
基于 eBPF 的 Kubernetes 问题排查全景图发布
DevOps技术栈
共 7958字,需浏览 16分钟
·
2022-05-28 13:47
作者:李煌东
当 Kubernetes 成为云原生事实标准,可观测性挑战随之而来
Cloud Native
当前,云原生技术以容器技术为基础,通过标准可扩展的调度、网络、存储、容器运行时接口来提供基础设施。同时,通过标准可扩展的声明式资源和控制器来提供运维能力,两层标准化推动了开发与运维关注点分离,各领域进一步提升规模化和专业化,达到成本、效率、稳定性的全面优化。

无法准确清晰了解、掌控全局的系统运行架构; 无法回答应用之间的连通性是否正确;
多语言、多网络调用协议带来埋点成本呈线性增长,且重复埋点 ROI 低,开发一般将这类需求优先级降低,但可观测数据又不得不采集。
解决思路与技术方案
Cloud Native
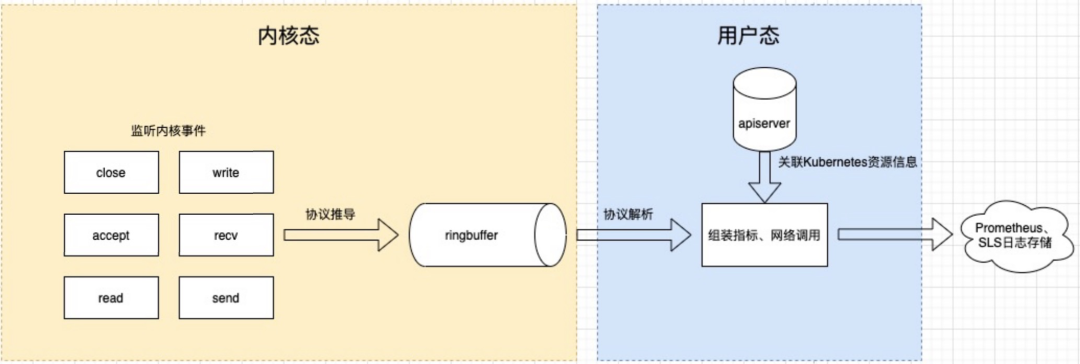
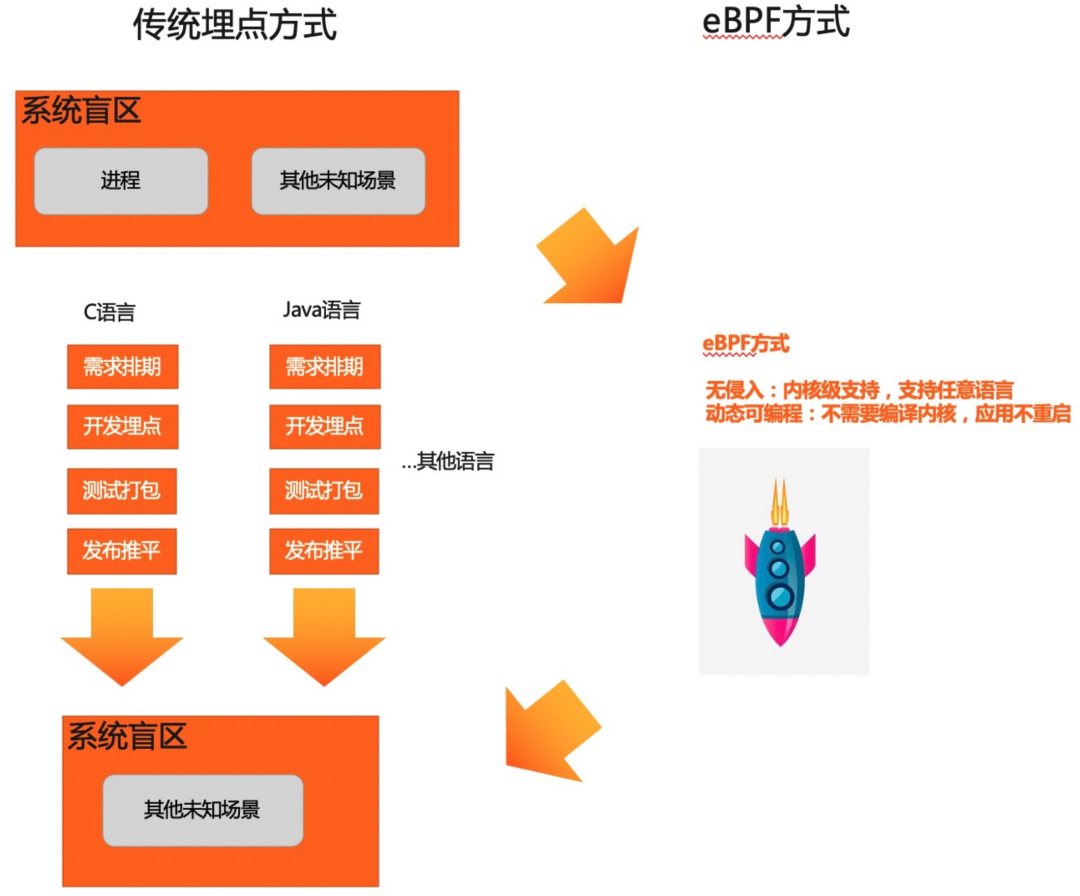
从监测系统到可观测性
Cloud Native
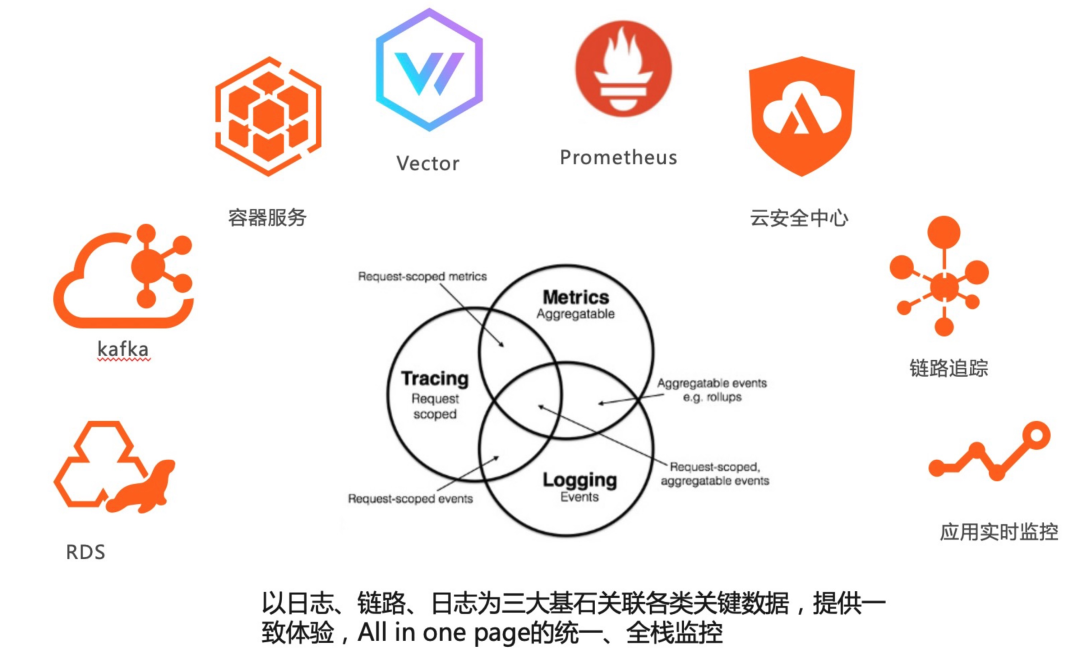
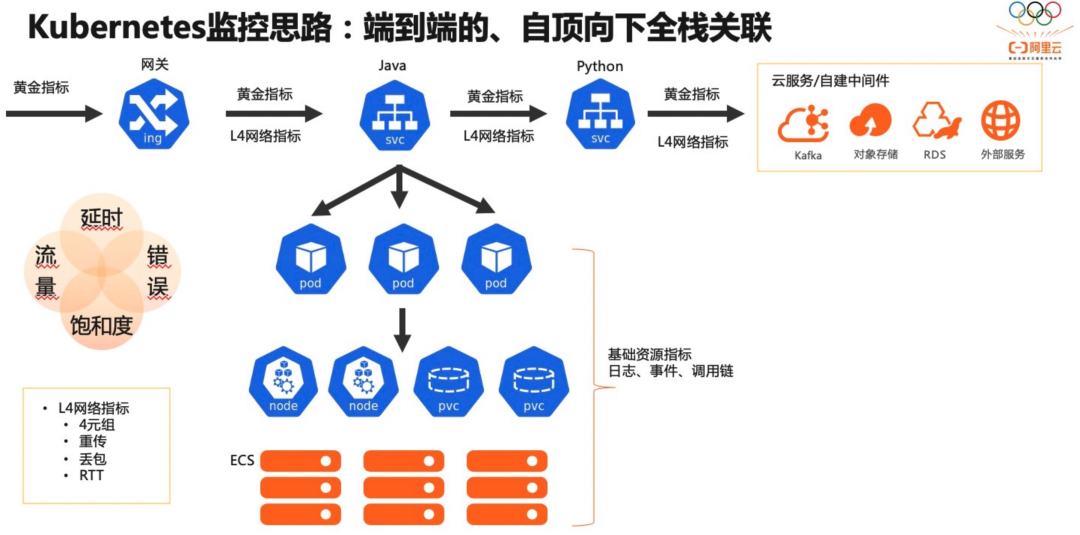
2、自顶向下全栈关联:以 Pod 为媒介,Kubernetes 层面关联 Workload、Service 等对象,基础设施层面可以关联节点、存储设备、网络等,应用层面关联日志、调用链路等。
请求数/QPS 响应时间及分位数(P50、P90、P95、P99)
错误数 慢调用数
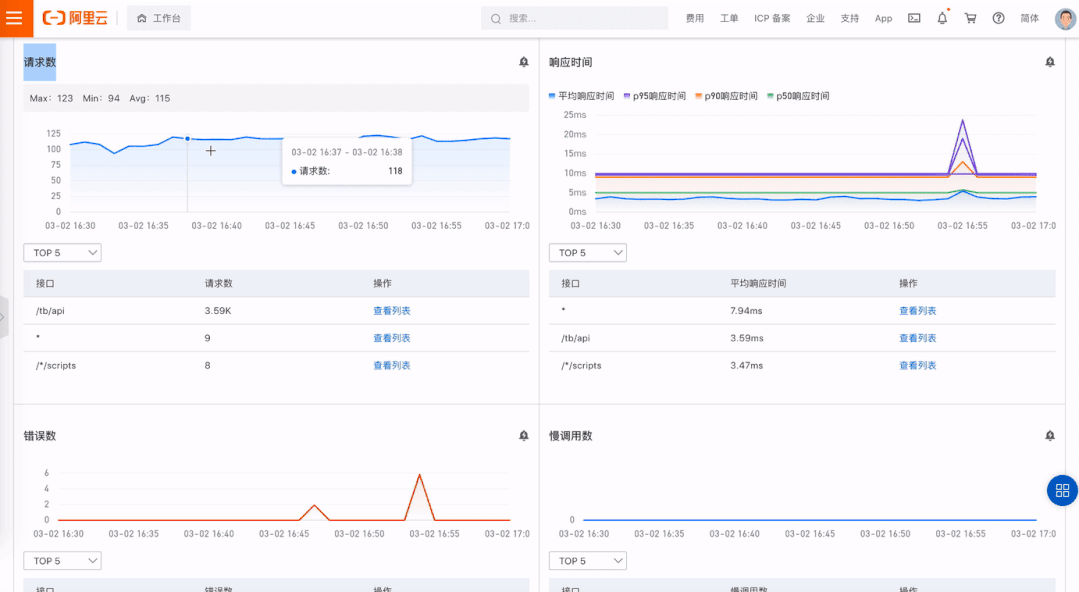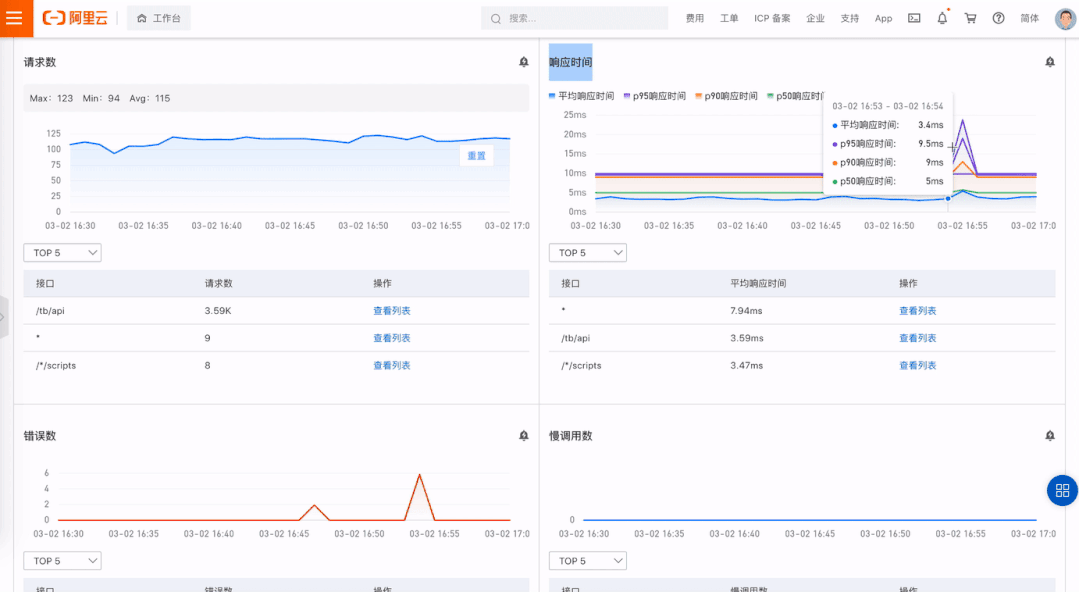