
论文阅读笔记 | 目标检测算法——CenterNet算法

来源:CSDN博主「Clichong」 本文约3600字,建议阅读8分钟
本文介绍了目标检测算法的有关内容。
2.1 keypoint detection loss
2.2 offset loss
2.3 size loss
2.4 overall loss
paper:Objects as Points
Source code:
https://github.com/xingyizhou/CenterNet

CenterNet通过根据位置(peaks)分配anchor,而不是在特征图上进行密集覆盖,不需要手动的设置前景或背景的阈值。
CenterNet中的每一个对象只有一个正样本的anchor,所以不需要非极大值抑制处理,也就是不需要后处理方法,只需要提取关键点heatmap中的局部峰值。
与传统的对象检测器相比,CenterNet使用了更大的输出分辨率,这消除了对多个anchor的需要

2. Preliminary
关键点预测损失公式为:

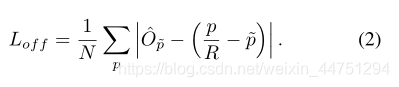
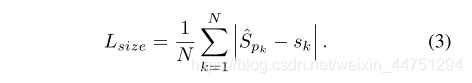

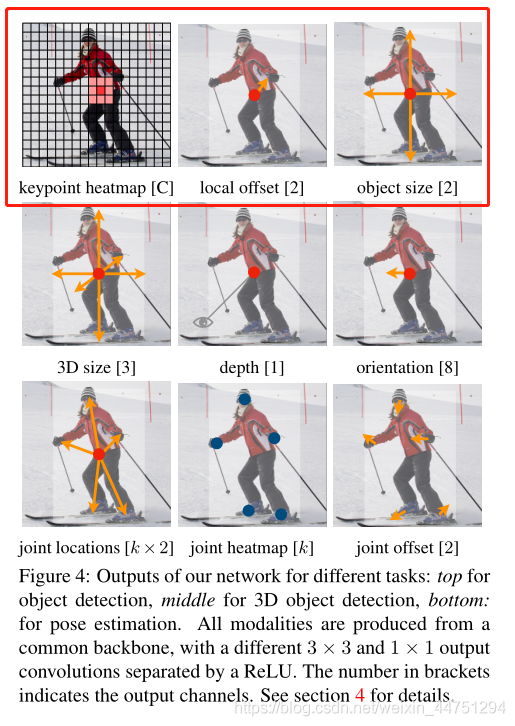
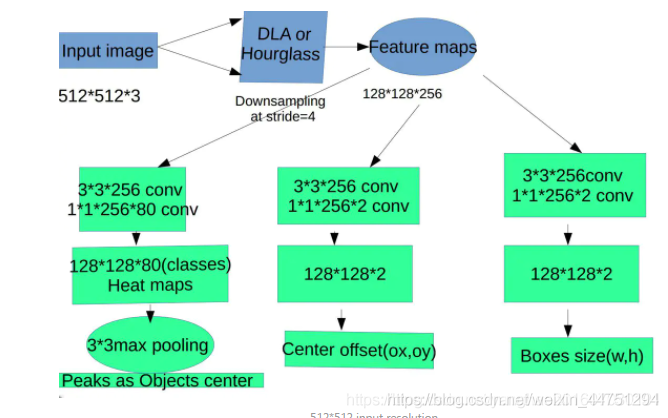
size分支用于预测宽和高,offset分支用于弥补卷积操作的下采样导致离散误差,做回归用,这两个分支与类无关,所有类共享。
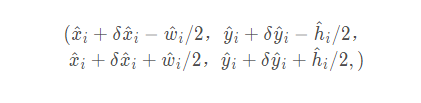
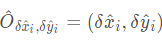 表示偏移预测量,而
表示偏移预测量,而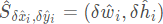 表示长宽尺度预测。
表示长宽尺度预测。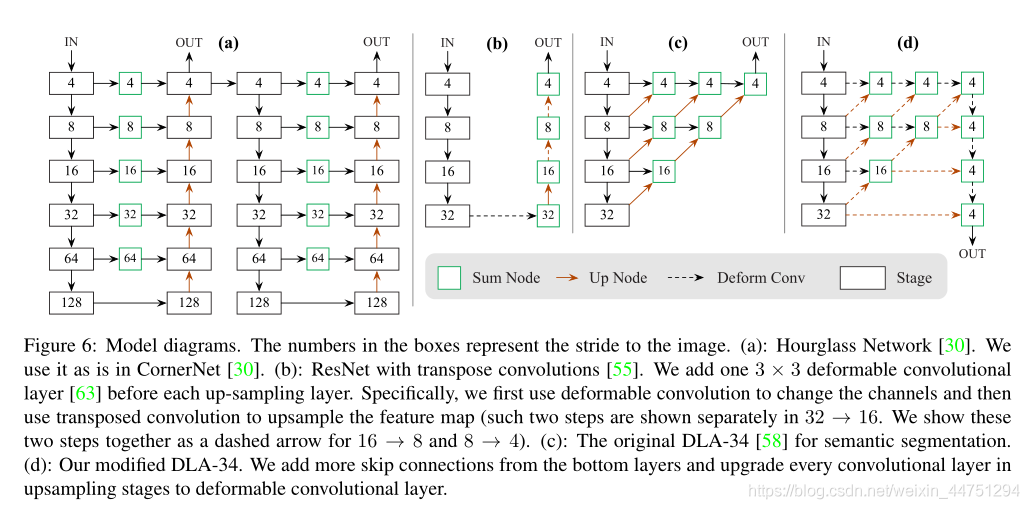
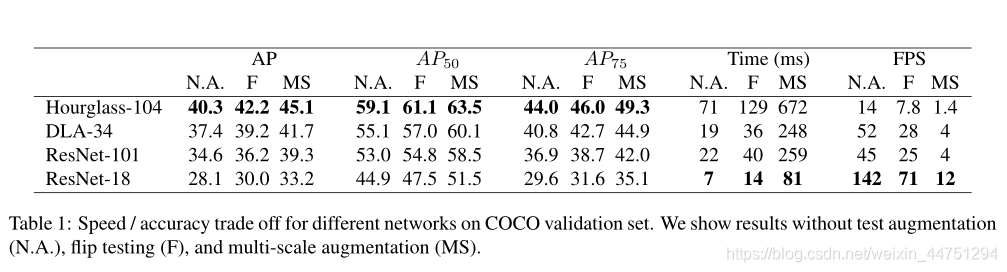
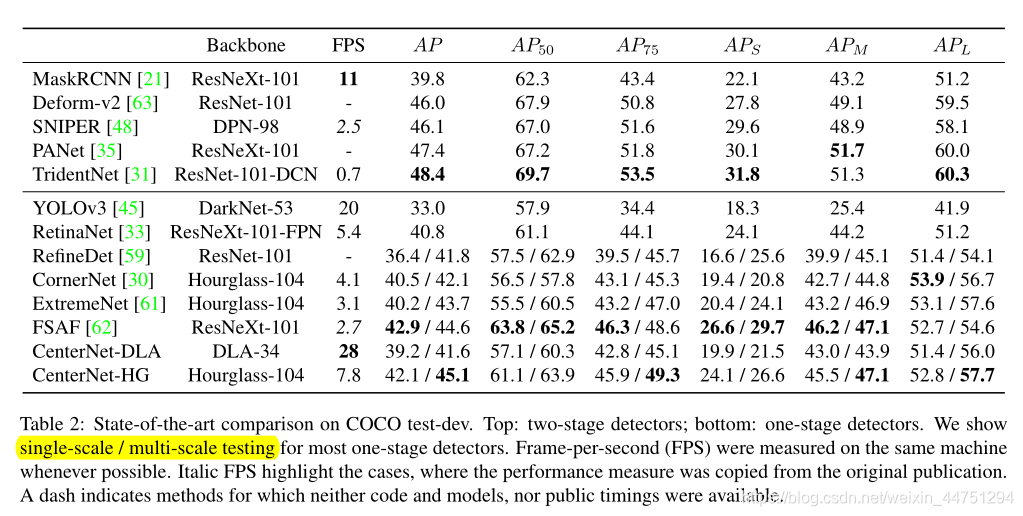
评论