大影响。
如果你选择了类似 Simple Binary Encoding 这样的编解码器,你需要仔细考虑业务逻辑在内部是如何运作的。并且你需要考虑以下问题:
考虑到命令处理的数据量,哪些数据结构最适合业务逻辑?例如,你是否使用 Maps、TreeMaps、Arrays 等? cluster集群中允许哪些数据类型?例如,频繁使用字符串会导致大量 GC。你有必要使用它们吗? 你想预先分配所有内容并使用自己管理的 DirectBuffers 吗(不出意外的话,这里是堆外内存)?还是说你信任 Java 虚拟机的 GC? 你怎么记录日志?你的日志库对性能是否有明显影响?日志记录过程会导致明显的 GC 暂停吗?
将验证逻辑前置到系统边缘(Push validation to the edges)
通过将验证前置到系统的边缘——无论是在校验命令本身是否有效以及集群的初始化数据是否合理等(参见数据库与AeronCluster https://aeroncookbook.com/aeron-cluster/databases/)方面,你的集群业务域逻辑都可以更简单,并且可能运行得更快。
验证逻辑必须首先进行,因为回滚消息的处理过程可能非常复杂 - 例如,如果你已经提交了交易请求(比如说提交了下单请求),但随后业务逻辑意识到用户资金额度不足,那么你现在必须找到 一种能够正确取消交易的方法。
如果在交易之前先进行验证,那么就可以提前消除处理复杂回滚场景的需要(其实这里说的有点多余,众所周知,业务系统中,尤其是交易系统,20%是核心业务逻辑,80%都是校验和失败处理、异常处理逻辑,这其实体现了 做设计要面向失败)。
将长期运行的任务外部化(Externalise long running tasks)
有时我们需要在集群Cluster内对数据执行复杂、耗费资源的计算过程。应当尽可能将这类型逻辑外部化,以达到保护集群,并且不影响吞吐量的目的。
这方面的技术因计算的性质而异,这里介绍一种常见的方法:提前准备计算所需的所有数据、状态的快照,并将其作为单个数据包发送到专用的业务网关。
在准备好快照后,确定版本,锁定相关状态,以便业务逻辑可以知道结果是否可以被安全地接受并在网关返回时加以应用(是不是贼像对账系统,实际上对账就是这么做的,尤其是T+1对账,都是基于确定的数据,进行聚合计算,并将结果输出)。
使用Cluster定时器来监控外部任务的运行情况——例如,设置一个定时器在500ms后过期,如果还没有收到结果,那么就重试。当结果返回后,如果版本及锁定状态都符合要求,那么就取消任何相关的计时器并将更改应用于集群状态(实际上这种方式还是比较危险并且谨慎使用,一般在核心业务系统中,对状态进行计算要么就异步化,要么就在本系统中同步进行,待结果返回之后再继续后续的流程)。
使用定时器或消息分解长时间运行的任务
如果任务必须在集群内执行,并且不能安全地发送到外部。那么在这种情况下,不要将命令作为单个长时间运行的任务来处理,而是将其进行分解。
在执行长时间运行的任务时,集群将无法处理新的命令并且延迟可能会飙升。

在集群中存储有关长进程所需的状态,并通过集群计时器以chunk(块)的形式调度任务。这将允许继续处理其他命令,并且可以降低对延迟的影响。最好在上一个处理的子任务完成后就安排下一个子任务,这个过程可以通过计时器或通过向集群发送消息来完成。
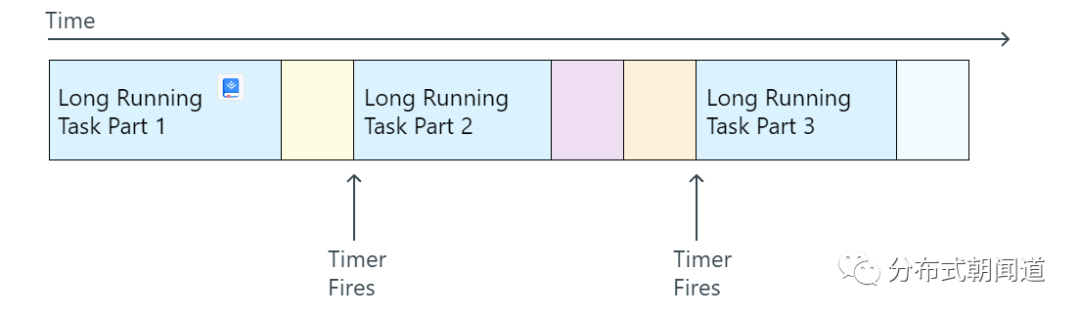
我个人理解,这里要表达的是,对长任务进行分治,拆分,进而降低长任务对CPU、内存资源的长期占用。
保持核心链路清洁(Keep the hot path clean)
当我们在 Aeron Cluster 中加入新的业务逻辑/逻辑变更时,请保持核心路径没有任何同步的任务。
例如,如果你需要进行下单交易并希望将其存储在数据库中,请不要hold集群同步进行数据库写入(禁止在cluster核心链路中进行IO操作,这将使Cluster挂起无法接受新的请求(可以类比一下Netty的线程模型,我们是不允许在Netty eventLoop中执行耗时操作的,这其实是一个道理))。
正确且推荐的做法是将持久化操作发送到可以写入数据库的网关。信任集群会保留订单状态 - 这需要保持确定性的业务逻辑这一牢不可破的规则。(在实际中,我们会将下单Log经过Cluster的Raft共识之后,通过Archive进行异步回放,从而落库。)
分片处理(Shard Processing)
https://aeroncookbook.com/aeron-cluster/on-sharding/
如果volumes(卷)和latency(延迟)需要的话,则可以对业务处理逻辑进行分片处理。
这样做需要仔细考虑你在什么维度上进行分片——例如在金融交易中,你是在合约(交易标的,如某只股票)、人(如userId)还是通过其他维度进行分片?
这个决定特定于每个实现,是一种按需采用的策略。我们需要考虑网关的设计以及分片对外部用户和系统的影响——例如,集群是否完全独立,或者网关是否需要跨集群进行通信?(这里其实是说,分片固然能够提升效率,降低延迟,但是如果涉及到数据的聚合,跨集群数据同步,分布式事务等场景,是需要好好进行设计和思考。其实就是说,软件开发领域没有银弹)
本文原文 https://aeroncookbook.com/aeron-cluster/efficient-business-logic/