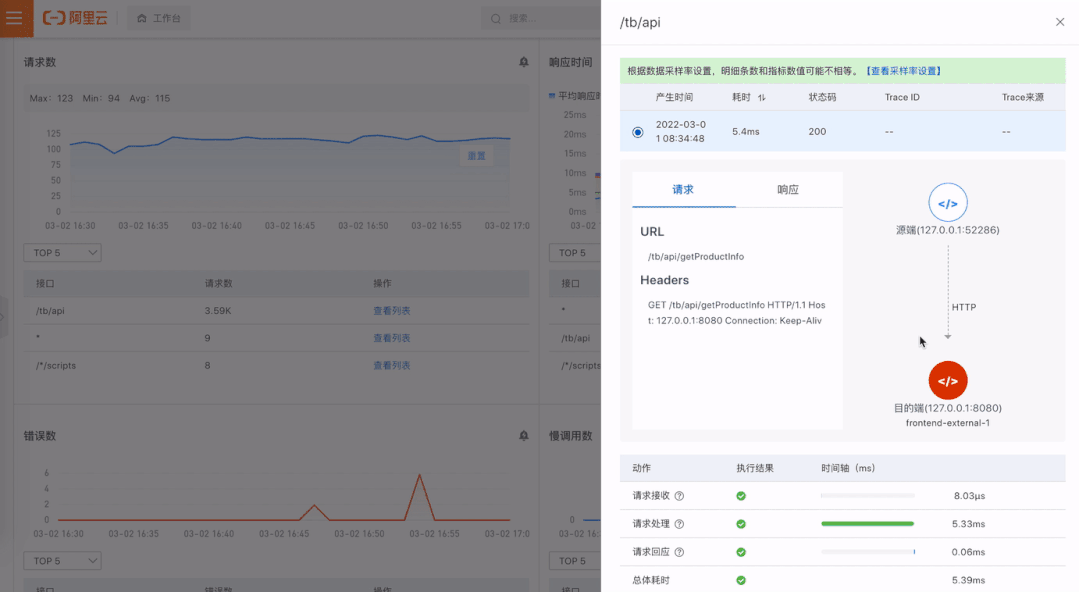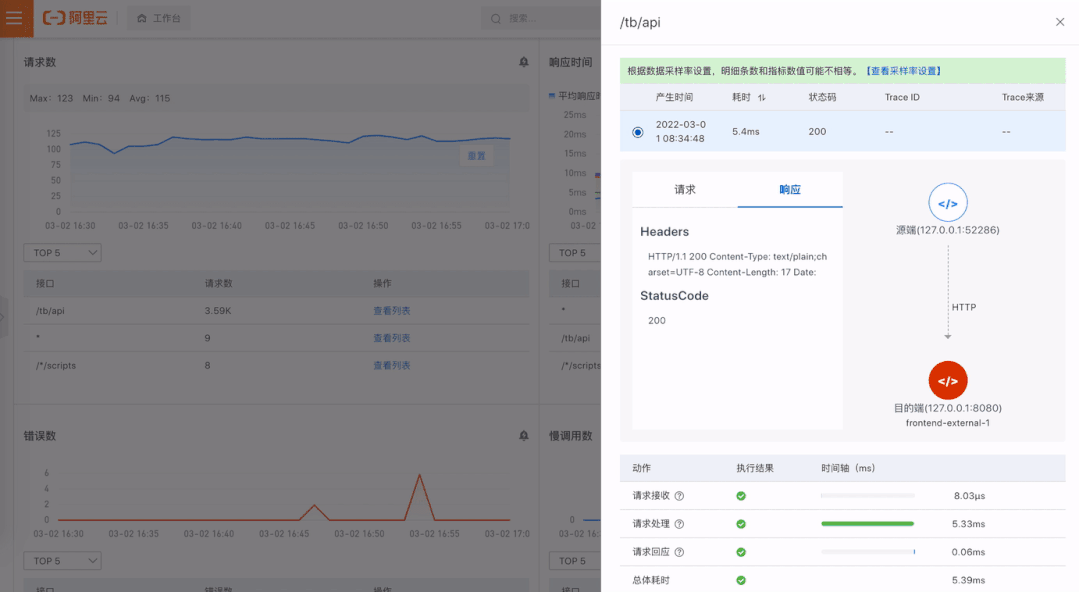
系统架构感知:系统架构图是程序员了解一个新系统的重要参考,当拿到一个系统,起码需要知晓流量入口在哪里,有哪些核心模块,依赖了哪些内部外部组件等。在异常定位过程中,有一张全局架构的图对异常定位进程有非常大推动作用。
依赖分析:有一些问题是出现在下游依赖,如果这个依赖不是自己团队维护就会比较麻烦,当自己系统和下游系统没有足够的可观测性的时候就更麻烦了,这种情况下就很难跟依赖的维护者讲清楚问题。在我们的拓扑中,通过将黄金指标的上下游用调用关系连起来,形成了一张调用图。边作为依赖的可视化,能查看对应调用的黄金信号。有了黄金信号就能快速地分析下游依赖是否存在问题。
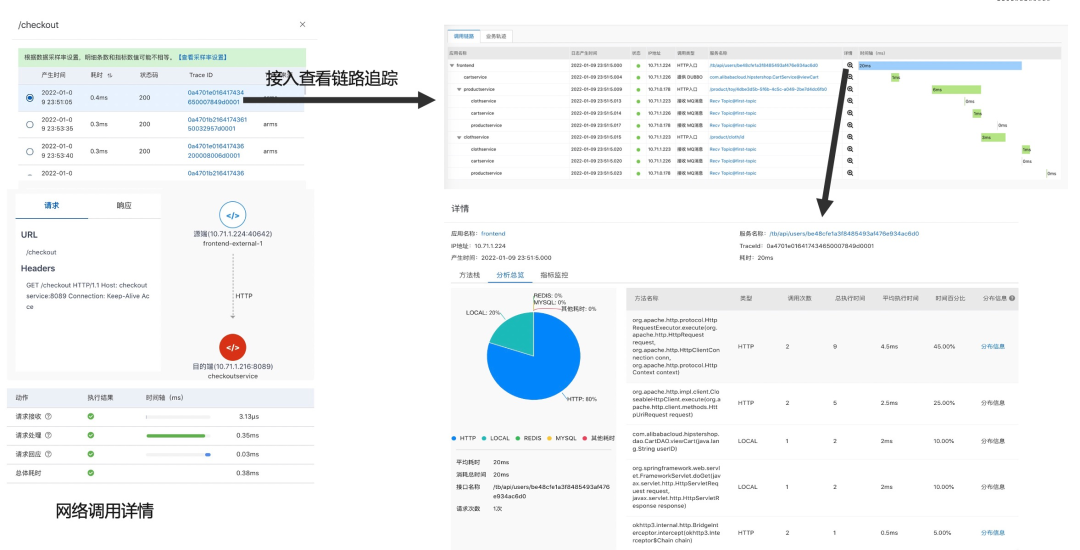
负载均衡无法访问某个 Pod,这个 Pod 上的流量为 0,需要确定是否这个 Pod 网络有问题,还是负载均衡配置有问题;
某个节点上的应用似乎性能都很差,需要确定是否节点网络有问题,通过对别的节点网络来达到;
链路上出现丢包,但不确定发生在那一层,可以通过节点、Pod、容器这样的顺序来排查。
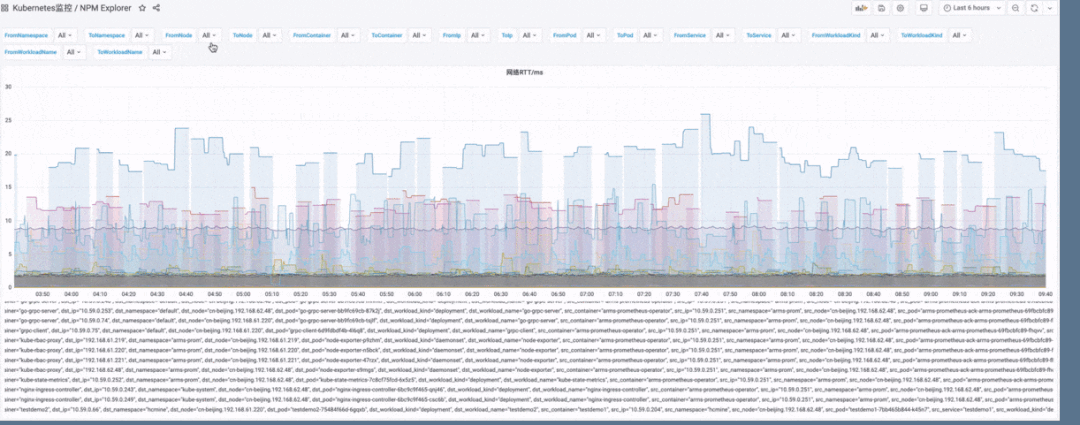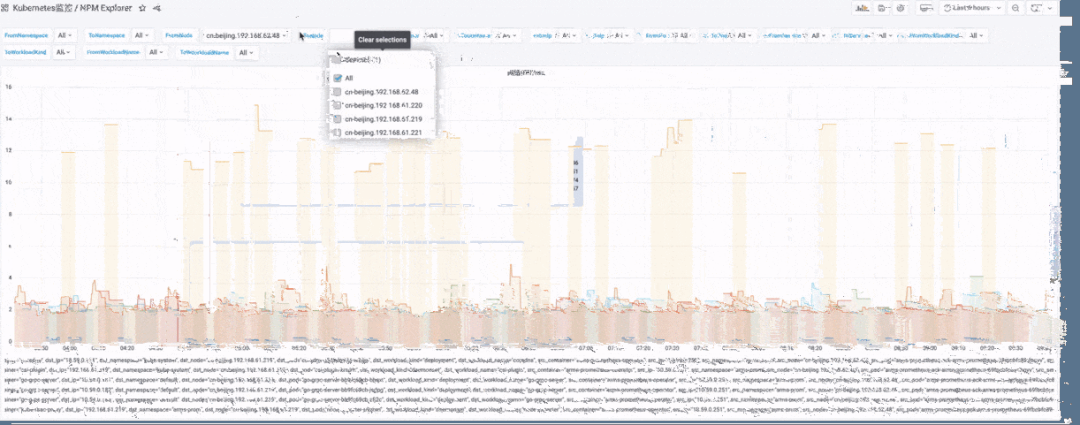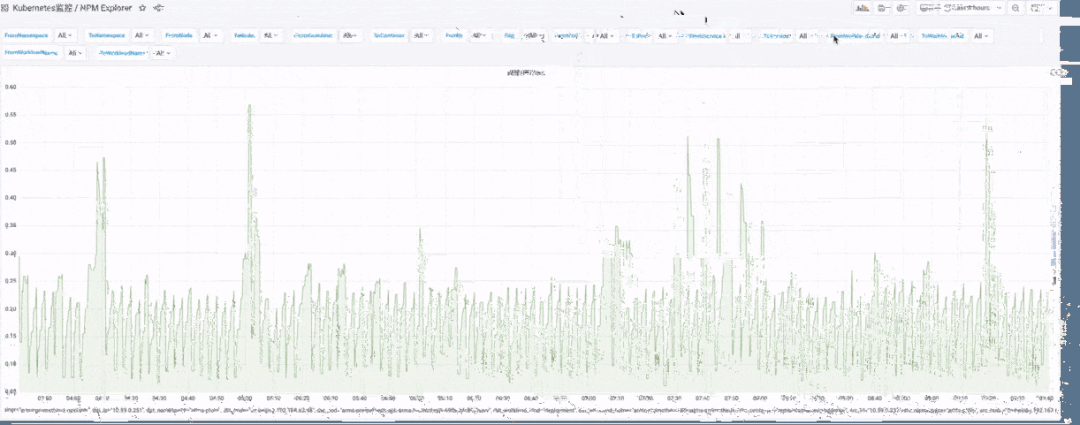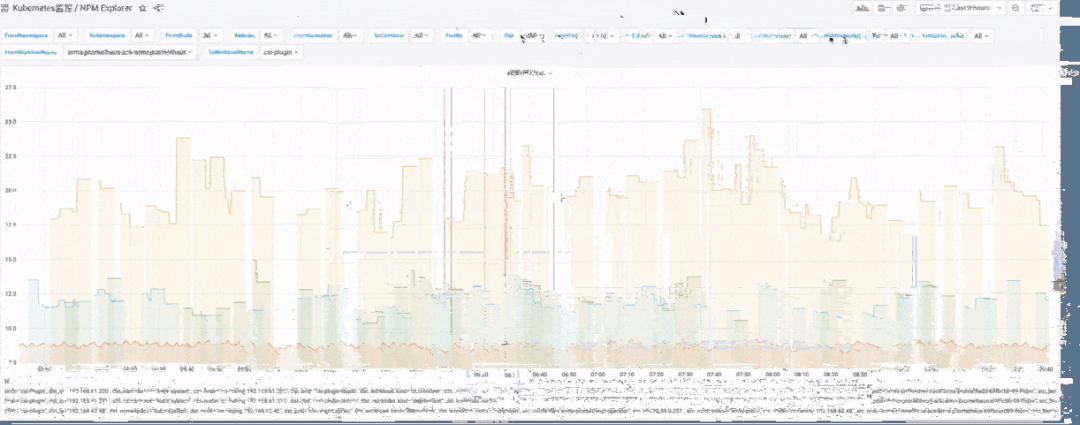
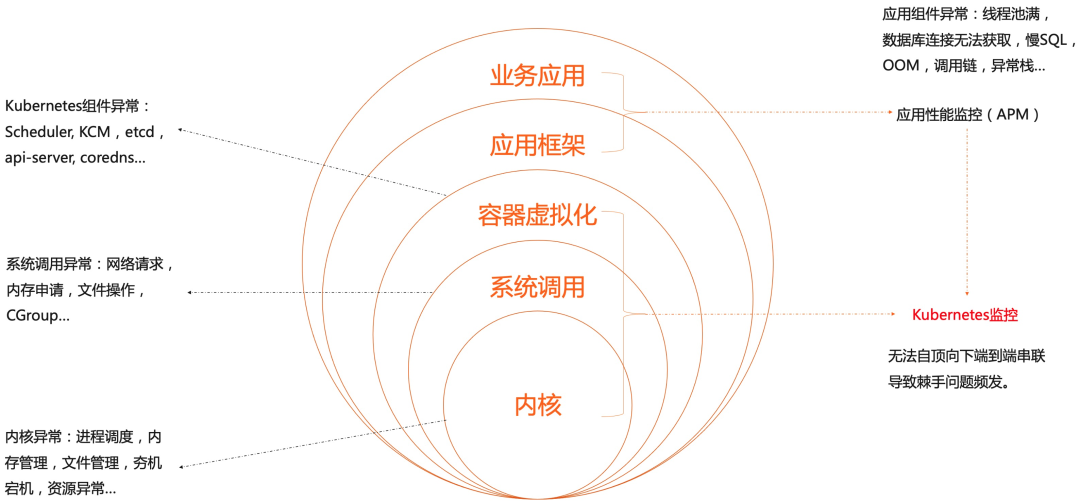
Kubernetes 可观测性全景视角
Cloud Native
大体结构上是以服务和 Deployment(应用)为入口,大多数开发只需要关注这一层就行了。重点关注服务和应用是否错慢,服务是否连通,副本数是否符合预期等
再往下一层是提供真正工作负载能力的 Pod。Pod 重点关注是否有错慢请求,是否健康,资源是否充裕,下游依赖是否健康等
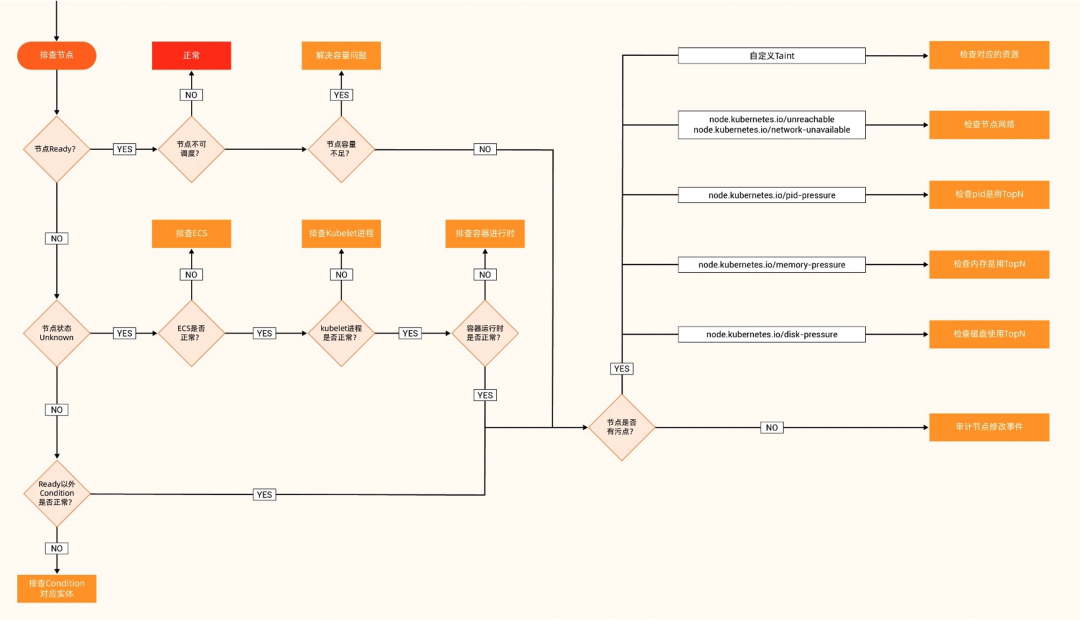
最底下一层是节点,节点为 Pod 和服务提供运行环境和资源。重点关注节点是否健康,是否处于可调度状态,资源是否充裕等。
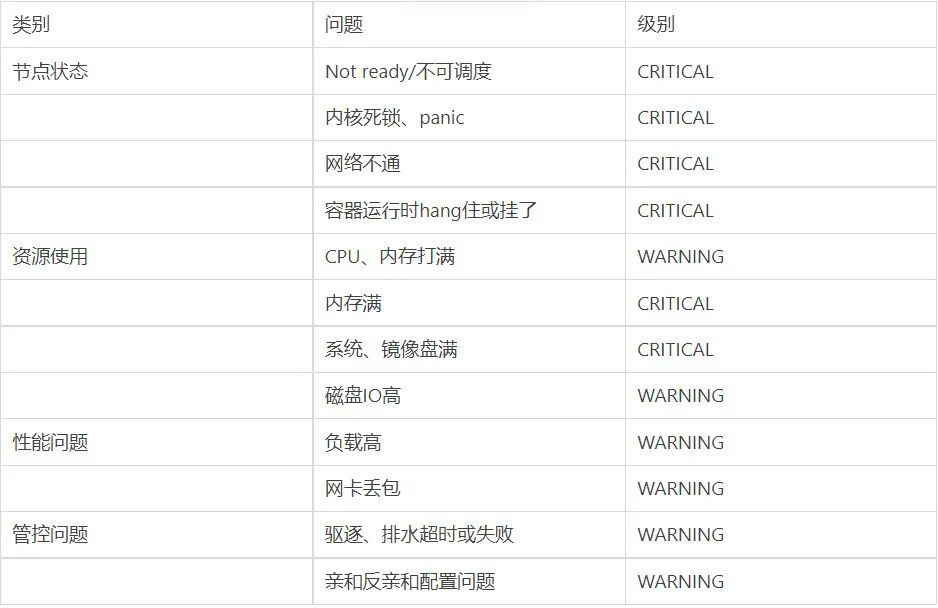
Kubernetes 的网络架构复杂度高,节点、Pod、容器、服务、VPC 交相辉映,简直能让你眼花缭乱; 网络问题排查需要一定的专业知识,大多数对网络问题都有种天生的恐惧; 分布式 8 大谬误告诉我们网络不是稳定的、网络拓扑也不一成不变的、延时不可忽视,造成了端到端之间的网络拓扑不确定性。
conntrack 记录满问题; IP 冲突;
CoreDNS 解析慢、解析失败; 节点没开外网。(对,你没听错);
服务访问不通; 配置问题(LoadBalance 配置、路由配置、device 配置、网卡配置);
网络中断造成整个服务不可用。
网络流量和带宽; 丢包数(率)和重传数(率);
RTT。
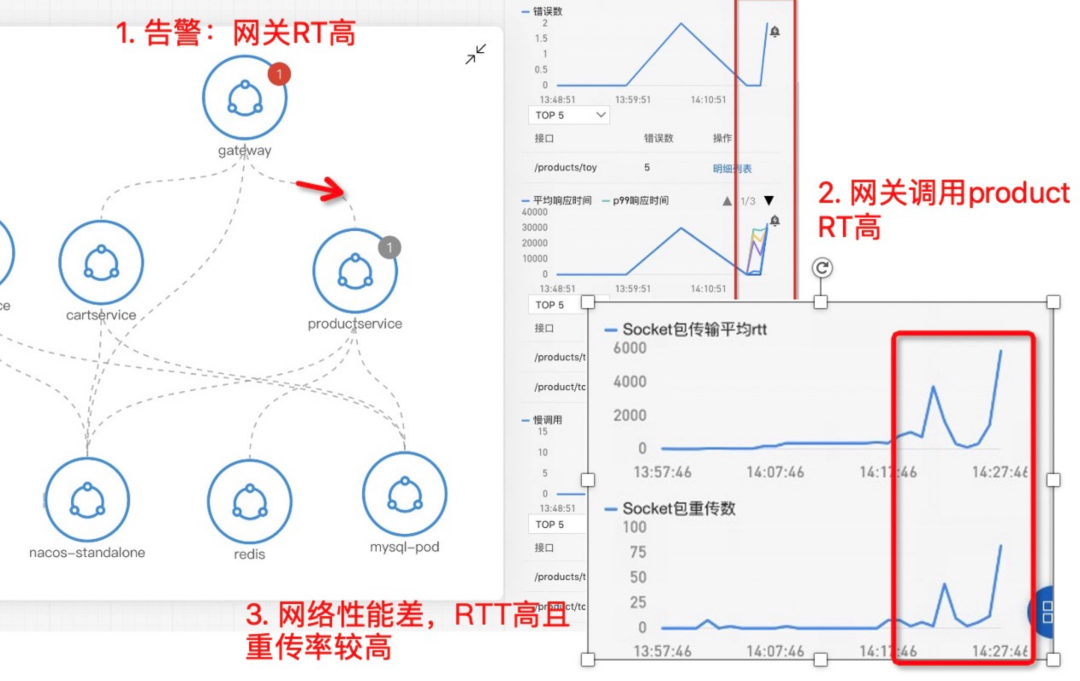


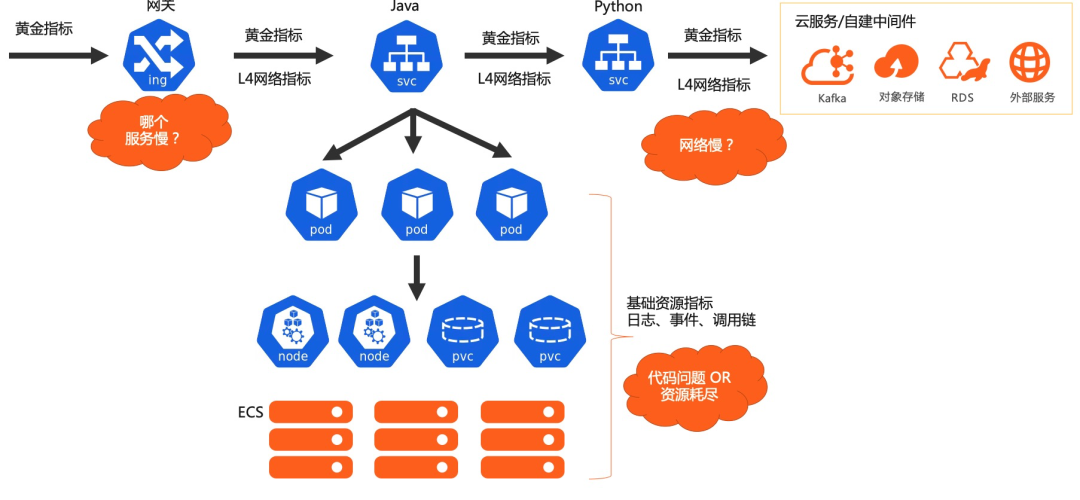
横向:主要是端到端层面来看,首先看自己服务的黄金指标是否有问题,再逐步看下游的网络指标。注意如果从客户端来看调用下游耗时高,但从下游本身的黄金指标来看是正常的,这时候非常有可能是网络问题或者操作系统层面的问题,此时可以用网络性能指标(流量、丢包、重传、RTT 等)来确定。
纵向:确定应用本身对外的延时高了,下一步就是确定具体哪个原因了,确定哪一步/哪个方法慢可以用火焰图来看。如果代码没有问题,那么可能执行代码的环境是有问题的,这时可以查看系统的 CPU/Memory 等资源是否有问题来做进一步排查。
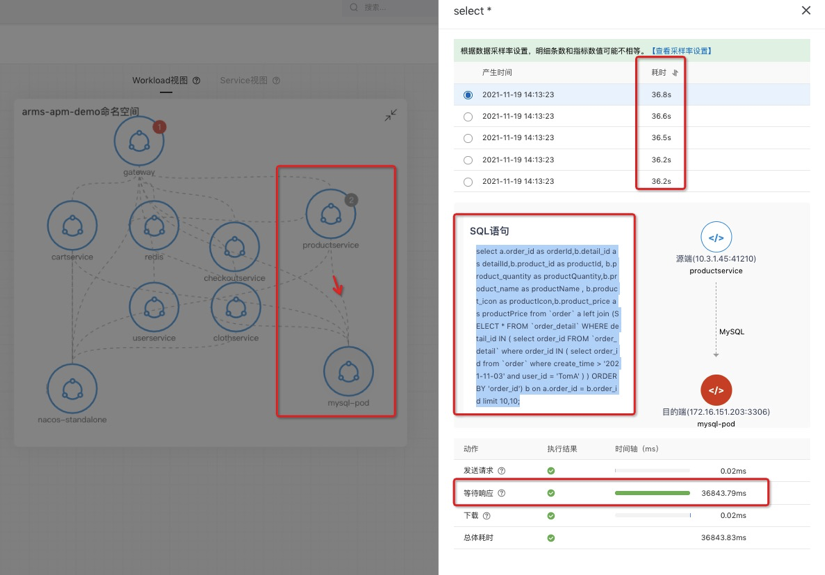
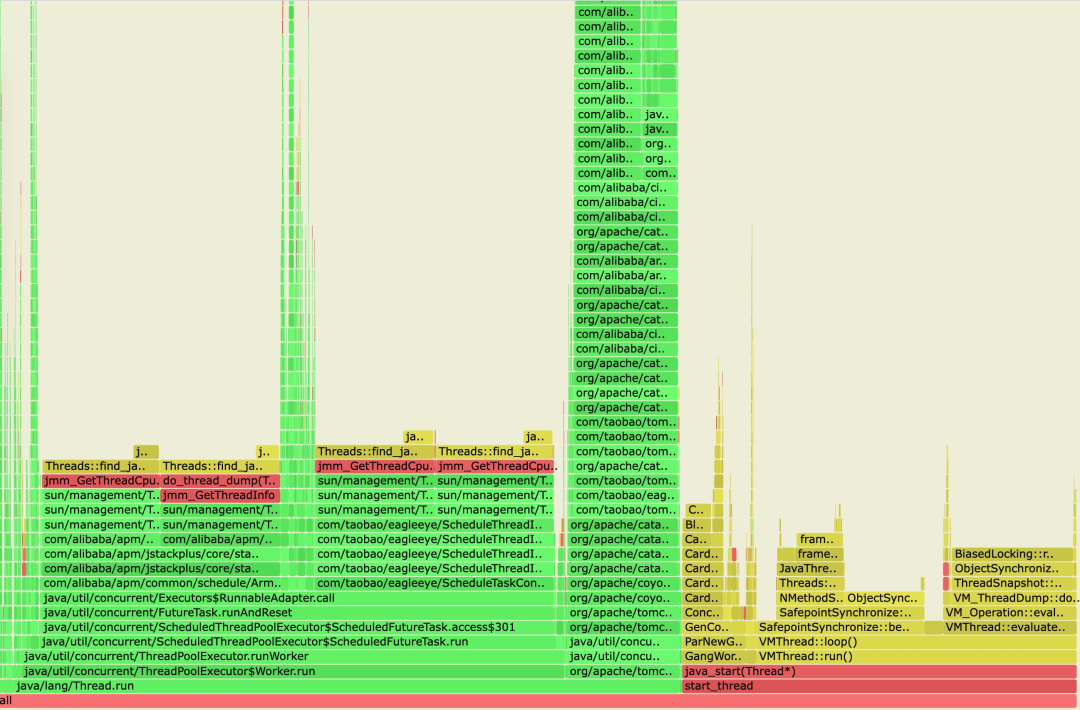
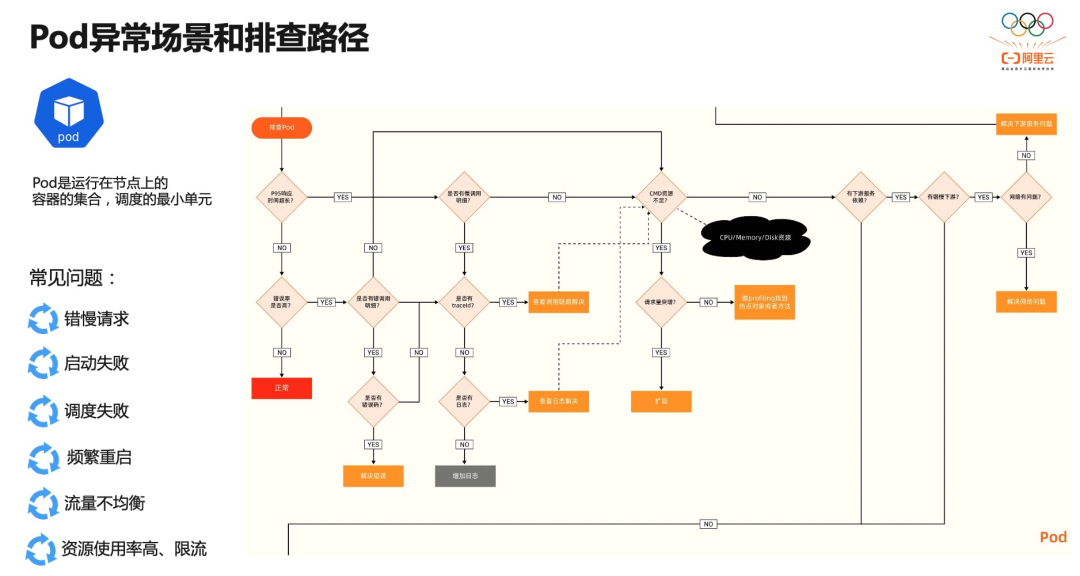
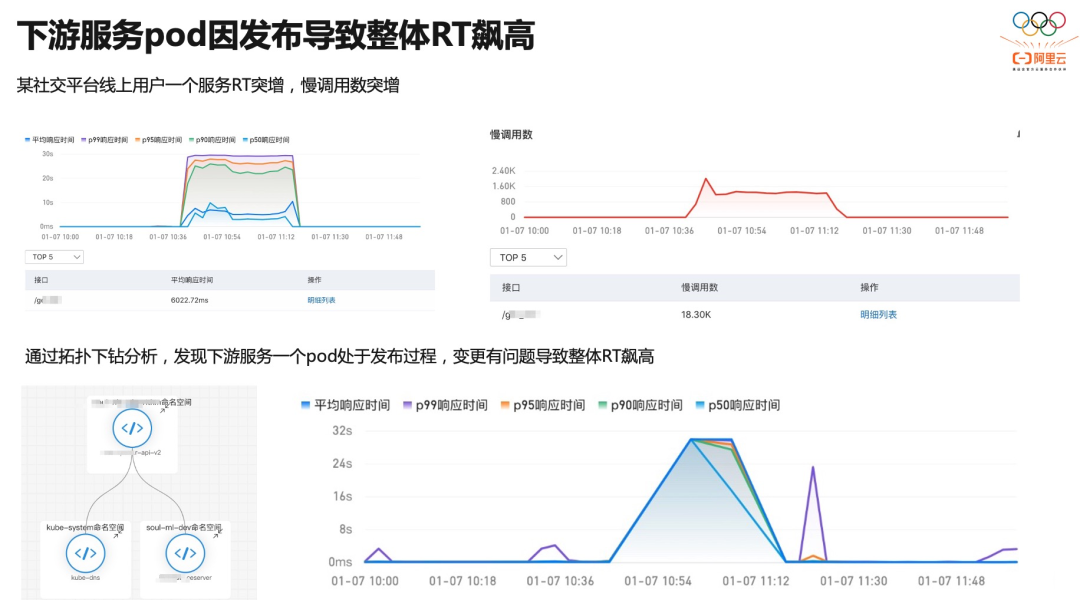
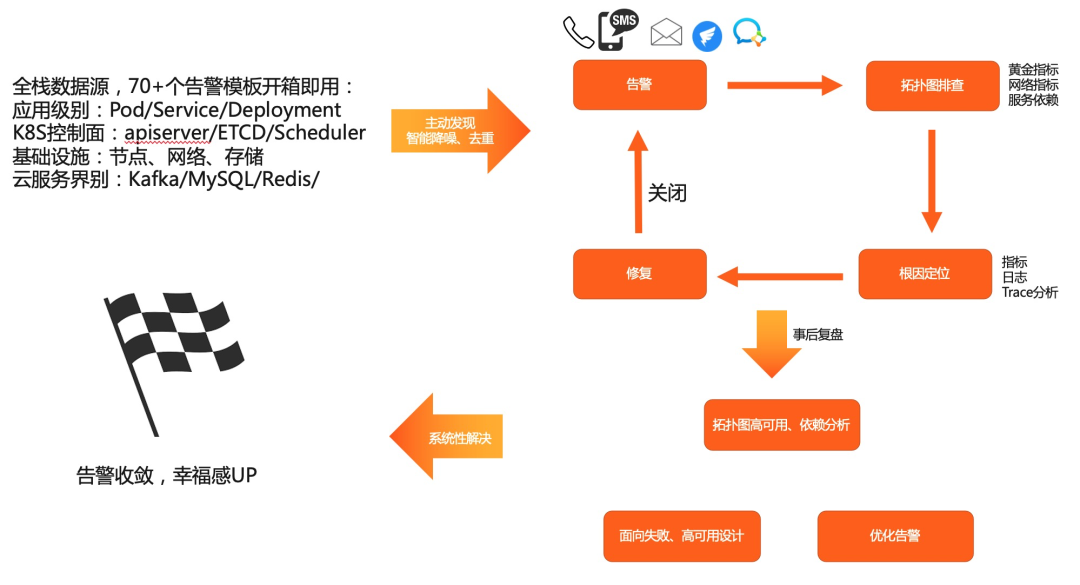
总结
Cloud Native
- END - 推荐阅读 31天拿下K8s含金量最高的CKA+CKS证书! 一文掌握 Ansible 自动化运维 Linux 使用 Systemd 管理进程服务,划重点~ Linux的10个最危险命令 Kubernetes网络难懂?可能是没看到这篇文章 100个Linux Shell脚本经典案例(附PDF) 24 个 Docker 常见问题处理技巧 23 款 DevOps 工具建设云原生时代 Shell分析日志文件,全面解锁新姿势! 这篇文章带你全面掌握 Nginx ! 一文搞懂 Kubernetes 网络通信原理 SRE本质就是一个懂运维的资深开发 Kubernetes 4000节点运维经验分享 Kubernetes 的高级部署策略,你不一定知道! 基于Nginx实现灰度发布与AB测试 搭建一套完整的企业级 K8s 集群(kubeadm方式) 点亮,服务器三年不宕机


评论